Limpiar filtro
Pregunta
Daniel Aguilar · 1 sep, 2020
Buenas tardes, estamos probando la migración a la versión de IRIS porque queríamos aprovechar el poder trabajar con el plugin Insertystems ObjectScript de Visual Studio Code para control de versiones pero haciendo pruebas veo lo siguiente:
Nosotros tenemos muchísimas clases y rutinas en nuestros namespaces y cuando hago un cambio de rama en VSCODE para que los cambios se graben en el lado servidor hay que pulsar en Importar y Compilar el namespace completo a fin de que los cambios de la nueva rama queden grabados en el servidor (Este proceso le puede costar fácilmente 20 minutos y no aporta ningún feedback del porcentaje de la operación realizado) ya que de lo contrario tengo los cambios en las vistas que ofrece el plugin de VSCODE tanto en el lado cliente como en el lado servidor pero si entro con el Studio y abro la rutina veo que efectivamente los cambios de la rama a la que acabo de cambiar no están.
¿Hay alguna forma de "aligerar" este proceso de "Importar y compilar" para que lo realice de un modo mas eficiente?
¿Hay alguien que esté trabajando actualmente con el plugin para VSCODE que me pueda echar una mano?
Resumiendo, problemas que tenemos:
-> Hay que ejecutar manualmente "Importar y compilar" los cambios para todos los namespaces cuando cambias de rama.
-> La operación "Importar y compilar" tarda como 20 minutos y no reporta feedback del estado actual de la operación (En el OUTPUT del terminal ObjectScript se queda como colgado y va apareciendo el avance por bloques derrepente)
Muchas gracias de antemano por vuestra ayuda ;-)
Daniel, let me answer you in English, as I don't speak Spanish, hope I got your point (with the help from google translate) and you'll get my point.
A common use-case for most of the editors with any languages but ObjectScript is just to edit code. With some extra possibilities related to a particular language.
But InterSystems, not a common language, and as you said you have to compile your code and would like to have more control over it.
If you would need to do it in Java, you rather use Gradle or Ant, if it would be C,C++ I think something like cmake. JavaScript or TypeScript even also use some kind of compilers. But most of those tools work outside of any editor. So, I'm sure that InterSystems ObjectScript not an exception here anyway, I would not say that's a good way if VSCode would have so much control over it. My point is, that you some own ways how to build the entire project from sources. And the most common way to do it now with %Installer manifest.
Good morning Dimitry, I'm glad to be back to talk to you.
Thanks for your reply ( I will try to answer you in English )
I have never use %Installer, I have been investigating and I seem to understand that it is a class with a manifest in which the server configuration is defined, the class must be have a method called setup and that it can be executed by terminal, I understand that a condition can also be included to force the compilation of all the classes and routines (It is right?)
Does using %Intaller offer any performance improvement?
Would the steps to follow be the following ?:
1 -> Change branch from VsCode
2 -> Launch the "setup" method of the %Intaller class from terminal (for import and compile routines in server side, Would this be equivalent to clicking "Import and Compile", right? ), Should this method be launched from within VsCode terminal?
3 -> Could the execution of the% Installer be automated after the branch change?
Thank you very much Dimitry
Artículo
Eduardo Anglada · 24 mayo, 2021
Qué te parece si te digo que muy pronto te podrás conectar a IRIS desde la aplicación escrita en Rust...
¿Qué es Rust?
Rust es un lenguaje de programación multiparadigma diseñado teniendo en cuenta el rendimiento, la seguridad y especialmente que la concurrencia sea segura. Rust es sintácticamente similar a C++, pero puede garantizar la seguridad de la memoria mediante el uso de un verificador de préstamos para validar las referencias. Rust logra la seguridad de la memoria sin emplear un recolector de basura, y el conteo de referencias es opcional. (c) Wikipedia.
Es el lenguaje más valorado durante los últimos cinco años en la encuesta de Stack Overflow 2020.
¿Qué es posible ahora mismo?
Puede trabajar con globals y hacer consultas SQL sencillas. Observa el ejemplo de trabajo.
use irisnative;
use irisnative::{connection::*, global, global::Sub, Global};
fn main() {
let host = "127.0.0.1";
let port = 1972;
let namespace = "USER";
let username = "_SYSTEM";
let password = "SYS";
match irisnative::connect(host, port, namespace, username, password) {
Ok(mut connection) => {
println!("Connection established");
println!("Server: {}", connection.server_version());
connection.kill(&global!(A));
connection.set(&global!(A(1)), "1");
connection.set(&global!(A(1, 2)), "test");
connection.set(&global!(A(1, "2", 3)), "123");
connection.set(&global!(A(2, 1)), "21test");
connection.set(&global!(A(3, 1)), "test31");
let mut global = global!(A(""));
while let Some(key) = connection.next(&mut global) {
println!("^A({:?}) = {:?}", key, {
if connection.is_defined(&global).0 {
let value: String = connection.get(&global).unwrap();
value
} else {
String::from("<UNDEFINED>")
}
});
let mut global1 = global!(A(key, ""));
while let Some(key1) = connection.next(&mut global1) {
let value: String;
if connection.is_defined(&global1).0 {
value = connection.get(&global1).unwrap();
} else {
value = String::from("<UNDEFINED>");
}
println!("^A({:?}, {:?}) = {:?}", key, key1, value);
}
}
let mut rs = connection.query(String::from(
"SELECT Name from %Dictionary.ClassDefinition WHERE Super = 'Ens.Production' and Abstract<>1"));
while rs.next() {
let name: String = rs.get(0).unwrap();
println!("{}", name);
}
}
Err(err) => {
println!("Error: {}", err.message);
}
}
}
Por lo tanto, será posible conectarse a IRIS por medio de la red, tan pronto como tenga acceso al puerto del súper servidor (1972).
Caso de uso real
Para utilizarlo en producción, tiene que ser compilado en un archivo ejecutable o librería. Yo tengo un proyecto donde lo uso ahora. Es la extensión VSCode para el control avanzado de InterSystems IRIS. El proyecto participó en el Gran Premio para Desarrolladores de InterSystems. Rust ayuda a obtener acceso directo a IRIS, y será posible comprobar el estado o detener/iniciar la producción, observar los globals y muchas otras cosas en el futuro.
Rust tiene que ser compilado en un formato binario para la plataforma deseada, y por el momento esta extensión se desarrolló para macOS x64 y Windows x64. Pero Rust se puede compilar para una amplia gama de plataformas, incluyendo Arm64.
Veamos qué más se puede hacer
Vamos a intentar ejecutar la aplicación Rust (del ejemplo anterior) con el conector IRIS en el Docker. En Dockerfile simple se puede construir una imagen con la aplicación.
FROM ekidd/rust-musl-builder
ADD --chown=rust:rust . ./
RUN cargo build --release --example main
FROM scratch
COPY --from=0 /home/rust/src/target/x86_64-unknown-linux-musl/release/examples/main /
CMD [ "/main" ]
Vamos a crearla
$ docker build -t rust-irisnative .
