Cómo transferir archivos a través de REST para almacenarlos en una propiedad. Parte 3
En la primera parte de esta serie de artículos hablamos sobre cómo leer un gran fragmento de datos del cuerpo sin procesar de un método HTTP POST y guardarlo en una base de datos como una propiedad stream de una clase. En la segunda parte comentamos cómo enviar archivos y sus nombres envueltos en un formato JSON.
Ahora analizaremos más de cerca la idea de enviar al servidor grandes archivos por partes. Para ello, podemos utilizar varios enfoques. En este artículo se analiza el uso del encabezado Transfer-Encoding para indicar una transferencia fragmentada. La especificación HTTP/1.1 introdujo el encabezado Transfer-Encoding, y la sección 4.1 RFC 7230 lo describió, pero está ausente en la especificación HTTP/2.
Encabezado Transfer-Encoding
El objetivo del encabezado Transfer-Encoding es especificar la forma de codificación utilizada para transferir el cuerpo del mensaje (payload) al usuario de forma segura. Este encabezado se utiliza principalmente para delimitar de manera precisa una información (payload) generada de forma dinámica y para distinguir las codificaciones de información (payloads) realizadas por razones de eficiencia o seguridad del transporte de las características del recurso seleccionado.
Se pueden utilizar los siguientes valores en este encabezado:
- Chunked
- Compress
- Deflate
- gzip
Transfer-Encoding es igual a Chunked
Cuando se establece la codificación de transferencia como fragmentada (chunked), el cuerpo del mensaje consistirá en un número indeterminado de fragmentos regulares, un fragmento de terminación, una parte terminal (trailer) y una secuencia final de salto de línea y retorno de carro (CRLF).
Cada parte empieza con un tamaño de fragmento representado por un número hexadecimal seguido de una extensión opcional y CRLF. Después, aparece el cuerpo del fragmento con CRLF al final del mismo. Las extensiones contienen los metadatos del fragmento. Por ejemplo, los metadatos podrían incluir una firma, una almohadilla, información de control a mitad del mensaje, etc. El fragmento de terminación es un fragmento regular de longitud cero. Una parte terminal, que consiste en campos del encabezado (posiblemente vacíos), sigue al fragmento de terminación.
Para que todo resulte más fácil de imaginar, esta es la estructura de un mensaje con Transfer-Encoding = chunked:
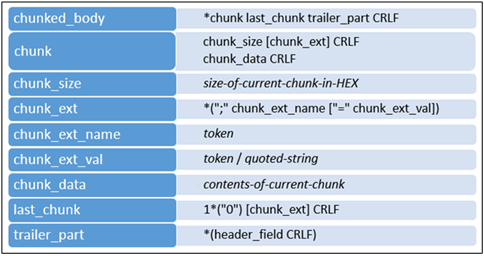
Este es el ejemplo de un mensaje corto fragmentado:
13\r\n
Transferring Files \r\n
4\r\n
on\r\n
1A\r\n
community.intersystems.com
0\r\n
\r\n Este cuerpo del mensaje consiste en tres fragmentos significativos. El primer fragmento tiene una longitud de diecinueve octetos, el segundo de cuatro y el tercero de veintiséis. Se puede ver que los CRLFs finales que indican los extremos de los fragmentos no cuentan para el tamaño del fragmento. Pero, si se utiliza CRLF como marcador del final de la línea (EOL), entonces el CRLF sí cuenta como parte de un mensaje y ocupa dos octetos. El mensaje descifrado se ve así:
Transferring Files on
community.intersystems.com Elaboración de mensajes fragmentados en IRIS
Para este tutorial, utilizaremos el método en el servidor que se creó en el primer artículo. Esto significa que enviaremos el contenido del archivo directamente al cuerpo del método POST. Como enviaremos el contenido del archivo en el cuerpo, enviamos el POST a http://webserver/RestTransfer/file.
Ahora, veamos cómo podemos formar en IRIS un mensaje fragmentado. Como se especifica en Envío de solicitudes HTTP, en la sección Envío de una solicitud en fragmentos, se puede enviar una solicitud HTTP en fragmentos si se utiliza HTTP/1.1. La mejor parte de este proceso es que %Net.HttpRequest calcula automáticamente la longitud del contenido de todo el cuerpo del mensaje en el lado del servidor, por lo que no es necesario cambiar el lado del servidor en absoluto. Por lo tanto, para enviar una solicitud en fragmentos, hay seguir estos pasos únicamente en el cliente.
El primer paso es crear una subclase de %Net.ChunkedWriter e implementar el método OutputStream. Este método debería obtener un stream de datos, examinarlo, decidir si lo divide en partes o no, cómo dividirlo, e invocar los métodos heredados de la clase para escribir la salida. En nuestro caso, llamaremos a la clase RestTransfer.ChunkedWriter.
