Integración continua en IRIS con Git y Jenkins
Introducción
En entornos de interoperabilidad sanitaria, InterSystems Health Connect suele contener componentes críticos como producciones, procesos de negocio, operaciones, servicios, clases utilitarias, rutinas y otros artefactos ObjectScript. Tradicionalmente, muchos despliegues de estos componentes se han hecho de forma manual, copiando clases, importando XML o utilizando herramientas administrativas desde el portal de gestión.
Aunque este enfoque puede funcionar en fases iniciales, se vuelve difícil de mantener cuando el proyecto crece, cuando hay varios desarrolladores trabajando en paralelo o cuando se necesitan despliegues repetibles entre entornos como desarrollo, integración, preproducción y producción.
Una alternativa más robusta consiste en integrar Health Connect dentro de un flujo de integración continua, utilizando Git como repositorio de código fuente y Jenkins como orquestador del despliegue.
El objetivo de este artículo es mostrar una aproximación práctica para:
- versionar código de Health Connect en GitHub,
- detectar únicamente los ficheros modificados desde el último despliegue,
- copiar esos ficheros a una carpeta de staging,
- cargar y compilar los cambios en un namespace de Health Connect,
- y ejecutar todo el proceso remotamente desde Jenkins mediante SSH.
Arquitectura
Para nuestro ejemplo hemos configurado los siguientes elementos:
Instancia de IRIS for Health
He desplegado InterSystems IRIS for Health en una máquina de AWS con un RHEL10 con su propio Apache Server y permitido la conectividad mediante HTTP y SSH.
Para el desarrollo he configurado Visual Studio Code para trabajar sobre una instancia de IRIS en local sobre la que haré los cambios de código que luego subiré a GitHub.
Repositorio de GitHub
Hemos elegido GitHub como control de versiones aprovechando la extensión que tiene disponible en Visual Studio Code, esto nos permitirá trabajar con ramas si fuera necesario.
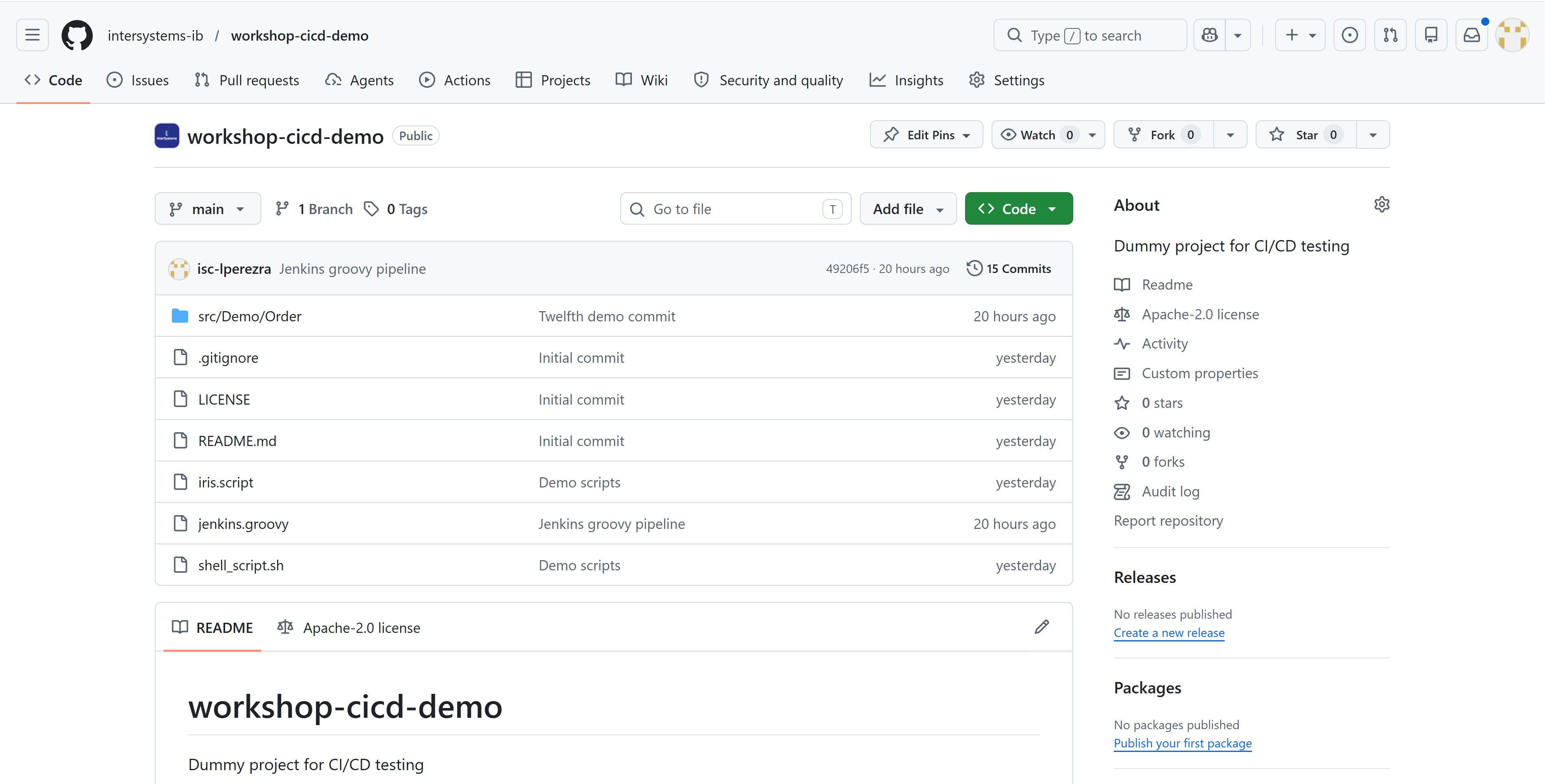
Este elemento será clave para el proceso de CI/CD ya que será de donde podamos obtener el último código desarrollado para su despliegue.
Jenkins
Para los que no conozcáis Jenkins, es un servidor de automatizaciones Open Source muy utilizado para procesos de integración continua ya que dispone de multitud de plugins que nos facilitarán la tarea.
Jenkins dispone de una herramienta de scripts en groovy que nos permite implementar los pasos necesarios para el proceso de integración. Para este ejemplo no nos complicaremos demasiado.