Y la ejecutamos
$ docker run -it rust-irisnative
Connection established
Server: IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2020.4 (Build 524U) Thu Oct 22 2020 13:04:25 EDT
^A("1") = "1"
^A("1", "2") = "test"
^A("2") = "<UNDEFINED>"
^A("2", "1") = "21test"
^A("3") = "<UNDEFINED>"
^A("3", "1") = "test31"
Test.NewProduction
dc.Demo.Production
Si te preguntas qué tamaño tiene esa imagen:
$ docker images rust-irisnative
REPOSITORY TAG IMAGE ID CREATED SIZE
rust-irisnative latest 0b1e54e7aa6f 2 minutes ago 3.92MB
Solo unos pocos megabytes de la imagen pueden conectarse a IRIS, que se ejecuta en otro lugar. Parece que es muy bueno para los microservicios y las aplicaciones sin servidor. Y como ventaja para el IoT, las aplicaciones de Rust pueden ejecutarse en pequeños PCs, por ejemplo, RaspberyPi Pico. ¿Qué te parece y cómo utilizarías Rust?
Artículo
Dani Fibla · 14 sep, 2021
Spring Boot es el *framework* de Java más utilizado para crear APIs REST y microservicios. Se puede utilizar para implementar sitios webs o webs ejecutables o aplicaciones de escritorio independientes, donde la aplicación y otras dependencias se empaquetan juntas. Springboot permite realizar muchas funciones, como:
Nota: para saber más sobre SpringBoot, consulta el sitio oficial: https://spring.io/quickstart
Para crear una aplicación web API , con uno o más microservicios, puedes utilizar Spring IDE para Eclipse o VSCode, y utilizar un asistente para configurar las tecnologías anteriores que se utilizarán en tu aplicación, mira:
.png)
Seleccionas las tecnologías y creas el proyecto. Todas las tecnologías se importarán utilizando Maven. Esto es como un ZPM visual.
El proyecto creado tiene una clase para subir la aplicación con todo lo que necesitas dentro de ella (servidor web y de aplicaciones, y todas las dependencias, concepto de microservicio).
El código fuente completo de este proyecto se encuentra en el proyecto de Open Exchange: https://openexchange.intersystems.com/package/springboot-iris-crud.
Lo primero que hay que hacer es configurar el controlador de JDBC en IRIS y el soporte IRIS Hibernate. Para ello, copia los archivos jar en la carpeta de recursos:
.png)
Abre pom.xml para configurar las dependencias de estos archivos jar.:
com.intersystems
intersystems-jdbc
3.2.0
system
${project.basedir}/src/main/resources/intersystems-jdbc-3.2.0.jar
org.hibernate
hibernate-iris
1.0.0
system
${project.basedir}/src/main/resources/hibernate-iris-1.0.0.jar
Ahora puedes configurar tu conexión con la base de datos de IRIS en application.properties, de la siguiente forma:
spring.datasource.username=_SYSTEM
spring.datasource.url=jdbc:IRIS://iris:1972/USER
spring.datasource.password=SYS
spring.jpa.properties.hibernate.default_schema=dc_Sample
#spring.jpa.hibernate.ddl-auto=update
spring.datasource.driver-class-name=com.intersystems.jdbc.IRISDriver
spring.jpa.properties.hibernate.temp.use_jdbc_metadata_defaults = false
spring.jpa.database-platform=org.hibernate.dialect.InterSystemsIRISDialect
spring.datasource.sql-script-encoding=utf-8
server.tomcat.relaxed-query-chars=|,{,},[,]
spring.jpa.show-sql=false
spring.jpa.properties.hibernate.format_sql=true
El siguiente paso consiste en crear un mapeo de la clase Persistent de Java en una tabla de IRIS:
package community.intersystems.springboot.app.model;
import java.io.Serializable;
import java.util.Date;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
import com.fasterxml.jackson.annotation.JsonFormat;
@Entity
@Table(name = "Product")
public class Product implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue (strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String description;
private Double height;
private Double width;
private Double weight;
@Column(name="releasedate")
@Temporal(TemporalType.DATE)
@JsonFormat(pattern = "dd/MM/yyyy")
private Date releaseDate;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public Double getHeight() {
return height;
}
public void setHeight(Double height) {
this.height = height;
}
public Double getWidth() {
return width;
}
public void setWidth(Double width) {
this.width = width;
}
public Double getWeight() {
return weight;
}
public void setWeight(Double weight) {
this.weight = weight;
}
public Date getReleaseDate() {
return releaseDate;
}
public void setReleaseDate(Date releaseDate) {
this.releaseDate = releaseDate;
}
}
El último paso es crear una interfaz en el Repositorio para exponer tu clase persistente como un servicio REST (en el patrón HATEOAS). Con operaciones CRUD, no necesitas escribir esto, solo:
package community.intersystems.springboot.app.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import community.intersystems.springboot.app.model.Product;
public interface ProductRepository extends JpaRepository<Product, Long> {
}
Ahora, ejecutas tu aplicación como una aplicación Spring Boot:
.png)
Espera al servidor interno y abre localhost:8080. Spring boot abrirá un navegador API REST HAL. Mira este gif animado:

Consulta más detalles en mi aplicación de muestra. Lo empaqueto todo junto en un proyecto Docker con 2 servicios: IRIS y SpringBoot.
El patrón HATEOAS es muy agradable para las API URL , la ruta y la navegación. Puedes conocer más detalles en: https://en.wikipedia.org/wiki/HATEOAS
¡Espero que os resulte útil!
Artículo
Ricardo Paiva · 16 jul, 2021
Surgió una pregunta en la Comunidad de Desarrolladores de InterSystems sobre la posibilidad de crear una interfaz TWAIN para una aplicación Caché. Hubo varias sugerencias excelentes sobre cómo obtener datos de un dispositivo de imágenes en un cliente web a un servidor y después almacenar estos datos en una base de datos.
Sin embargo, para implementar cualquiera de estas sugerencias, se debe poder transferir datos desde un cliente web a un servidor de base de datos y almacenar los datos recibidos en una propiedad de clase (o una celda de tabla, como fue el caso en la pregunta). Esta técnica puede ser útil no solo para transferir datos de imágenes recibidos desde un dispositivo TWAIN, sino también para otras tareas como organizar un archivo, compartir una imagen, etc.
Por lo tanto, el objetivo de este artículo es mostrar cómo escribir un servicio RESTful para obtener datos del cuerpo de un comando HTTP POST, ya sea en un estado sin procesar o envuelto en una estructura JSON.
Conceptos básicos de REST
Antes de ir a los detalles, empezaremos hablando sobre REST en general y sobre cómo se crean los servicios RESTful en IRIS.
Unaa Transferencia de EStado Representacional (REST) es un estilo arquitectónico para sistemas hiper-media distribuidos. La abstracción clave de información en REST es un recurso que tiene su identificador adecuado y se puede representar en JSON, XML u otro formato conocido tanto por el servidor como por el cliente.
Por lo general, HTTP se usa para transferir datos entre el cliente y el servidor. Cada operación CRUD (crear, leer, actualizar, eliminar) tiene su propio método HTTP (POST, GET, PUT, DELETE), mientras que cada recurso o colección de recursos tiene su propio URI.
En este artículo, usaré solo el método POST para insertar un nuevo valor en la base de datos, por lo que necesito conocer sus restricciones.