A continuación, en el método del lado del cliente responsable de enviar los datos (llamado aquí "SendFileChunked"), hay que crear una instancia de la clase RestTransfer.ChunkedWriter y rellenarla con los datos solicitados que se quieren enviar. Como vamos a enviar archivos, haremos todo el trabajo difícil en la clase RestTransfer.ChunkedWriter. Añadimos una propiedad llamada Filename As %String y un parámetro llamado "MAXSIZEOFCHUNK = 10000". Por supuesto, se puede decidir establecer un tamaño máximo permitido para el fragmento como una propiedad y definirlo para cada archivo o mensaje.
Por último, hay que establecer la propiedad EntityBody de %Net.HttpRequest para que sea igual a la instancia creada de la clase RestTransfer.ChunkedWriter y estará listo.
Los siguientes pasos solo son el nuevo código que hay que escribir y reemplazar en vuestros métodos actuales que envía archivos a un servidor.
El método se ve así:
ClassMethod SendFileChunked(aFileName) As %Status
{
Set sc = $$$OK
Set request = ..GetLink()
set cw = ##class(RestTransfer.ChunkedWriter).%New()
set cw.Filename = aFileName
set request.EntityBody = cw
set sc = request.Post("/RestTransfer/file")
Quit:$System.Status.IsError(sc) sc
Set response=request.HttpResponse
do response.OutputToDevice()
Quit sc
} La clase %Net.ChunkedWriter es una clase stream abstracta, que proporciona una interfaz y tiene algunos métodos y propiedades implementados. Aquí, utilizamos la siguiente propiedad y métodos:
- La propiedad TranslateTable as %String fuerza la traducción automática de los fragmentos cuando se escriben en el stream de salida (EntityBody). Esperamos recibir datos sin procesar, por lo que debemos establecer TranslateTable como "RAW".
- El método OutputStream es un método abstracto sobrescrito por una subclase para realizar todo el proceso de fragmentación.
- El método WriteSingleChunk(buffer As %String) escribe el encabezado HTTP Content-Length seguido del entity-body como un solo fragmento. Verificamos si el tamaño del archivo es menor que el método MAXSIZEOFCHUNK, en cuyo caso, utilizaremos este método.
- El método WriteFirstChunk(buffer As %String) escribe el encabezado Transfer-Encoding seguido del primer fragmento. Siempre debe estar presente. A continuación puede haber cero o más llamadas para escribir más fragmentos, a lo que sigue una llamada obligatoria para escribir el último fragmento con la cadena de caracteres vacía. Verificamos que la longitud del archivo es mayor que el método MAXSIZEOFCHUNK y llamamos a este método.
- El método WriteChunk(buffer As %String) escribe los fragmentos resultantes. Verificamos si el resto del archivo después del primer fragmento sigue siendo mayor que MAXSIZEOFCHUNK y después utilizamos este método para enviar los datos. Seguimos haciéndolo hasta que el tamaño de la última parte del archivo sea inferior a MAXSIZEOFCHUNK.
- El método WriteLastChunk(buffer As %String) escribe el último fragmento seguido de un fragmento de longitud cero para marcar el final de los datos.
Basándonos en todo lo anterior, nuestra clase RestTransfer.ChunkedWriter tiene el siguiente aspecto:
Class RestTransfer.ChunkedWriter Extends %Net.ChunkedWriter
{
Parameter MAXSIZEOFCHUNK = 10000;
Property Filename As %String;
Method OutputStream()
{
set ..TranslateTable = "RAW"
set cTime = $zdatetime($Now(), 8, 1)
set fStream = ##class(%Stream.FileBinary).%New()
set fStream.Filename = ..Filename
set size = fStream.Size
if size < ..#MAXSIZEOFCHUNK {
set buf = fStream.Read(.size, .st)
if $$$ISERR(st)
{
THROW st
} else {
set ^log(cTime, ..Filename) = size
do ..WriteSingleChunk(buf)
}
} else {
set ^log(cTime, ..Filename, 0) = size
set len = ..#MAXSIZEOFCHUNK
set buf = fStream.Read(.len, .st)
if $$$ISERR(st)
{
THROW st
} else {
set ^log(cTime, ..Filename, 1) = len
do ..WriteFirstChunk(buf)
}
set i = 2
While 'fStream.AtEnd {
set len = ..#MAXSIZEOFCHUNK
set temp = fStream.Read(.len, .sc)
if len<..#MAXSIZEOFCHUNK
{
do ..WriteLastChunk(temp)
} else {
do ..WriteChunk(temp)
}
set ^log(cTime, ..Filename, i) = len
set i = $increment(i)
}
}
}
} Para ver cómo estos métodos dividen el archivo en partes, añadimos un ^log global con la siguiente estructura:
//for transfer in a single chunk
^log(time, filename) = size_of_the_file
//for transfer in several chunks
^log(time, filename, 0) = size_of_the_file
^log(time, filename, idx) = size_of_the_idx’s_chunk Ahora que el programa está completo, veamos cómo funcionan los tres enfoques para distintos archivos. Escribimos un método de clase simple para hacer llamadas al servidor:
ClassMethod Run()
{
// First, I am deleting globals.
