
 Por fecha
Por fecha Open Exchange app
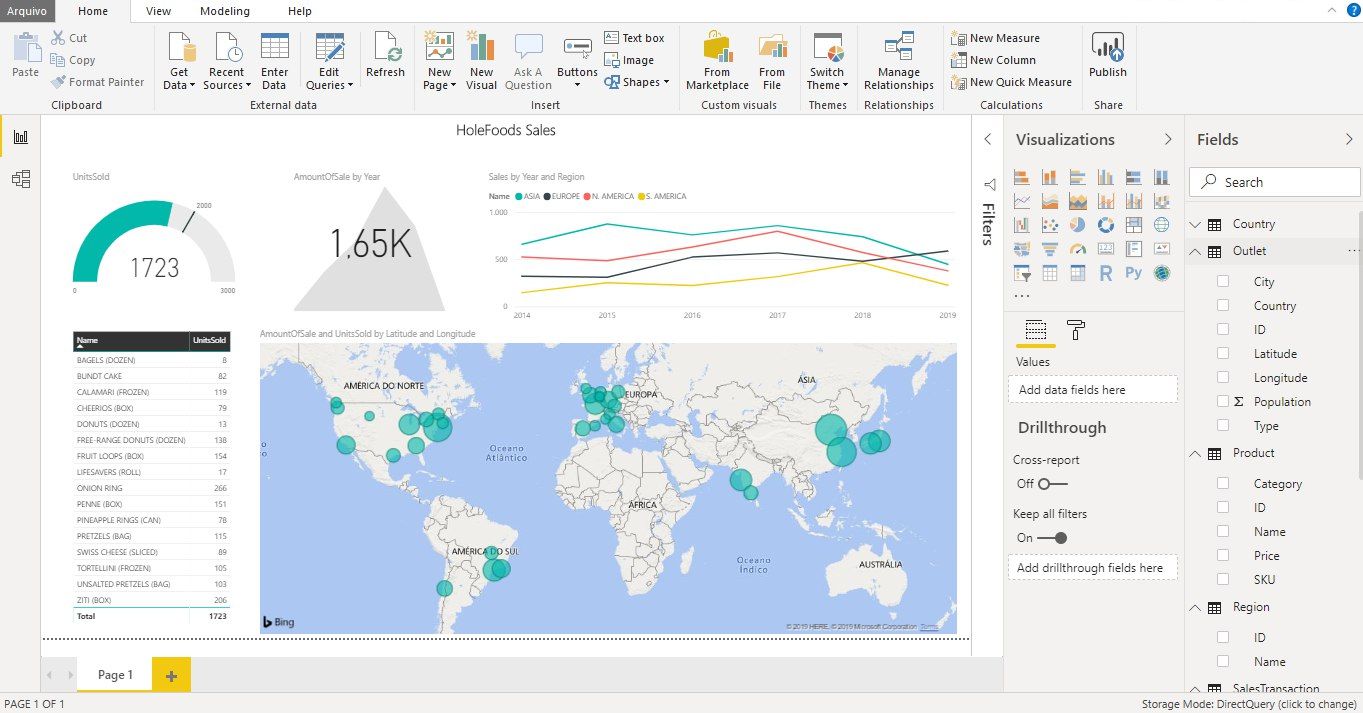
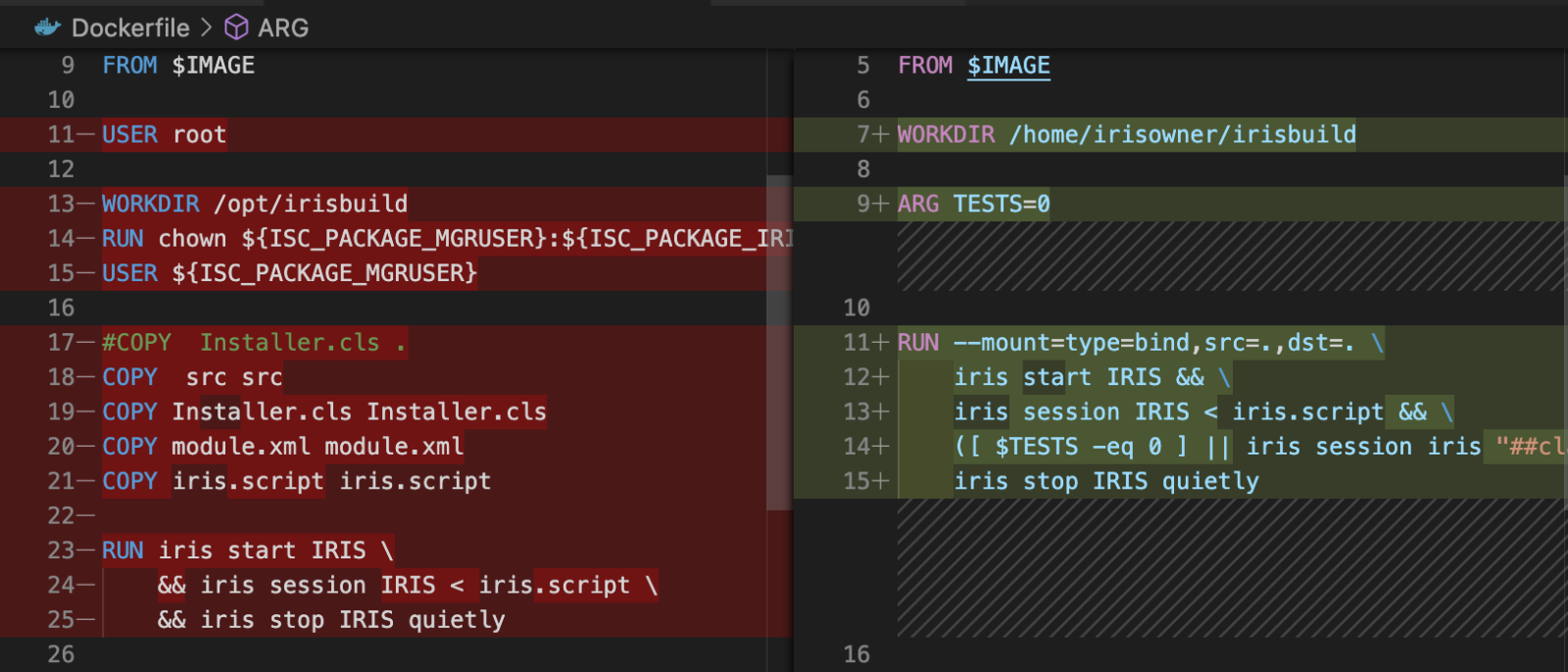
Open Exchange appObjectScript no incluye ningún método por defecto para añadir un array JSON a otro. Este es un fragmento de código que utilizo y que es equivalente al método concat() de JavaScript.
Puedes llamarlo con cualquier número de argumentos para concatenarlos en un nuevo array. Si un argumento es un array dinámico, sus elementos serán añadidos. Si no, el argumento en sí será añadido.

.png)