POST no tiene ningún límite en el tamaño de los datos almacenados en su cuerpo de acuerdo con la especificación IETF RFC7231 4.3.3 Post. Pero los distintos navegadores y servidores web imponen sus propios límites, normalmente de 1 MB a 2 GB. Por ejemplo, Apache permite un máximo de 2 GB. En cualquier caso, si necesitas enviar un archivo de 2 GB, quizá deberías reconsiderar tu enfoque.
Requisitos para un servicio RESTful en IRIS
En IRIS, para implementar un servicio RESTful, debes:
Crear un intermediario de clases que amplíe la clase abstracta %CSP.REST. Esto, a su vez, extiende %CSP.Page, y hace posible acceder a diferentes métodos, parámetros y objetos útiles, en particular %request).
Especificar el UrlMap para definir rutas.
Opcionalmente, configurar el parámetro UseSession para especificar si cada llamada REST se ejecuta en su propia sesión web o comparte una sola sesión con otras llamadas REST.
Proporcionar métodos de clase para realizar las operaciones definidas en rutas.
Definir la aplicación web CSP y especificar su seguridad en la página de la aplicación web (Administración del sistema> Seguridad> Aplicaciones> Aplicaciones web), donde la clase Dispatch debe contener el nombre de la clase de usuario y el Nombre, la primera parte de la URL para la llamada REST.
En general, hay varias formas de enviar grandes cantidades de datos (archivos) y sus metadatos de cliente a servidor, como:
Codificación en Base64 del archivo y los metadatos y añadir una sobrecarga de procesamiento tanto al servidor como al cliente para la codificación / descodificación.
Primero enviar el archivo y devolver una identificación (ID) al cliente, que luego enviará los metadatos con la identificación. El servidor vuelve a asociar el archivo y los metadatos.
Enviar primero los metadatos y devolver una identificación (ID) al cliente, que luego envía el archivo con la identificación, y el servidor vuelve a asociar el archivo y los metadatos.
En este primer artículo, básicamente tomaré el segundo enfoque, pero sin devolver la identificación (ID) al cliente y sin añadir los metadatos (el nombre del archivo para almacenar como otra propiedad) porque no hay nada excepcional en esta tarea. En un segundo artículo, usaré el primer enfoque, pero empaquetaré mi archivo y metadatos (el nombre del archivo) en una estructura JSON antes de enviarlo al servidor.
Implementación del servicio RESTful
Ahora vayamos a los detalles. Primero, vamos a definir la clase, cuyas propiedades configuraremos:
Class RestTransfer.FileDesc Extends %Persistent
{
Property File As %Stream.GlobalBinary;
Property Name As %String;
}
Por supuesto, normalmente tendrás más metadatos para el archivo, pero esto debería ser suficiente para nuestros propósitos.
A continuación, necesitamos crear un intermediario de clase, que luego expandiremos con rutas y métodos:
Class RestTransfer.Broker Extends %CSP.REST
{
XData UrlMap
{
<Routes>
</Routes>
}
}
Y, por último, para la configuración preliminar, necesitamos especificar esta aplicación en una lista de aplicaciones web:
Ahora que la configuración preliminar está hecha, podemos escribir métodos para guardar un archivo recibido de un cliente REST (usaré el Advanced REST Client) en una base de datos como una propiedad de archivo de una instancia de la clase RestTransfer.FileDesc.
Comenzaremos trabajando con información almacenada como datos sin procesar en el cuerpo del método POST. Primero, añadiremos una nueva ruta a UrlMap:
<Route Url="/file" Method="POST" Call="InsertFileContents"/>
Esta ruta especifica que cuando el servicio recibe un comando POST con URL / RestTransfer / file, debe llamar al método de clase InsertFileContents. Para facilitar las cosas, dentro de este método crearé una nueva instancia de una clase RestTransfer.FileDesc y estableceré su propiedad File en los datos recibidos. Esto devuelve el estado y un mensaje con formato JSON indicando éxito o error. Aquí está el método de la clase:
ClassMethod InsertFileContents() As %Status
{
Set result={}
Set st=0
set f = ##class(RestTransfer.FileDesc).%New()
if (f = $$$NULLOREF) {
do result.%Set("Message","Couldn't create an instance of the class")
} else {
set st = f.File.CopyFrom(%request.Content)
If $$$ISOK(st) {
set st = f.%Save()
If $$$ISOK(st) {
do result.%Set("Status","OK")
} else {
do result.%Set("Message",$system.Status.GetOneErrorText(st))
}
} else {
do result.%Set("Message",$system.Status.GetOneErrorText(st))
}
}
write result.%ToJSON()
Quit st
}
Primero, crea una nueva instancia de la clase RestTransfer.FileDesc y comprueba que se creó correctamente y tenemos un OREF. Si el objeto no se pudo crear, formamos una estructura JSON:
{"Message", "Couldn't create an instance of class"}
Si se creó el objeto, el contenido de la solicitud se copia en la propiedad Archivo. Si la copia no fue exitosa, formamos una estructura JSON con una descripción del error:
{"Message",$system.Status.GetOneErrorText(st)}
Si el contenido fue copiado, guardamos el objeto, y si se guarda de forma correcta, formamos un JSON {"Status", "OK"}. Si noo, el JSON devuelve una descripción del error.
Finalmente, escribimos el JSON en una respuesta y devolvemos el estado st.
Este es un ejemplo de cómo transferir una imagen:
Cómo se guarda en la base de datos:
Podemos guardar esta secuencia en un archivo y ver que se transfirió sin cambios:
set f = ##class(RestTransfer.FileDesc).%OpenId(4)
set s = ##class(%Stream.FileBinary).%New()
set s.Filename = "D:\Downloads\test1.jpg"
do s.CopyFromAndSave(f.File)
Lo mismo se puede hacer con un archivo de texto:
Esto también será visible en los globals:
Y podemos almacenar ejecutables o cualquier otro tipo de datos:
Podemos comprobar el tamaño en los globals, que es correcto:
Ahora que esta parte funciona como debería, echemos un vistazo al segundo enfoque: obtener el contenido del archivo y sus metadatos (el nombre del archivo) almacenados en formato JSON y transferidos en el cuerpo de un método POST.
Hay más información sobre la creación de servicios REST en la documentación de InterSystems.
El código de ejemplo para ambos enfoques está en GitHub y en InterSystems Open Exchange. Si tienes alguna pregunta o sugerencia relacionada con cualquiera de los dos, no dudes en escribirla en los comentarios.
Artículo
Ricardo Paiva · 20 mayo, 2025
Hace trece años, obtuve una doble titulación de grado en ingeniería eléctrica y matemáticas, y enseguida empecé a trabajar a tiempo completo en InterSystems sin utilizar ninguna de las dos. Una de mis experiencias académicas más memorables —y que más me revolvió el estómago— fue en Estadística II. En un examen, estaba resolviendo un problema de intervalo de confianza de dificultad moderada. Se me acababa el tiempo, así que (como buen ingeniero) escribí la integral definida en el examen, la introduje en mi calculadora gráfica, dibujé una flecha con la palabra “calculadora” encima y escribí el resultado. El profesor, conocido cariñosamente como “Dean, Dean, la máquina de suspensos”, me llamó a su despacho unos días después. No le hizo ninguna gracia que usara la calculadora gráfica. Me pareció injusto: al fin y al cabo, esto era Estadística II, no Cálculo II, y había hecho bien la parte de Estadística II… ¿no? Pues resultó que escribir “calculadora” sobre aquella flecha me hizo perder todos los puntos de la pregunta (aunque le sacó una risa a Dean); si no lo hubiese escrito, habría perdido todos los puntos del examen. Uff.