Procedimiento de integración
Para este ejemplo hemos supuesto que estamos en un proyecto de interoperabilidad, con una instancia de DESARROLLO (desplegada en el servidor de AWS) en la que deseamos desplegar los cambios que los programadores realizan en sus instancias locales para realizar las pruebas pertinentes. Más o menos estos serían los pasos:
- El desarrollador implementa las funcionalidades en su instancia local.
- El desarrollador sube cambios a la rama correspondiente del repositorio de GitHub.
- El responsable del despliegue accede a Jenkins y lanza un pipeline.
- Jenkins se conecta por SSH al servidor de DESARROLLO.
- En el servidor se ejecuta un script Linux.
- El script descarga los últimos cambios del repositorio mediante un git pull.
- Este script identifica los ficheros nuevos o modificados que se copian a un directorio del servidor.
- Con los ficheros identificados el script invoca un segundo script en ObjectScript.
- El segundo script carga y compila los ficheros en la instancia de IRIS for Health.
- Si la carga fue correcta, el script reinicia la producción.
Como podéis ver hemos elegido una operativa muy básica, pero que puede resultar de bastante ayuda.
Echemos ahora un vistazo a los scripts que ejecutaremos mediante Jenkins en nuestro servidor de DESARROLLO:
#!/usr/bin/env bash
set -euo pipefail
# =========================
# Configuración
# =========================
REPO_URL="https://github.com/intersystems-ib/workshop-cicd-demo"
BRANCH="main"
# Clon local usado solo para comparar commits
CACHE_REPO="/opt/git-cache/project_repo"
# Carpeta que contendrá SOLO los ficheros a subir a Health Connect
EXPORT_DIR="/projectGit"
# Fichero con el último commit procesado
STATE_FILE="${CACHE_REPO}/.last_sync_commit"
# Limpiar EXPORT_DIR antes de copiar los cambios detectados
CLEAN_EXPORT_DIR="true"
# =========================
# Validaciones
# =========================
if ! command -v git >/dev/null 2>&1; then
echo "Error: git no está instalado."
exit 1
fi
mkdir -p "${EXPORT_DIR}"
mkdir -p "$(dirname "${CACHE_REPO}")"
# =========================
# Clonar o actualizar caché
# =========================
if [ ! -d "${CACHE_REPO}/.git" ]; then
echo "Clonando repositorio en caché..."
git clone --branch "${BRANCH}" "${REPO_URL}" "${CACHE_REPO}"
else
echo "Actualizando caché local..."
git -C "${CACHE_REPO}" fetch origin
git -C "${CACHE_REPO}" checkout "${BRANCH}"
git -C "${CACHE_REPO}" reset --hard "origin/${BRANCH}"
fi
REMOTE_COMMIT="$(git -C "${CACHE_REPO}" rev-parse HEAD)"
# =========================
# Primera ejecución
# =========================
if [ ! -f "${STATE_FILE}" ]; then
echo "Primera ejecución."
echo "Copiando todo el contenido actual del branch a ${EXPORT_DIR}..."
if [ "${CLEAN_EXPORT_DIR}" = "true" ]; then
find "${EXPORT_DIR}" -mindepth 1 -maxdepth 1 -exec rm -rf {} +
fi
rsync -av --delete --exclude ".git" "${CACHE_REPO}/" "${EXPORT_DIR}/"
echo "${REMOTE_COMMIT}" > "${STATE_FILE}"
echo "Primera exportación completada."
exit 0
fi
LAST_COMMIT="$(cat "${STATE_FILE}")"
if [ "${LAST_COMMIT}" = "${REMOTE_COMMIT}" ]; then
echo "No hay cambios nuevos."
exit 0
fi
echo "Comparando commits:"
echo " anterior: ${LAST_COMMIT}"
echo " actual: ${REMOTE_COMMIT}"
if [ "${CLEAN_EXPORT_DIR}" = "true" ]; then
echo "Limpiando carpeta de exportación..."
find "${EXPORT_DIR}" -mindepth 1 -maxdepth 1 -exec rm -rf {} +
fi
# =========================
# Exportar solo archivos A/M/R
# =========================
while IFS= read -r -d '' status && IFS= read -r -d '' path1; do
case "${status}" in
M|A)
echo "Exportando ${status}: ${path1}"
mkdir -p "${EXPORT_DIR}/$(dirname "${path1}")"
cp -f "${CACHE_REPO}/${path1}" "${EXPORT_DIR}/${path1}"
;;
D)
# Ignoramos borrados
echo "Ignorando borrado: ${path1}"
;;
R*)
IFS= read -r -d '' path2
echo "Exportando renombrado: ${path1} -> ${path2}"
mkdir -p "${EXPORT_DIR}/$(dirname "${path2}")"
cp -f "${CACHE_REPO}/${path2}" "${EXPORT_DIR}/${path2}"
;;
*)
echo "Cambio no manejado automáticamente: ${status} ${path1}"
;;
esac
done < <(git -C "${CACHE_REPO}" diff --name-status -z "${LAST_COMMIT}" "${REMOTE_COMMIT}")
echo "${REMOTE_COMMIT}" > "${STATE_FILE}"
echo "Exportación incremental completada en ${EXPORT_DIR}"echo "Iniciando carga y compilación de ficheros a Health Connect"
(echo '_system'; echo 'SYS'; cat iris.script) | iris session IRISHEALTH
echo "Compilación concluida con éxito" Como podéis ver, este script ejecuta el git pull sobre nuestro repositorio de GitHub, actualiza el código fuente en un directorio del servidor de DESARROLLO, detectamos los cambios respecto a la última versión descargada, los extraemos a un segundo directorio (/projectGit) y finalmente invocamos el script de IRIS.
(echo '_system'; echo 'SYS'; cat iris.script) | iris session IRISHEALTH Esos dos primeros echo nos permitirá pasarle el usuario y la contraseña a la sesión del terminal que necesitamos abrir para ejecutar nuestro script de ObjectScript:
zn "DEMO"
set sc = $SYSTEM.OBJ.LoadDir("/projectGit/src/Demo", "ck", , 1)
if '$SYSTEM.Status.IsOK(sc) do $SYSTEM.Status.DisplayError(sc) quit
set production = "Demo.Order.Production"
set ^Ens.Configuration("csp","LastProduction") = production
do ##class(Ens.Director).SetAutoStart(production)
do ##class(Ens.Director).StartProduction(production)
write !,"Produccion iniciada correctamente: ",production,! En este script es donde importamos las clases que hemos identificado como modificadas o creadas y las compilamos. Si la compilación se ha realizado con éxito reiniciamo la producción correspondiente de nuestro namespace DEMO para que se notifiquen los cambios.