kill ^RestTransfer.FileDescD
kill ^RestTransfer.FileDescS
// Then I form a list of files I want to send
for filename = "D:\Downloads\wiresharkOutput.txt", // 856 bytes
"D:\Downloads\wiresharkOutput.pdf", // 60 134 bytes
"D:\Downloads\Wireshark-win64-3.4.7.exe", // 71 354 272 bytes
"D:\Downloads\IRIS_Community-2021.1.0.215.0-win_x64.exe" //542 370 224 bytes
{
write !, !, filename, !, !
// And call all three methods of sending data to server side.
set resp1=##class(RestTransfer.Client).SendFileChunked(filename)
if $$$ISERR(resp1) do $System.OBJ.DisplayError(resp1)
set resp1=##class(RestTransfer.Client).SendFile(filename)
if $$$ISERR(resp1) do $System.OBJ.DisplayError(resp1)
set resp1=##class(RestTransfer.Client).SendFileDirect(filename)
if $$$ISERR(resp1) do $System.OBJ.DisplayError(resp1)
}
} Después de ejecutar el método de clase Run, en la salida de los tres primeros archivos, el estado fue ok. Pero para el último archivo, mientras que la primera y la última llamada funcionaron, la intermedia devolvió un error: 5922, Tiempo de espera agotado esperando respuesta. Si observamos nuestro método de globals, vemos que el código no guardó el undécimo archivo. Esto significa que ##class(RestTransfer.Client).SendFile(filename) falló. O, para ser precisos, el método que descomprime los datos desde JSON, no funcionó.
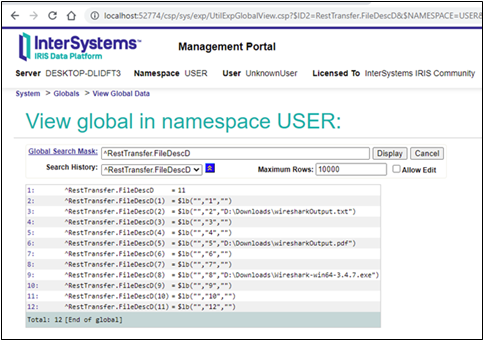
Ahora, si observamos nuestros streams, vemos que todos los archivos guardados correctamente tienen los tamaños apropiados.
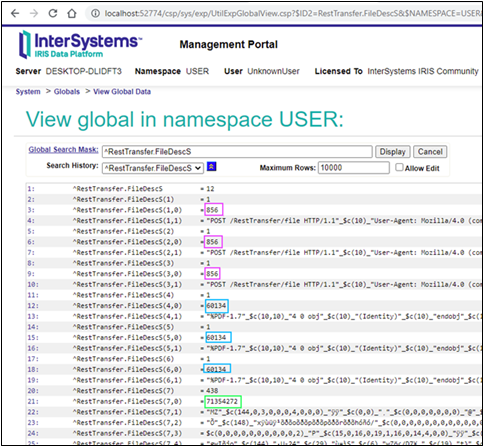
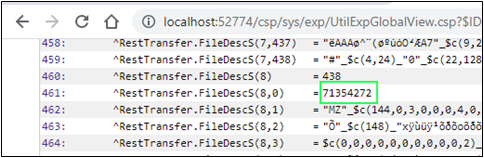
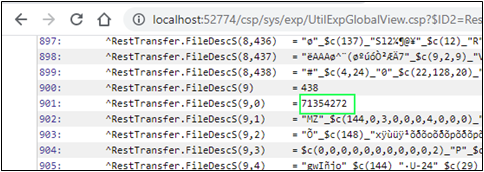
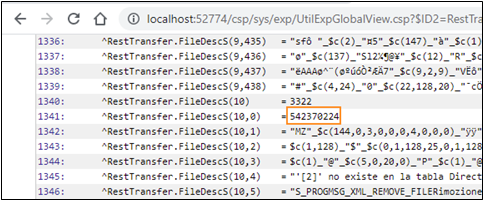
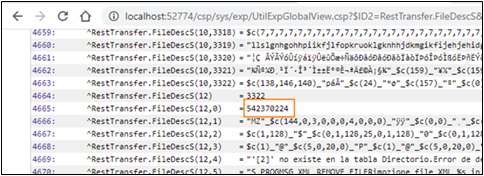
Si consultamos el ^log global, veremos cuántos fragmentos creó el código para cada archivo:
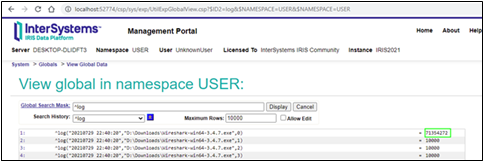
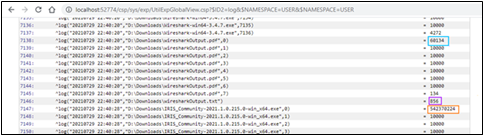
Probablemente os gustaría ver los cuerpos de los mensajes reales. Eduard Lebedyuk sugirió en el artículo Depuración Web que es posible utilizar el logging y traza del CSP Gateway.