He recordado bastante este episodio últimamente. La inteligencia artificial generativa hace que mi TI-89 Titanium —decorada con pegatinas de estrellas por las buenas notas en mates en el instituto y modificada para jugar al Tetris— parezca un ladrillo de plástico caro. Bueno, lo era hace veinte años… y aún lo es.
Mi vieja y confiable TI-89 Titanium
Riesgos y normas
Con la llegada de entornos de desarrollo integrados (IDEs) con inteligencia artificial realmente buena, existe el potencial de que la IA pueda hacer el trabajo de un desarrollador de software principiante… ¿verdad? Si ese desarrollador principiante está usando Python —o algún otro lenguaje lo suficientemente común como para que los modelos hayan sido entrenados con él— entonces sí. Y si estáis cómodos con la deuda técnica de montañas de código que podrían ser auténtica basura —o peor aún, código mayormente correcto con pequeños fragmentos de auténtica basura escondidos— entonces sí. Y si tenéis algún medio místico para convertir desarrolladores principiantes en desarrolladores principales o arquitectos sin que escriban ni una sola línea de código, entonces también sí. Son muchas condiciones, y necesitamos establecer algunas reglas para mitigar estos riesgos.
Nota: estos riesgos son independientes de las preocupaciones sobre derechos de autor y propiedad intelectual que van en ambos sentidos: ¿estamos infringiendo código protegido por derechos de autor en los conjuntos de entrenamiento al usar el output de la IA generativa? ¿Estamos poniendo en riesgo nuestra propia propiedad intelectual al enviarla a la nube? Para este artículo, asumimos que ambas cuestiones están cubiertas por nuestra elección de modelo o proveedor de servicio, pero siguen siendo preocupaciones clave a nivel corporativo.
Regla #1: Alcance del trabajo
No uséis GenAI para hacer algo que no podríais hacer vosotros mismos, más allá o cerca de los límites de vuestra comprensión y capacidad actuales. Volviendo al ejemplo original: si estáis en Estadística II, podéis usar GenAI para hacer Cálculo II —pero no Estadística II, probablemente tampoco Estadística I, y desde luego no Teoría de la Medida. Esto significa que si sois becarios o desarrolladores de nivel inicial, no deberíais dejar que lo haga por vosotros. Usar GenAI como un “Google potenciado” está totalmente bien, y utilizar un autocompletado inteligente puede estar bien también, pero no dejéis que escriba código nuevo desde cero por vosotros.
Si sois desarrolladores sénior, usadlo para hacer trabajo de desarrollador de nivel inicial en tecnologías en las que tengáis un dominio a nivel sénior; pensad en ello como una delegación similar, y revisad el código como si lo hubiese escrito un desarrollador principiante. Mi experiencia con el desarrollo asistido por IA ha sido con Windsurf, que me gusta en ese sentido: he podido “entrenarlo” un poco, dándole reglas y consejos para que recuerde, siga y, como un desarrollador junior, a veces aplique en contextos erróneos.
Regla #2: Atribución
Si GenAI escribe un fragmento grande de código por vosotros, aseguraos de que el mensaje del compromiso, el propio código y cualquier documentación legible por humanos lo indiquen de forma muy clara. Que quede de manera clara: no lo habéis escrito vosotros, lo ha escrito una máquina. Esto es un favor para quienes revisen vuestro código: deberían tratarlo como si lo hubiese escrito un desarrollador principiante, no vosotros, y parte de la revisión debería consistir en cuestionar si la IA está haciendo cosas que van más allá de vuestro nivel técnico (lo cual podría estar mal —y no lo sabríais).
También es un favor para quienes revisen vuestro código en el futuro e intenten determinar si es una chapuza. Y es un favor para quienes intenten entrenar futuros modelos de IA con vuestro código, para evitar el colapso y los “defectos irreversibles en los modelos resultantes.”
Regla #3: Modo de aprendizaje y refuerzo
Cuando estáis en la universidad cursando Estadística II, tiene cierto valor reforzar las habilidades adquiridas en Cálculo II. Para ser sincero, ahora he olvidado la mayoría de ambas materias por falta de uso. Quizás “Dean, Dean la máquina de suspensos” tenía razón, después de todo. En situaciones donde vuestro objetivo principal es aprender cosas nuevas o reforzar habilidades recientes (¡o de hace años!), lo mejor es hacer todo el trabajo vosotros mismos. La creación rápida de prototipos es una excepción (¡aunque siguen aplicando las Reglas nº 1 y nº 2!), pero incluso en el trabajo diario habitual sería perjudicial depender en exceso de que GenAI se encargue de tareas “de desarrollador principiante”, tanto a nivel personal como organizacional.
Siempre necesitaremos desarrolladores de nivel inicial, porque siempre necesitaremos desarrolladores principales y arquitectos, y el camino entre ambos es una función continua. (¡Algo de matemáticas sí que recuerdo!)
Esto es algo que me encantaría ver como una función en los IDE: un modo “aprendizaje” que permita que la IA os observe o guíe, en lugar de hacer el trabajo por vosotros. En ausencia de una implementación específica en el software, también podéis optar por usar la IA de esta manera.
Rule #4: Reflexión
No os perdáis en el torbellino de trabajo, entregables y reuniones. Tomad tiempo para reflexionar. Esto es importante en general, y especialmente importante cuando usáis GenAI.
¿Está esta tecnología mejorando vuestra vida, o empeorándola?
¿Os está haciendo más inteligentes, o más torpes?
¿Estáis generando más valor, o simplemente más producción?
¿Incluye esa producción deuda técnica asumida por pura rapidez?
¿Estáis aprendiendo de forma más eficaz, o estáis olvidando cómo aprender?
¿Cómo se comparan las soluciones de la IA con las que teníais en mente? ¿Se os escapa algo que la IA detecta? ¿Pasa por alto la IA cosas que para vosotros son importantes de forma sistemática?
¿Os estáis convirtiendo en algo parecido a ChatGPT, introduciendo listas con viñetas y texto en negrita sin alma ni criterio en los documentos que escribís? (¡Oh no!)
Un último pensamiento: GenAI y el desarrollo basado en InterSystems IRIS
En un mundo donde los desarrolladores esperan que GenAI haga su trabajo por ellos —o al menos lo haga mucho más fácil— pueden ocurrir una de dos cosas:
Las tecnologías y lenguajes dominantes (véase: Python) pueden volverse super-dominantes, incluso si no son los mejores para la tarea en cuestión. Dado que GenAI es tan bueno con Python, ¿por qué usar algo más?