Perfecto, tenemos nuestros scripts, nuestro servidor de DESARROLLO y nuestro GitHub, vayamos a configurar nuestro Jenkins.
Configurando Jenkins
Antes de empezar a crear nuestro pipeline debemos instalar un plugin que nos permita conectarnos vía SSH a nuestro servidor de DESARROLLO con nuestro usuario y clave primaria.
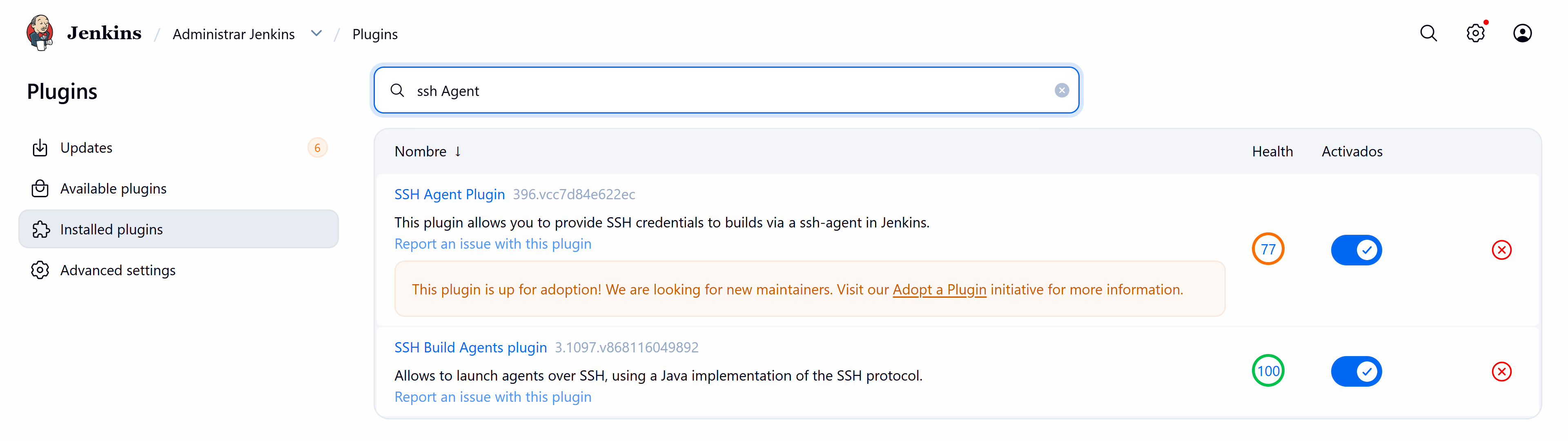
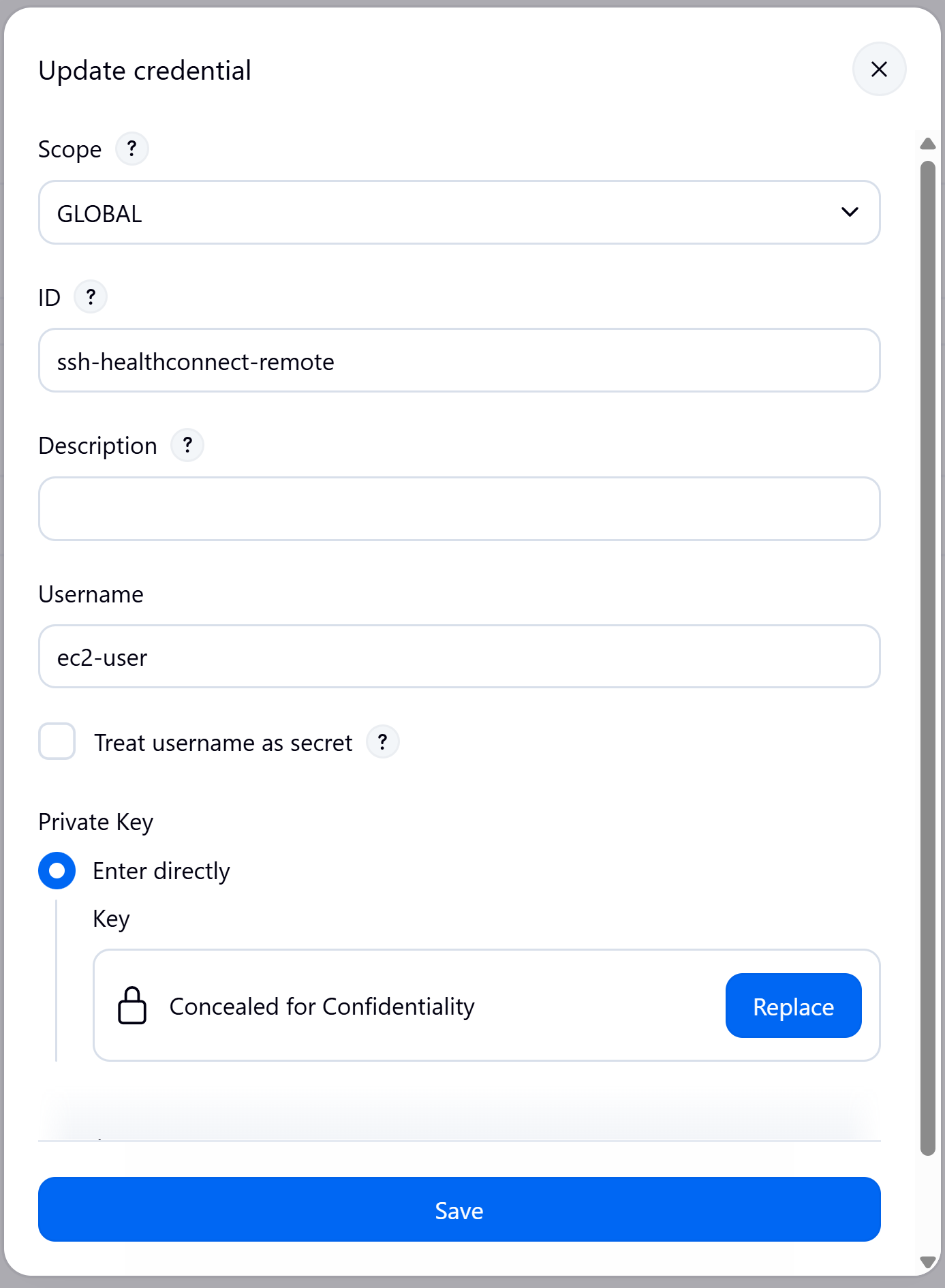
Creamos desde la configuración de Jenkins una credencial de acceso a nuestro servidor de DESARROLLO:
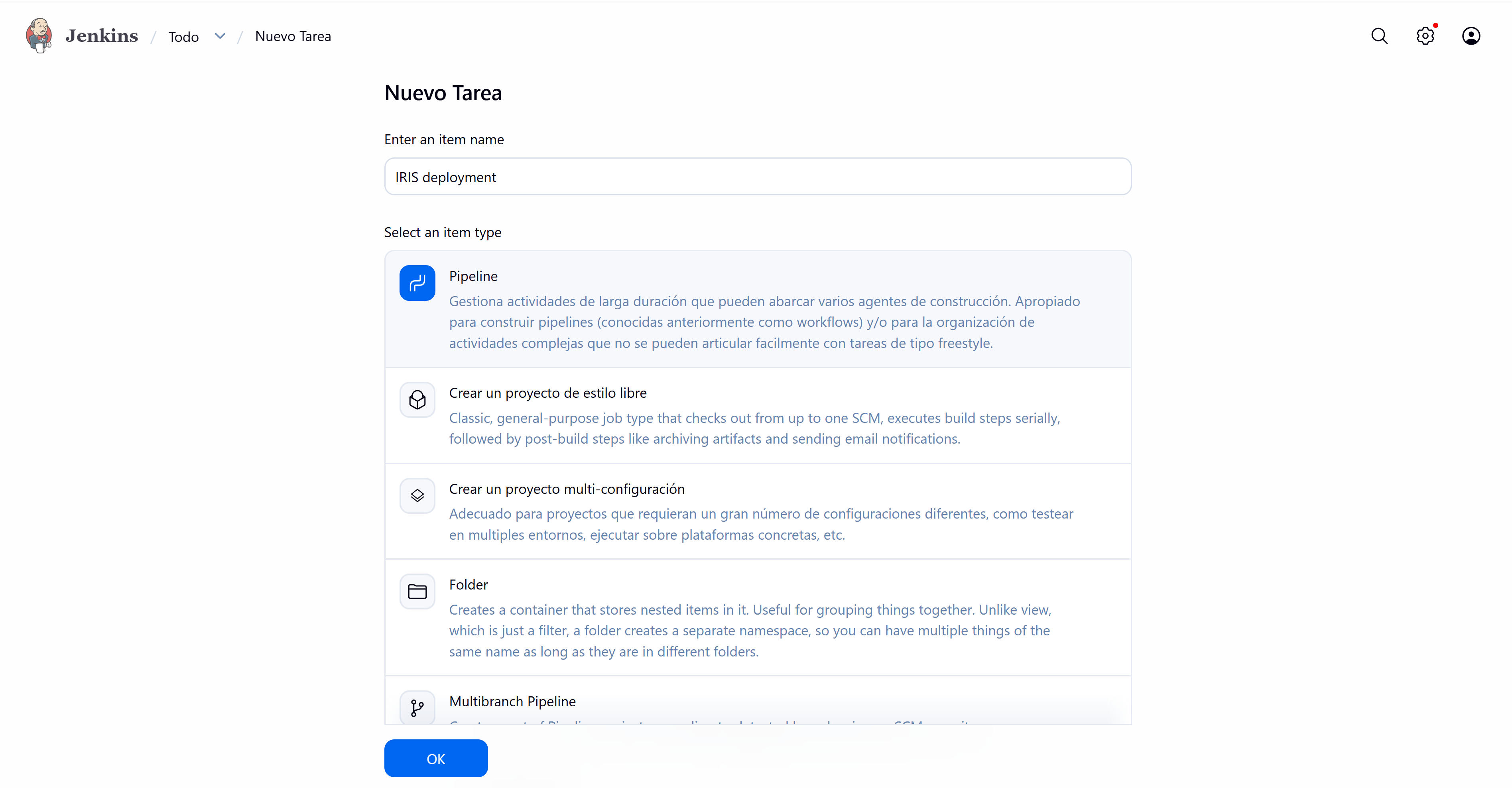
Y finalmente procedemos a crear el Pipeline.
Dentro de la configuración del pipeline definimos el siguiente script que nos permitirá el despliegue:
pipeline {
agent any
parameters {
string(name: 'GIT_BRANCH', defaultValue: 'main', description: 'Rama del repositorio')
string(name: 'REMOTE_HOST', defaultValue: 'ec2-**-**-***-**.**-*****.compute.amazonaws.com', description: 'Host remoto')
string(name: 'REMOTE_USER', defaultValue: 'ec2-user', description: 'Usuario SSH remoto')
string(name: 'REMOTE_SCRIPT_NAME', defaultValue: 'shell_script.sh', description: 'Nombre del script remoto')
}