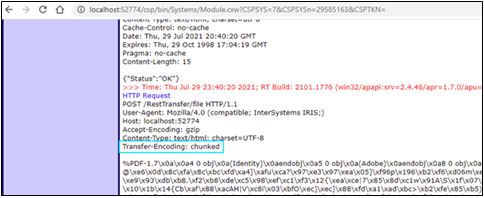
Si consultamos el registro de eventos (Event log) del segundo archivo fragmentado, veremos que el valor del encabezado Transfer-Encoding es efectivamente "fragmentado". Desafortunadamente, el servidor ya pegó el mensaje, por lo que no vemos la fragmentación real.
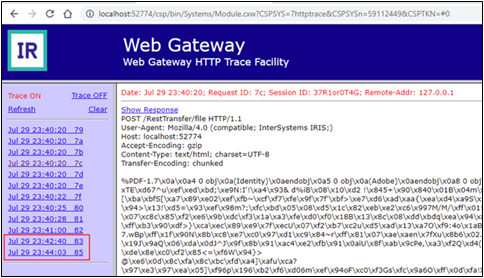
Usar la funcionalidad Trace no muestra mucha más información, pero permite aclarar que hay un espacio libre entre la penúltima y la última solicitud.
Para ver las partes reales de los mensajes, copiamos el cliente en otro equipo para usar un rastreador de red. Aquí hemos elegido usar Wireshark porque es gratuito y tiene las funciones necesarias. Para mostrar mejor cómo el código divide el archivo en fragmentos, podemos cambiar el valor de MAXSIZEOFCHUNK a 100 y elegir enviar un archivo pequeño. Así que ahora podemos ver el siguiente resultado:
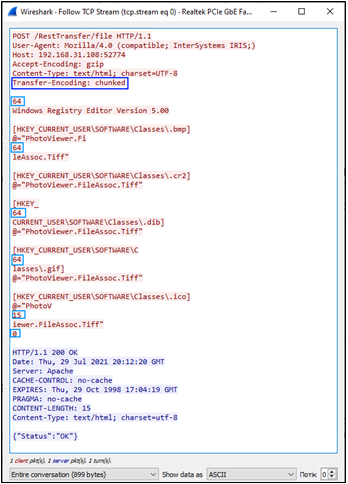
Vemos que las longitudes de todos los fragmentos menos los dos últimos son iguales a 64 en HEX (100 en DEC), el último fragmento con datos es igual a 21 DEC (15 en HEX), y podemos observar que el tamaño del último fragmento es cero. Todo parece OK y se ajusta a las especificaciones. La longitud general del archivo es igual a 421 (4x100+1x21), que lo podemos ver también en los globals:
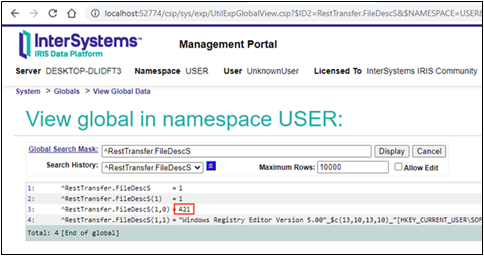
Conclusión
En general, podemos ver que este enfoque funciona y permite enviar archivos grandes al servidor sin problemas. Además, si se envían grandes cantidades de datos a un cliente, posiblemente queráis familiarizaros con la Web Gateway Operation and Configuration, la sección Parámetros de configuración en la ruta de la aplicación, el parámetro de notificación sobre el tamaño de la respuesta. Especifica el comportamiento del Web Gateway cuando se envían grandes cantidades de datos dependiendo de la versión de HTTP utilizada.
El código para este enfoque se añade a la versión anterior de este ejemplo en GitHub y Open Exchange.
Con respecto al envío de archivos por partes, también es posible utilizar el encabezado Content-Range con o sin el encabezado Transfer-Encoding para indicar qué parte exacta de los datos se está transfiriendo. Además, se puede utilizar un concepto completamente nuevo de streams disponible con la especificación HTTP/2.
Como siempre, si tenéis alguna pregunta o sugerencia, no dudéis en escribirla en los comentarios.