Las tecnologías y lenguajes de nicho (véase: ObjectScript) pueden volverse más atractivos para los desarrolladores. Aprender un nuevo lenguaje no es tan difícil si GenAI puede ayudaros a acelerar el proceso y hacerlo bien.
Mi esperanza es que, a medida que los proveedores y los líderes del desarrollo de software se den cuenta de los riesgos que he señalado, las herramientas tiendan a apoyar el segundo resultado, lo que representa una oportunidad para InterSystems. Sí, la gente puede usar Python incrustado para todo, pero nuestro legado tecnológico y las fortalezas de nuestra plataforma central también pueden volverse más atractivas, y ObjectScript puede recibir el reconocimiento que merece.
Pregunta
Laura Blázquez García · 19 feb, 2020
Hola.
Necesitamos llamar a un servicio y tenemos que encriptar la petición utilizando una clave pública. Tenemos un ejemplo de cómo realizar la llamada en PHP. También tenemos la clave pública y todos los parámetros que necesitamos. El ejemplo en PHP es éste y funciona (utiliza openssl):
$url = "https://XXXXX/";$json = '{"api_key":"XXXXX", "id":"1"}';$jsonEncrypt, = '';$publicKey = file_get_contents("public.key");openssl_get_publickey($publicKey);openssl_public_encrypt($json, $jsonEncrypt, $publicKey);$jsonEncrypt = base64_encode($jsonEncrypt);
Necesitamos hacer lo mismo en Ensemble. Escribí un post en la comunidad de InterSystems en inglés, y me dijeron que utilizase RSAEncrypt().
He probado esto:
set json = "{""api_key"":""XXXXX"", ""id"":""1""}"// Abrir el fichero de la clave pública:set file = ##class(%FileCharacterStream).%New()set file.Filename = "public.key"set key = file.Read(file.Size)// Encriptar el JSONset jsonEncrypt = $System.Encryption.RSAEncrypt(json, key)
Pero no funciona, me devuelve un string vacío. He buscado por todas partes y no sé por qué no funciona. La clave pública tiene este formato:
-----BEGIN PUBLIC KEY-----........................-----END PUBLIC KEY-----
Los saltos de línea son LF y está en UTF-8. En qué formato debe estar la clave pública para que funcione en Ensemble? Estoy haciendo algo mal?
Muchas gracias de antemano. Perdón, he conseguido obtener el error con RSAGetLastError(), y me devuelve esto:
error:0906D06C:PEM routines:PEM_read_bio:no start line; Hola Laura, tendría que mirar como usar esa función, pero una cosa que siempre puedes hacer ya que te funciona en openSSL es llamar directamente a OpenSSL. Échale un ojo a este ejemplo https://github.com/drechema/ensemble-smime También le echaría un ojo a este articulo para saber como llamar correctamente al método:
https://community.intersystems.com/post/format-public-key-when-using-rsaencrypt-method-systemencryption-or-systemencryptionrsaencrypt Gracias David.
Al final, dado que el comando de terminal funcionaba, esto es exactamente lo que hice, invocar el comando utilizando $ZF(-100, "openssl", ...). Con esto hemos conseguido que funcione. Entiendo que es una solución igualmente válida, no? Me hubiera gustado poder realizarlo con los métodos de clase de $System.Encryption, pero no lo he conseguido. He mirado este artículo y estoy invocando correctamente el método. Lo que sí he tenido que hacer es reconvertir la clave pública de pkcs#8 a pkcs#1 como indica en el artículo. Con eso consigo que encripte, aunque luego el sistema del proveedor me dice que no es válido, pero quizá sea que me falte/sobre algo. Seguiré probando a ver si consigo hacerlo funcionar.
Muchas gracias!
Artículo
Mathew Lambert · 28 feb, 2020
¡Hola Comunidad!
ObjectScript tiene al menos tres formas de manejar errores (códigos de estado, excepciones, SQLCODE, etc...). La mayor parte del código del sistema usa estados, pero las excepciones son más fáciles de manejar por varias razones. Al trabajar con código heredado, se invierte un tiempo en traducir las distintas técnicas. Yo uso mucho estos fragmentos de código como referencia. Espero que también os sean útiles.
///Status from SQLCODE:
set st = $$$ERROR($$$SQLError, SQLCODE, $g(%msg)) //embedded SQL
set st = $$$ERROR($$$SQLError, rs.%SQLCODE, $g(rs.%Message)) //dynamic SQL
///Exception from SQLCODE:
throw ##class(%Exception.SQL).CreateFromSQLCODE(SQLCODE,%msg) //embedded SQL
throw ##class(%Exception.SQL).CreateFromSQLCODE(rs.%SQLCODE,rs.%Message) //dynamic SQL
throw:(SQLCODE'=0)&&(SQLCODE'=100) ##class(%Exception.SQL).CreateFromSQLCODE(SQLCODE,%msg) //don't throw if query succeeds or finds no data
///Exception from status:
$$$ThrowOnError(st)
///Status from exception:
set st = err.AsStatus()
///Creating a custom error status:
set st = $$$ERROR($$$GeneralError,"Custom error message")
///Throwing a custom exception:
$$$ThrowStatus($$$ERROR($$$GeneralError,"Custom error message"))
///Handling a SOAP error with a status:
try {
//SOAP request code
} Catch err {
If err.Name["ZSOAP" {
Set st = %objlasterror
} Else {
Set st = err.AsStatus()
}
}
return st
///Defining a custom exception class
Class App.Exceptions.SomeException Extends %Exception.AbstractException
{
Method OnAsStatus() As %Status
{
return $$$ERROR($$$GeneralError,"Custom error message")
}
}
///Throwing and catching a custom exception
try {
throw ##class(App.Exceptions.SomeException).%New()
} catch err {
if err.%ClassName(1) = ##class(App.Exceptions.SomeException).%ClassName(1) {
//some handling unique to this type of exception
}
} Genial, muy útil! Información realmente útil. La gestión de errores reduce en gran medida la complejidad de un código. Esos números mágicos como el retorno de error son una pesadilla. muy bueno
Este artículo está etiquetado como "Mejores prácticas" ("Best practices")
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems.
Artículo
Alberto Fuentes · 23 feb, 2021
Hola a todos! Os comparto hoy un artículo sobre la utilización del **procesamiento de lenguaje natural** y su combinación con **FHIR** donde se muestra un chatbot que interactúa con FHIR desarrollado por [Renato Banzai](https://community.intersystems.com/user/renato-banzai).
## ¿Qué significa PLN?
PLN significa Procesamiento del Lenguaje Natural (NLP en inglés) y es un campo de la Inteligencia Artificial muy complejo que utiliza técnicas para, en pocas palabras, “entender de qué se está hablando”.