environment {
REPO_URL = 'https://github.com/intersystems-ib/workshop-cicd-demo'
SSH_CREDENTIALS_ID = 'ssh-healthconnect-remote'
}
stages {
stage('Checkout') {
steps {
git branch: "${params.GIT_BRANCH}", url: "${env.REPO_URL}"
}
}
stage('Validar script') {
steps {
sh '''
set -eu
test -f shell_script.sh
chmod +x shell_script.sh
'''
}
}
stage('Ejecutar script remoto') {
steps {
sshagent(credentials: ["${env.SSH_CREDENTIALS_ID}"]) {
sh '''
set -eu
ssh -o StrictHostKeyChecking=no "${REMOTE_USER}@${REMOTE_HOST}" \
"sudo sh '/${REMOTE_SCRIPT_NAME}'" | tee remote_execution.log
'''
}
}
}
}
post {
always {
archiveArtifacts artifacts: 'remote_execution.log', allowEmptyArchive: true
}
success {
echo 'Despliegue remoto completado correctamente.'
}
failure {
echo 'El despliegue remoto ha fallado. Revisa remote_execution.log.'
}
}
}¿Qué hace nuestro script? Muy sencillo, comprueba que exista nuestro repositorio de GitHub con su rama asociada y a continuación, manda, mediante un SSH la instrucción de ejecutar el script de Linux que se encargará de la descarga y actualización de nuestra instancia.
Veamoslo en ejecución con un pequeño ejemplo.
Ejecutando el proceso
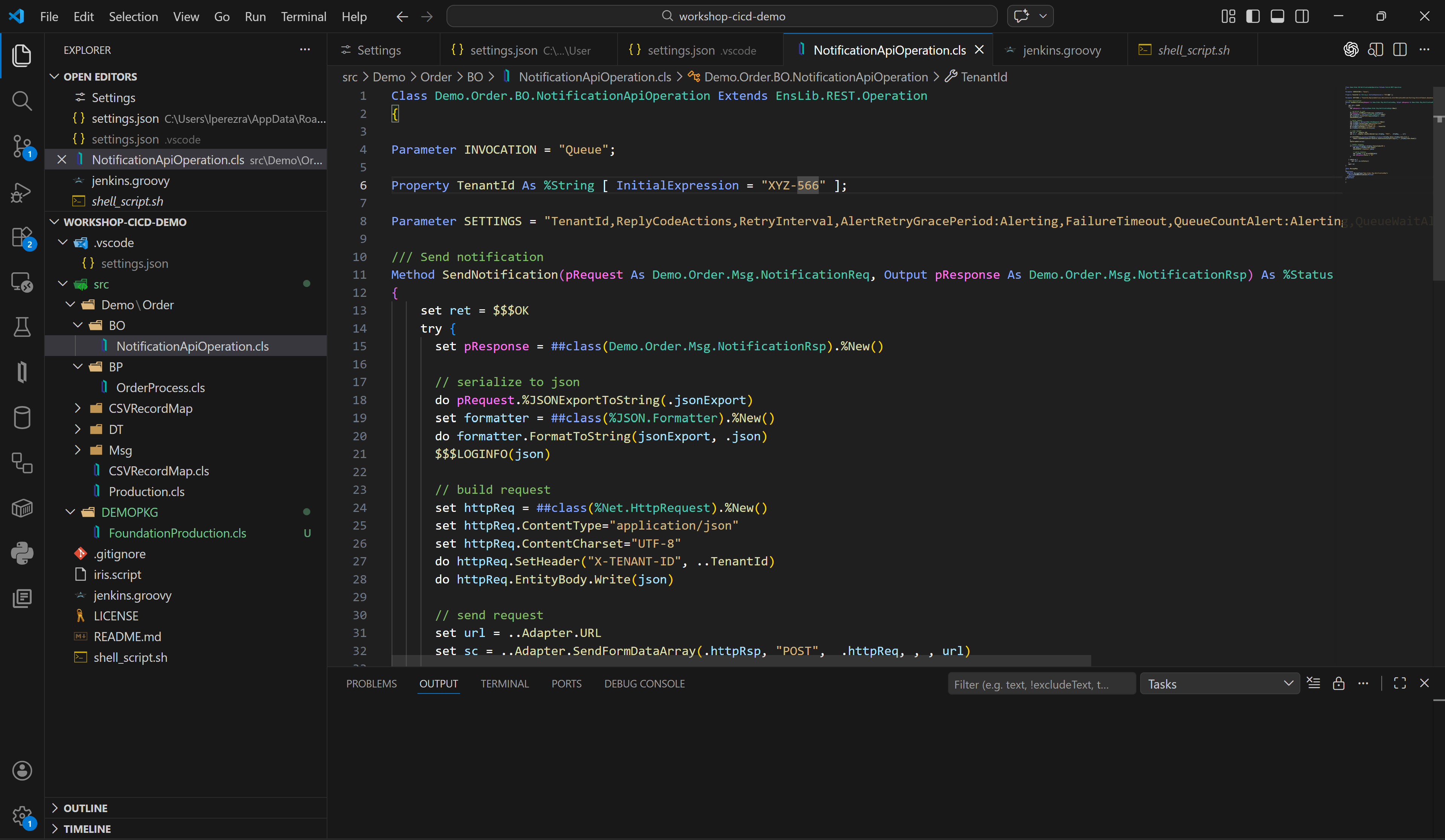
Disponemos de nuestra producción funcionando con normalidad y queremos hacer un cambio en uno de nuestros componentes para que el valor por defecto mostrado en uno de los parámetros sea diferente:
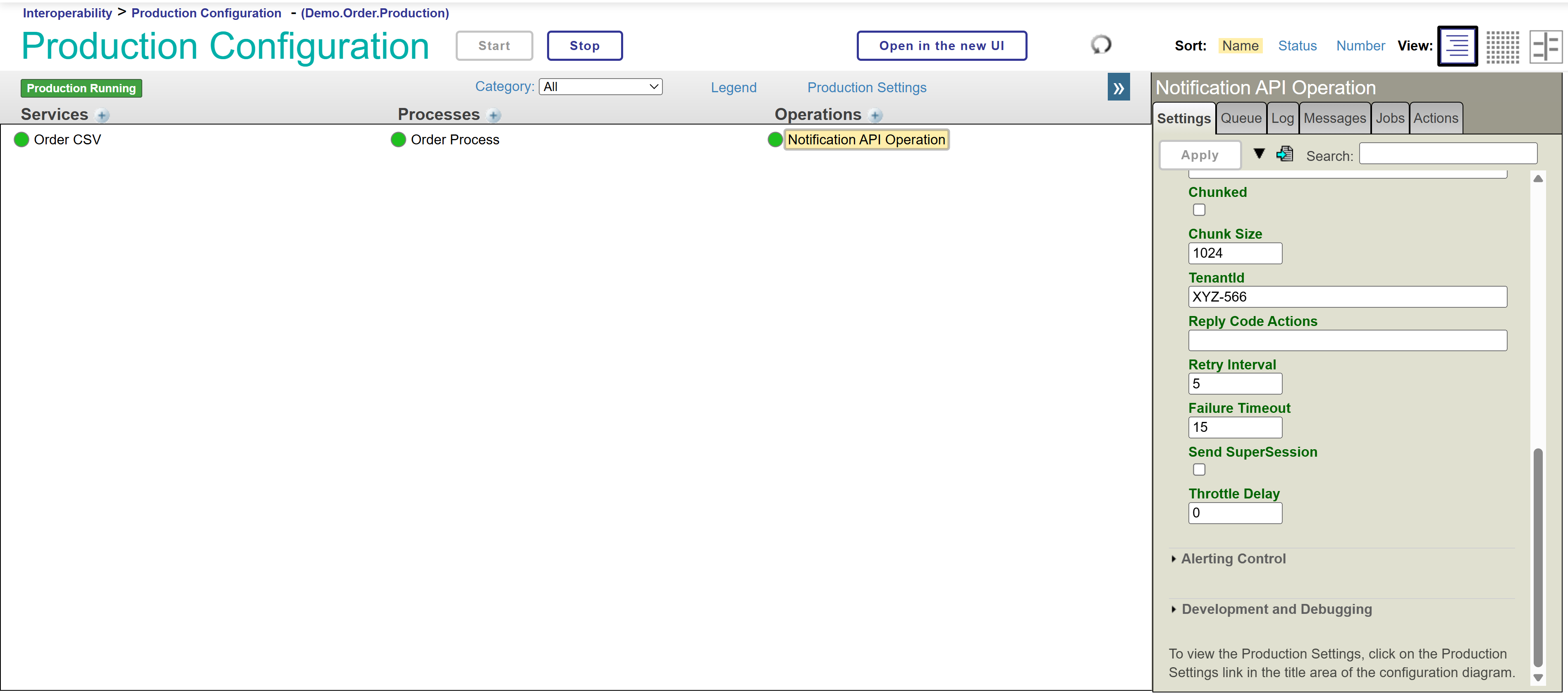
Ahora queremos que nuestro parámetro TenantId tenga el valor ZZZ-999, muy bien, corrijamos el código que tenemos en nuestra instancia local desde Visual Studio Code y subamos el cambio a nuestro GitHub.