## ¿Y qué es FHIR?
FHIR significa *Fast Healthcare Interoperability Resources* y es un estándar que describe estructuras de datos y operaciones que puedes realizar sobre ellas en aplicaciones de salud. En la Comunidad de Desarrolladores hay varios artículos que explican mejor cómo interactúa FHIR con InterSystems IRIS. Aquí incluso publicamos un [Webinar: Comienza a Trabajar con FHIR](https://comunidadintersystems.com/webinar-comienza-a-trabajar-con-fhir)
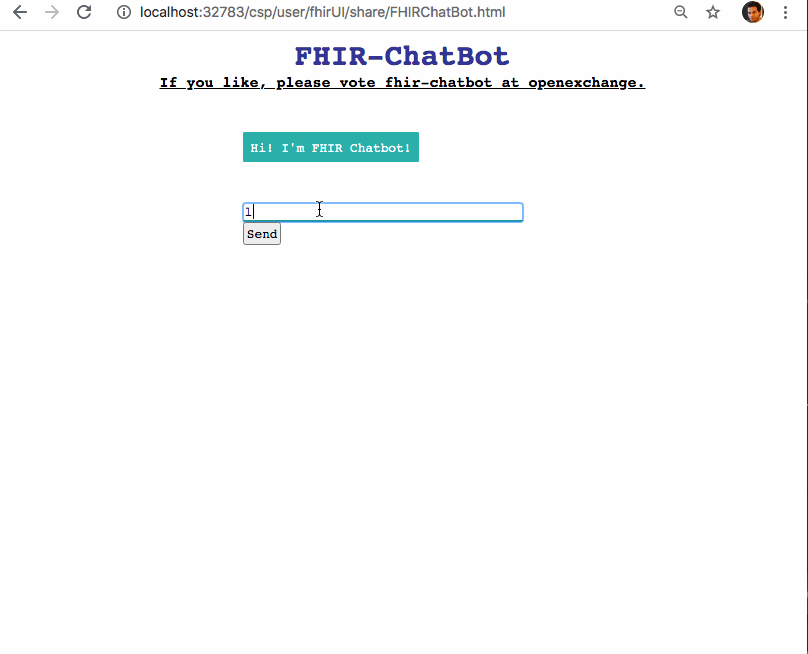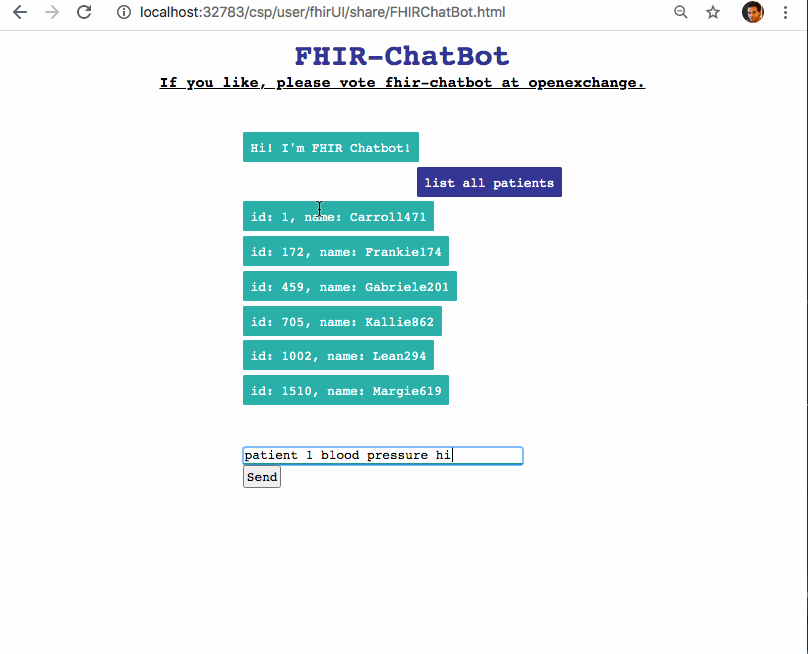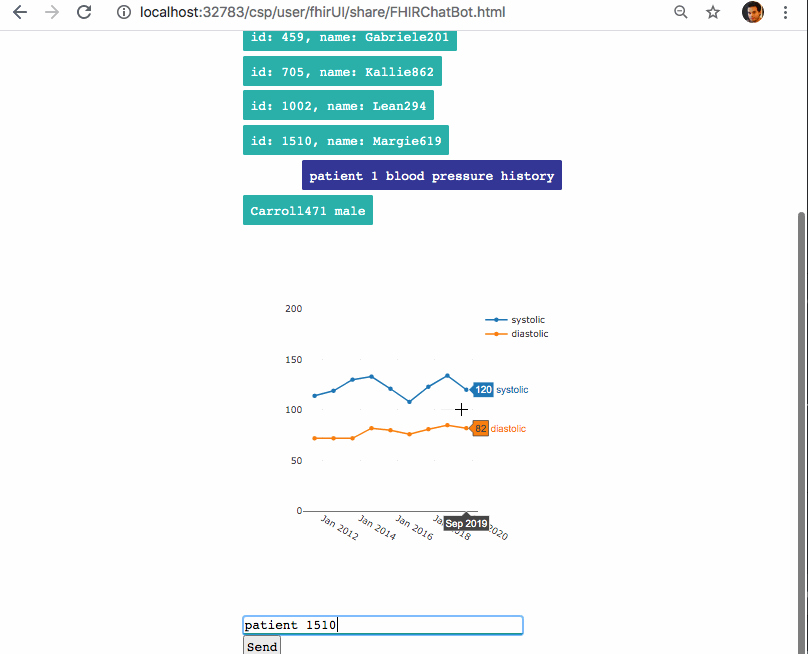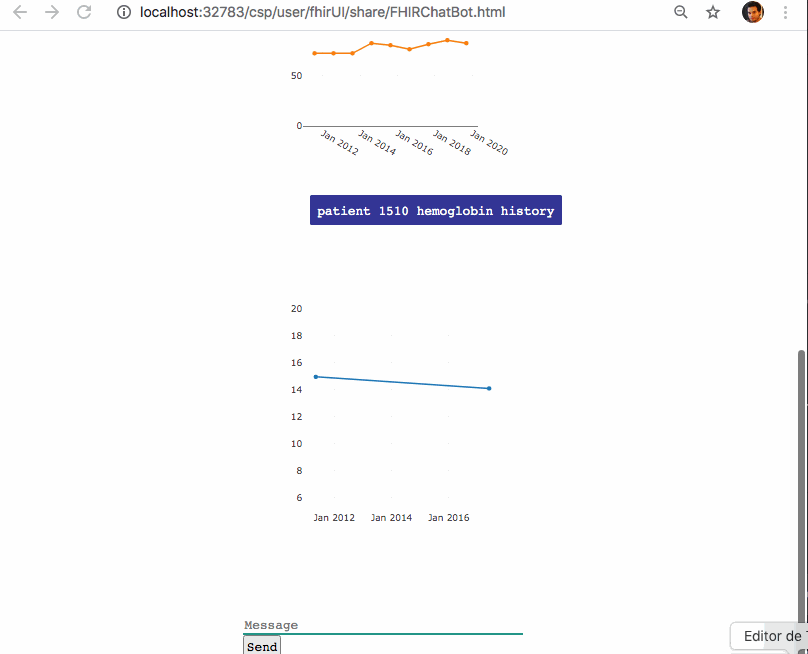
## Un chatbot para consultar FHIR
El método más común en los chatbots es utilizar *machine learning* para enseñar al modelo a través de conversaciones de entrenamiento. Pero cuando el chatbot necesita utilizar información en tiempo real, el desafío es mayor. Si conoces cómo funciona un modelo de *machine learning*, ya sabes que en la mayoría de los casos el modelo entrenado es una especie de aplicación con todas las decisiones integradas en su interior. Si necesitas más información sin tener que enseñar nuevamente al modelo, tendrás que crear tú mismo las integraciones y dedicar una parte de tu esfuerzo al "machine learning" y otra parte a la ingeniería del software.