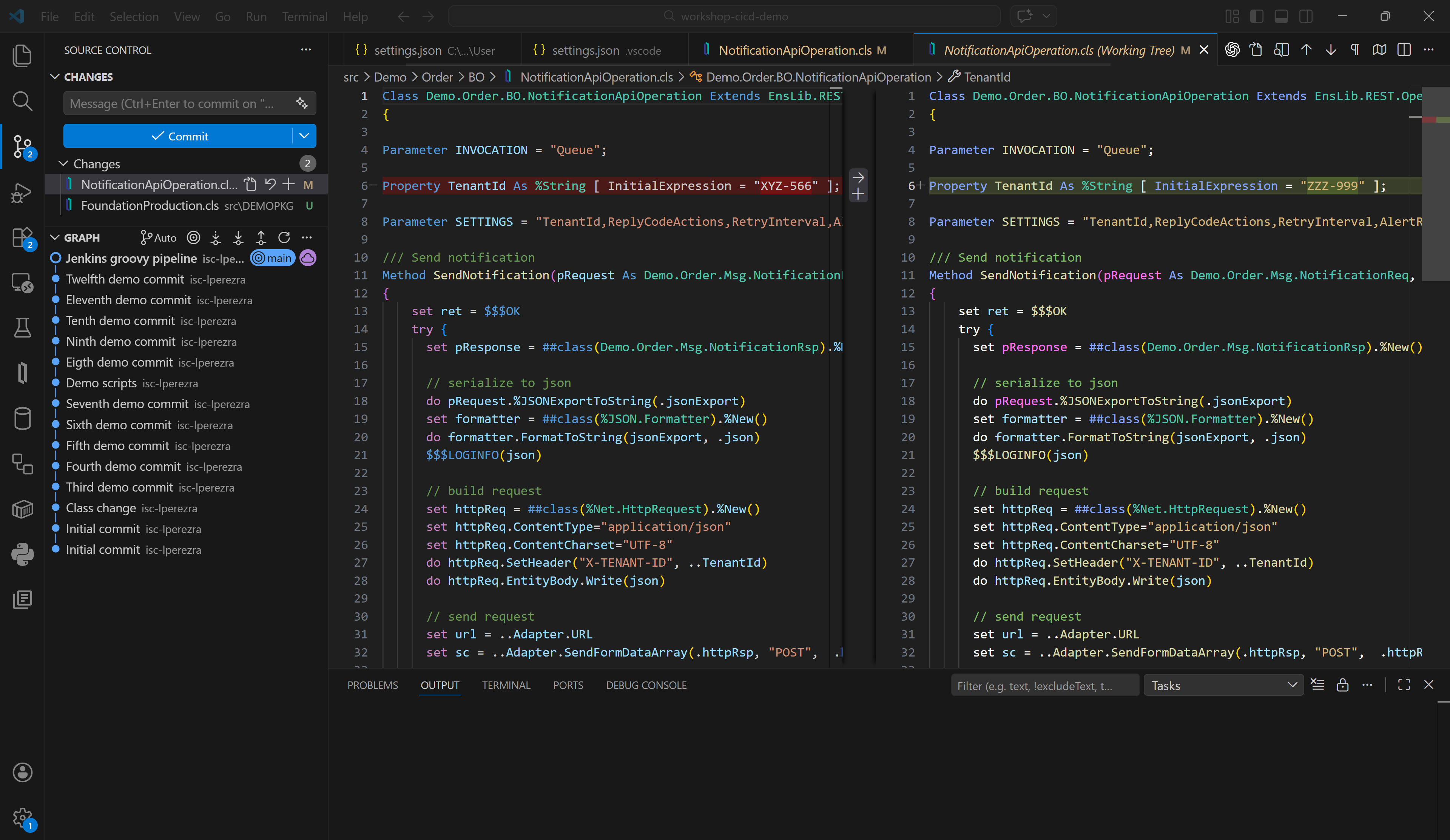
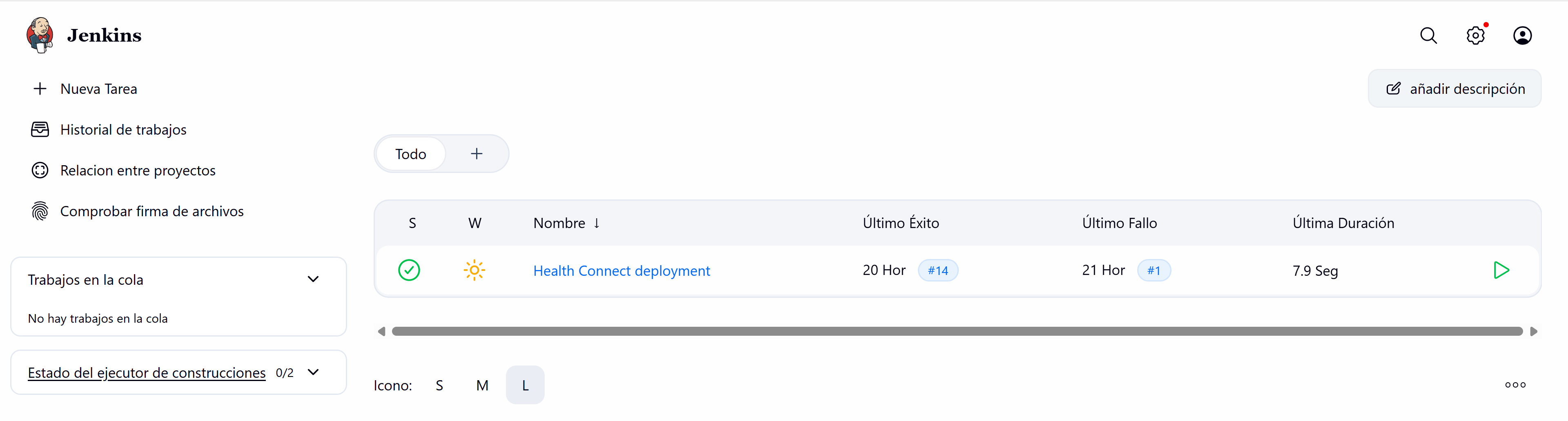
Con nuestro cambio subido a nuestro repositorio ya podemos ejecutar el Pipeline desde nuestra instancia de Jenkins. Veamos el resultado del Pipeline:
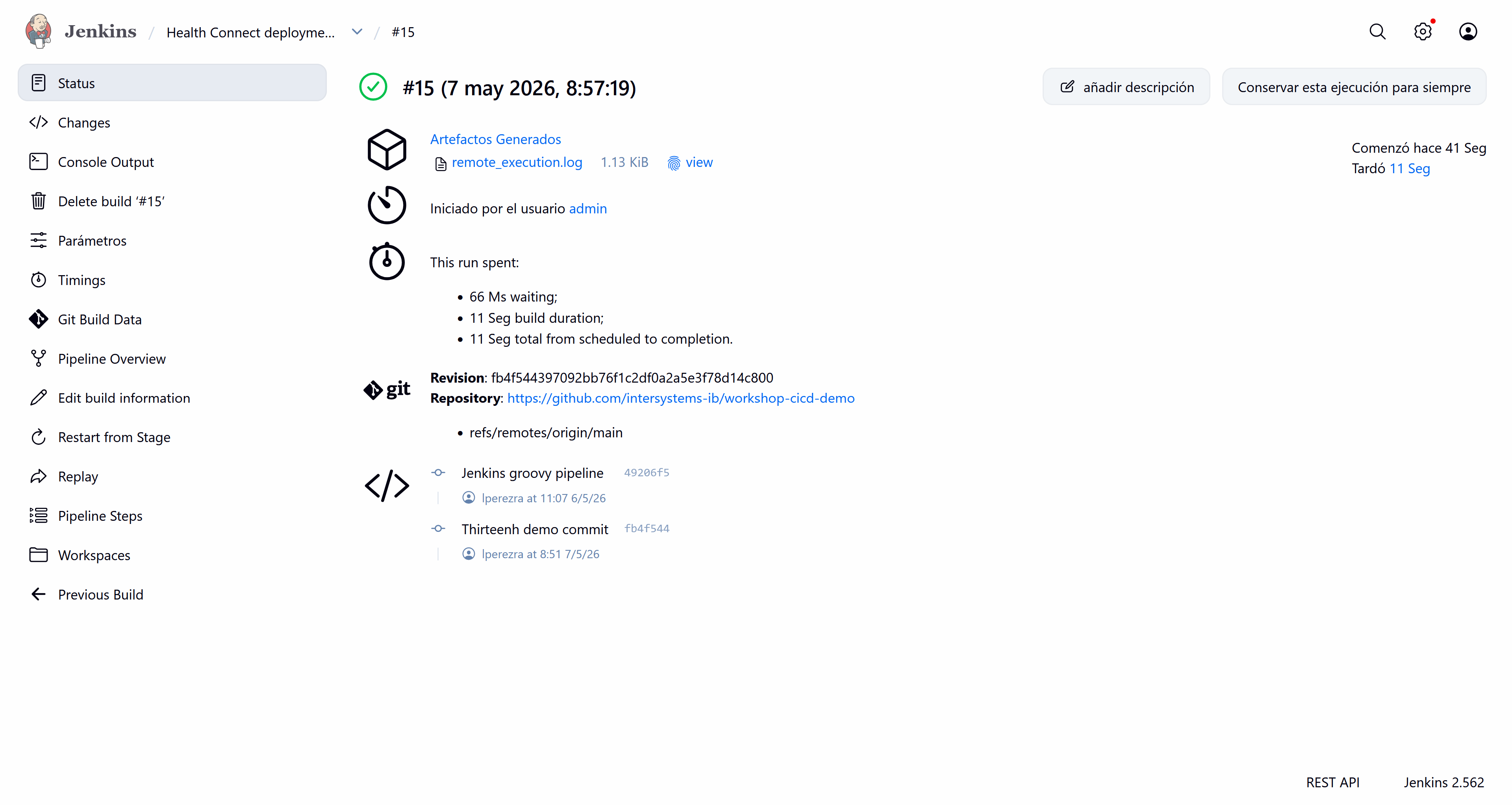
Todo, correcto, ha detectado nuestro cambio y ha ejecutado correctamente el script:
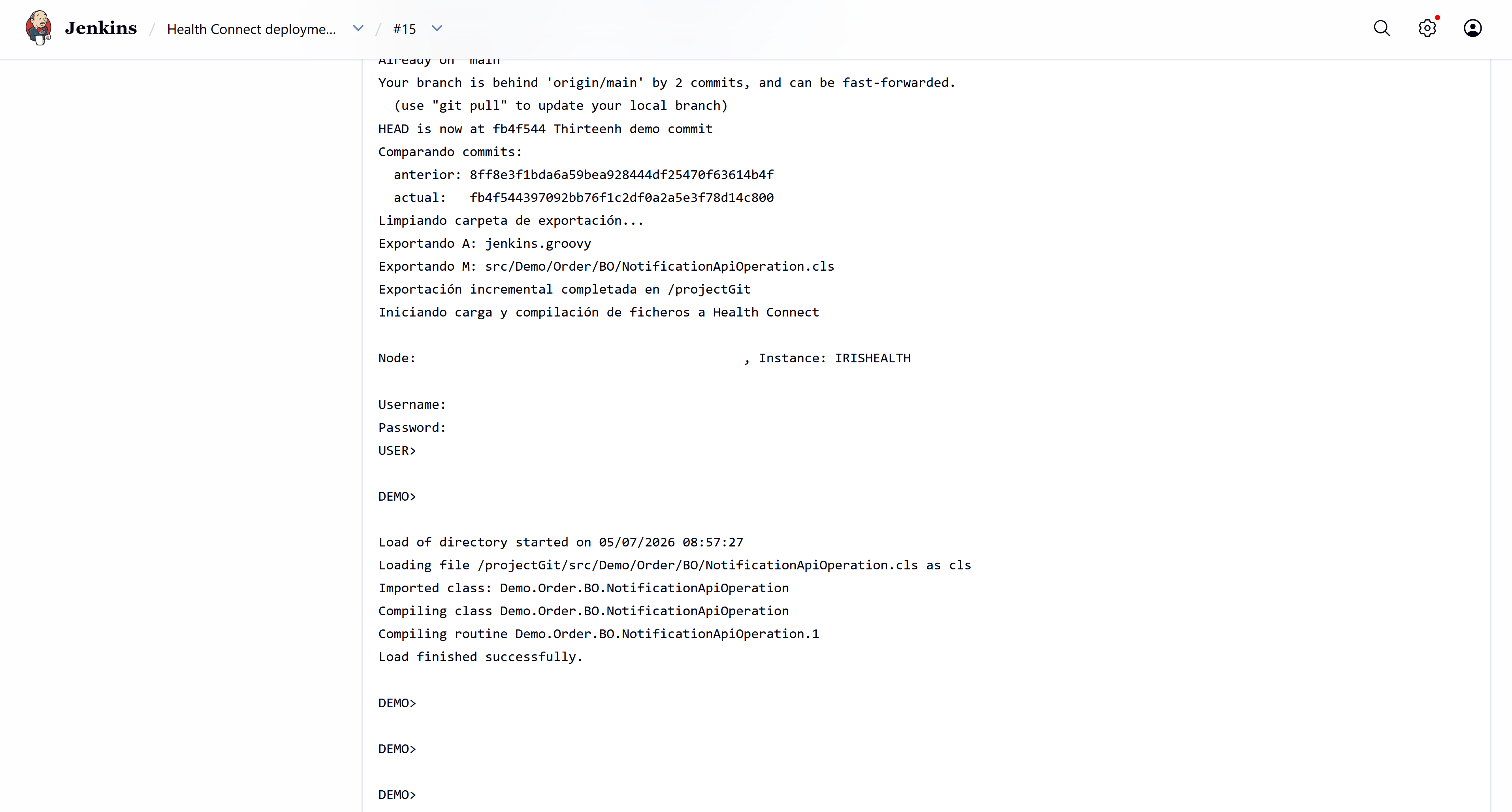
Comprobemos que el parámetro ha cambiado y la producción se ha reiniciado correctamente.
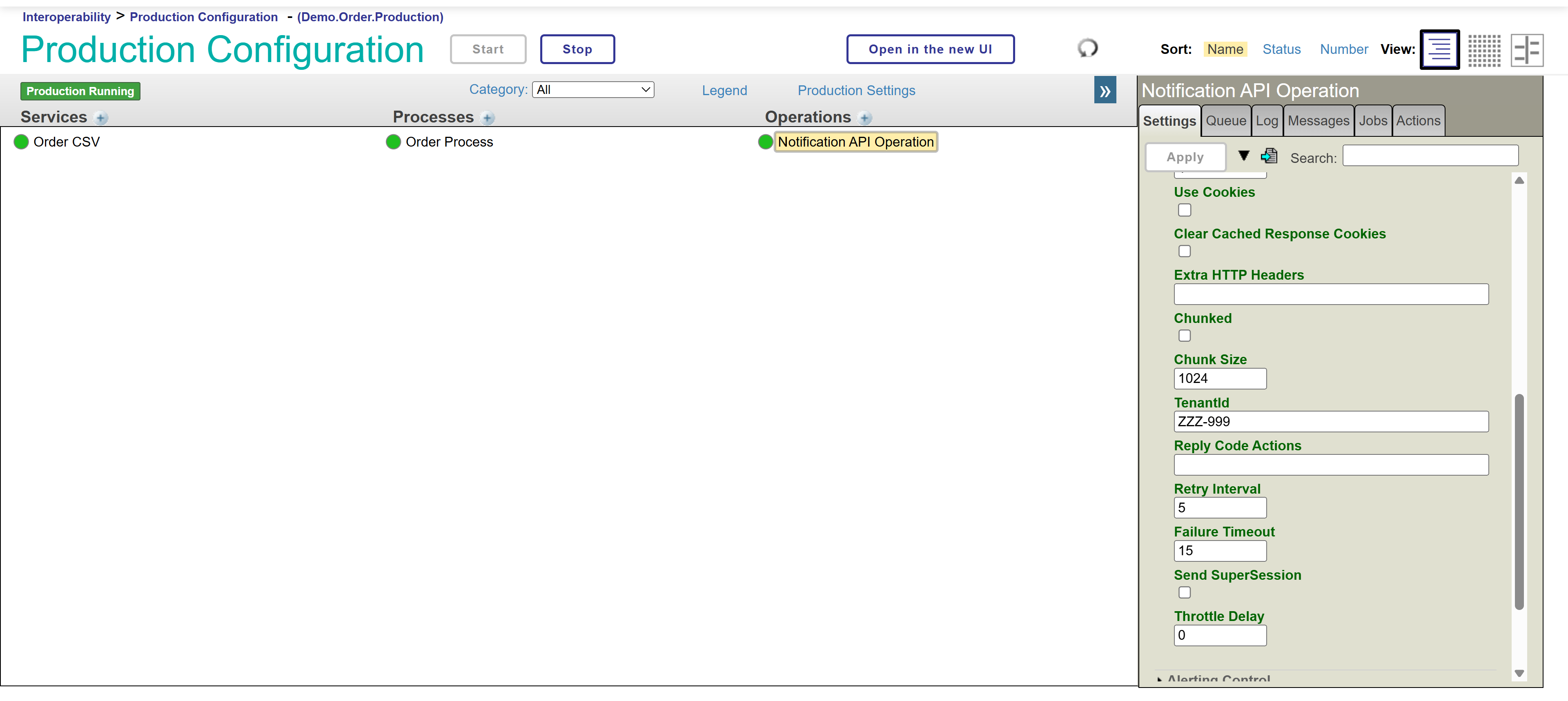
¡Ahí tenemos nuestro nuevo TenantId! ¡Éxito total y rotundo!
Conclusiones y siguientes pasos.
Como podéis haber comprobado, no hay ningún tipo de limitación tecnológica por parte de IRIS para formar parte de un proceso de integración continua. Sólo necesitas los scripts adecuados que más se adapten a tu operativa diaria.
En este artículo hemos podido ver un pequeño ejemplo de integración continua con IRIS for Health, pero esto podría ampliarse a determinadas configuraciones que podrían desplegarse mediante funcionalidades como Configuration Merge.
¡Animaos a probadlo!