## Primera aproximación
Para mostrar mejor cómo funciona FHIR en esta aplicación se decidió trabajar primero en las preguntas que un profesional sanitario podría hacerle a un chatbot. Para ello, se hizo que la ingeniería del software fuera sencilla utilizando solamente javascript y expresiones regulares con las que se buscan objetivos y estructuras en el chat.
Recordad que en la Comunidad también publicamos otro contenido con un ejemplo de chatbot donde se utilizaban otras alternativas: [Webinar: Desarrolla un chatbot con Google Dialogflow, Telegram e IRIS](https://comunidadintersystems.com/webinar-desarrolla-un-chatbot).
## Expresiones regulares

Las expresiones regulares son una forma muy potente de trabajar con textos y de buscar coincidencias en los patrones. Con las expresiones regulares puedo buscar cuál es el paciente sobre el que quiere tener información la persona que está chateando y qué pregunta o historial médico desea consultar.
Artículo
Mario Sanchez Macias · 26 sep, 2019
¡Hola a todos!
En esta publicación me gustaría hablar sobre la tabla syslog: qué es, cómo analizarla, cuáles son realmente las entradas y por qué puede ser importante para usted. La tabla syslog puede contener información de diagnóstico importante. Si su sistema tiene algún problema, es importante entender cómo analizar esta tabla y qué información contiene.
¿Qué es una tabla syslog?
Caché reserva una pequeña porción de su memoria compartida para registrar elementos importantes. Esta tabla tiene varios nombres diferentes:
errlog
SYSLOG
tabla syslog
Para cumplir con el propósito de esta publicación, simplemente la llamaré 'tabla syslog'.
El tamaño de la tabla syslog puede configurarse. El valor predeterminado es de 500 entradas. El intervalo es de 10 a 10,000 entradas. Para cambiar el tamaño de la tabla syslog ve al Portal de administración y entra en Administración -> Configuración -> Configuración adicional-> Memoria avanzada y en la fila ‘errlog’ selecciona ‘editar’ e introduce el número de entradas deseado para la tabla syslog.
¿Por qué se quiere cambiar el tamaño de la tabla syslog?
Si la tabla syslog se configura para 500 entradas, en la entrada 501 se sobrescribirá la primera entrada, y esa información se perderá. Esta tabla se encuentra en la memoria y por lo tanto no persiste en ningún lugar, a menos que la salida se guarde de manera específica. Además, cuando se paré Caché, todas las entradas se perderán a menos que se configure para guardar las entradas en el archivo cconsole.log, como se describe a continuación.
Si Caché introduce muchas entradas en la tabla syslog, y necesitas analizarlas para ayudar a diagnosticar cualquier problema, se perderán las entradas si la tabla no es lo suficientemente grande. Puedes analizar la columna Fecha/Hora que se encuentra en la tabla de syslog para determinar el periodo de tiempo que lleva llenar la tabla. Esto te ayudará para decidir cuántas entradas necesitas. A mí me gusta tener controlada la tabla y aumentarla para no perder ninguna entrada.
¿Cómo puedo analizar la tabla syslog?
Existen varias maneras de analizar la tabla syslog:
Desde una línea de comandos en el terminal de Caché en el namespace %SYS, ‘Do ^SYSLOG’
Desde una línea de comandos en el terminal de Caché en el namespace %SYS, ‘do ^Buttons’
Desde el Portal web de administración : Operaciones -> Informes de diagnóstico
Ejecutando cstat con la opción -e1
Ejecutando Cachehung
Configurando Caché para volcar la tabla syslog en el archivo cconsole.log al apagar el sistema. Para hacer esto entra en el Portal de administración web y ve a Administración -> Configuración -> Configuración adicional -> Compatibilidad, en la fila 'ShutDownLogErrors', selecciona 'editar' y activa el check ('true') para guardar el contenido de syslog en cconsole.log cuando se paré Caché.
¿Qué significan las entradas de syslog?
A continuación, se muestra un ejemplo de la tabla syslog. Este ejemplo se origina de la ejecución de ^SYSLOG en la línea de comandos del terminal de Caché:
%SYS>d ^SYSLOG
Device:
Right margin: 80 =>
Show detail? No => No
Cache System Error Log printed on Nov 02 2016 at 4:29 PM
--------------------------------------------------------
Printing the last 8 entries out of 8 total occurrences.
Err Process Date/Time Mod Line Routine Namespace
9 41681038 11/02/2016 04:44:51PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:43:34PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:42:06PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:41:21PM 93 5690 systest+3^systest %SYS
9 41681038 11/02/2016 04:39:29PM 93 5690 systest+3^systest %SYS
9 41681036 11/02/2016 04:38:26PM 93 5690 systest+3^systest %SYS
9 41681036 11/02/2016 04:36:57PM 93 5690 systest+3^systest %SYS
9 41681036 11/02/2016 04:29:45PM 93 5690 systest+3^systest %SYS
Puede parecer evidente, según los títulos de las columnas, el significado de cada uno de los elementos de una entrada, pero los describiré todos.
Printing the last 8 entries out of 8 total occurrences
Aunque esto no es parte de una entrada en la tabla syslog, es algo importante que se debe considerar, así que lo mencionaré. Aquí es donde se mira para encontrar cuántas entradas contiene la tabla syslog. En este ejemplo, solo se generaron 8 entradas desde que se inició Caché. Este es mi sistema de pruebas, así que tiene muchas entradas. Si aparece ‘Printing the last 500 entries out of 51234 total occurrences’ sabrás que se han perdido muchas entradas. En estos casos, aumenta el tamaño de la tabla hasta un máximo de 10,000 (si se está interesado en ver estas entradas) o ejecuta SYSLOG con mayor frecuencia.
Err
Esta es la información que registramos sobre el evento de interés. Normalmente suele ser un error a nivel del sistema operativo (SO), para encontrar qué error de SO se refiere tienes dos opciones:
En Linux/Unix: los números de error se suelen encuentran en /usr/include/errno.h.
En Windows pueden consultarse con >net helpmsg <numero>.
Pero no siempre es de SO y también podría ser cualquier otra cosa que necesitamos registrar. Por ejemplo, podría contener información de depuración para para un valor determinado de una variable interna o nuestros propios código de de error (cualquier cosa mayor a 10,000).
Pero ¿Cómo se puede saber qué es? Para saber qué es, debemos analizar la línea de código fuente que se indica mediante "mod" y "line". En la práctica, esto significa que no es posible encontrar ese detalle sin contactar a InterSystems. ¿Entonces, por qué molestarse en analizarlo? Bueno, existen muchas cosas que puede averiguar sin saber exactamente lo que es err, echando un vistazo a otro tipo de información. Además, puedas ponerte en contacto con InterSystems si ves que existen muchas entradas, o entradas diferentes a las entradas que normalmente ves en un sistema saludable.
Por otro lado, hay que tener también en cuenta que una entrada en la tabla syslog no siempre implica un error. (Pueden aparecer mensajes de desconexión, fichero no encontrado, etc... que no son realmente errores si están controlados).
Process
Este es el ID del proceso que introdujo la entrada en la tabla syslog. Por ejemplo, si tienes un proceso bloqueado, en loop o muerto, puedes analizar la tabla syslog para consultar si existe algún registro. Si lo hizo, probablemente será una pista importante de por qué el proceso tuvo problemas.
Date/Time
Esta es la fecha y la hora en que se realizó la entrada. Es muy importante correlacionar la fecha y la hora de la entrada con la de cualquier evento del sistema, porque con frecuencia es una pista de lo que salió mal.
Mod y Line
Mod corresponde a un archivo específico en C, y line es el número de línea en ese archivo que introdujo la entrada en la tabla syslog. Solo el personal de InterSystems que cuenta con acceso al código del kernel puede buscarlo. Solo buscando este código se puede saber exactamente lo que se registra en la entrada.
Routine
Las etiquetas, el offset y la rutina que el proceso estaba ejecutando cuando se llevo a cabo la entrada en la tabla syslog. Esto puede ayudar a averiguar lo que ocurre.
Namespace
Este es el namespace en el que se ejecutó el proceso.
Por tanto ¿cómo puedo determinar por qué err 9 está en mi tabla syslog?
Primero, analizamos la rutina indicada. Esta es la rutina ^systest del ejemplo anterior:
systest ;test for syslog post
s file="/home/testfile"
o file:10
u file w "hello world"
c file
q
La entrada de syslog indica que systest+3 es lo que se ejecutó cuando se llevo a cabo la entrada. Esta línea es:
u file w "hello world"
Dado que el proceso intentaba escribir en un archivo, esto podría ser un error a nivel de sistema operativo (OS), así que buscamos el código de error 9 en /usr/include/errno.h y encontramos:
#define EBADF 9 /* Bad file descriptor */
Dado que 9 está relacionado con los archivos y la línea de código intenta escribir en un archivo, es razonable suponer que realmente se trata de un error en el código devuelto por el sistema operativo.
¿Podemos determinar qué está mal?
Para resolver esto, primero analizamos los permisos que se encuentran en el directorio /home y en el archivo de prueba. Ambos eran 777, así que realmente debió ser capaz de abrir y escribir en ese archivo. Al analizar más de cerca el código nos damos cuenta de un error. Antes de los dos puntos del tiempo de espera de diez segundos se necesita utilizar algunos parámetros en el comando open. A continuación, se muestra la rutina actualizada que realmente termina sin errores y se escribe en el archivo:
systest ;test for syslog post
s file="/scratch1/yrockstr/systest/testfile"
o file:"WNSE":10
u file w "hello world"
c file
q
Resumen
La tabla syslog es una herramienta valiosa para depurar si se utiliza correctamente. Hay que tener en cuenta lo siguiente cuando se utilice:
err no siempre es un error del sistema operativo. Pónte en contacto con InterSystems para conocer lo en detalle lo que se ha registrado.
Utiliza otros datos relacionados para determinar lo que sucede. La línea del código COS combinada con el error puede ofrecer una suposición razonable de si es un error del sistema operativo o nuestro código.
Realiza búsquedas en la tabla syslog cada vez que tengas un problema que no puedas resolver, es posible que la pista esté allí.
Utilice la Date/Time, el número de entradas y el total de sucesos para determinar si necesita aumentar el tamaño de su tabla de syslog
Conoce lo que tu sistema registra en la tabla syslog para controlar si se producen cambios o entradas nuevas o diferentes
Las entradas en la tabla syslog no necesariamente son un problema. El tenerlas controladas es la clave
Artículo
Eduardo Anglada · 27 mayo, 2021
En este artículo voy a mostrar los resultados de una comparación entre IRIS y Postgress manejando datos Astronómicos.
Introducción
Desde siempre el cielo nocturno nos ha fascinado. Todos hemos soñado con las estrellas y la posibilidad de que haya vida en otros planetas.
Los astrónomos llevan siglos identificando y clasificando estrellas. Existen catálogos compilados en Mesopotamia y Egipto desde el siglo 2 AC [1]. Durante siglos se han ido compilando catálogos nuevos y recientemente hay dos que sobresalen del resto: Hipparcos [2] y Gaia [3]. Ambos han sido elaborados por la Agencia Europea del Espacio (ESA) que construyó naves espaciales dedicadas al mapeo y caratacterización de estrellas y meteoritos.
Hipparcos fue un proyecto pionero, lanzado en 1989, y permitió determinar la posición de cien mil estrellas con mucha precisión y un millón con una menor precisión. En el año 2000 se publicó el catálogo definitivo que aumentó el número de estrellas a 2.5 millones e incluye el 99% de las estrellas cuya magnitud (medida de brillo sin unidades, ver [4]) es menor que 11. Este catálogo se sigue usando mucho hoy en día.
En 2013 ESA lanzó Gaia [4], una nueva nave espacial dedicada al mapeo de la Vía Láctea y, por supuesto, cualquier otra estrella que detecte. No sólo calcula sus posiciones, también sus velocidades y muchos otros parámetros físicos: brillo en las bandas del rojo y azul, temperaturas superficiales, luminosidad, radio e incluye miles de meteoritos del Sistema Solar. En total el catálogo cuenta con unas 100 columnas que describen las diferentes propiedades y sus errores correspondientes. Todas las estrellas se han clasificado usando el mismo criterio y precisión, pero solo un subconjunto tiene los datos completos. Para el resto, por desgracia, son desconocidos. Durante años los científicos han trabajado duro para que los datos sean lo más fiables posibles.
A lo largo de los años ESA ha publicado varias versiones del catálogo de Gaia y en esta comparativa vamos a usar la versión 2, que es la primera que incluye los resultados para 1.6 billones de estrellas y varios cientos de miles de meteoritos. Los catálogos de Gaia se han usado en miles de artículos científicos.
Los catálogos de Gaia están redifiniendo la astronomía y son un salto cualitativo, tanto en calidad como en calidad, en comparación con los de Hipparcos. Ambos son abiertos y se pueden consultar y descargar desde el servicio de archivos [5]. El Centro Europeo de Astronomía Espacial (ESAC son sus siglas en inglés) es el encargado de custodiar y publicar los catálogos, que están disponibles tanto para la comunidad científica como para el público en general. Para reproducir los resultados se pueden descargar los datos desde el archivo oficial: Gaia Archive (esa.int)
Representación del área de la Vía Láctea que está siendo estudiada por Gaia. (Reproducido gracias a la Licencia Creative Commons By Attribution 4.0 license. Credit: "galaxymap.org, Twitter: @galaxy_map").
Gaia pretende cubrir en torno al 1-2 por ciento de las estrellas de la Galaxia.
Cache e IRIS en el procesado de datos diarios de Gaia
La nave Gaia se encuentra en el punto de Lagrange L2 definido por la Tierra y el Sol, a unos 1.5 millones de kilómetros de la Tierra. Siempre está girando y tomando datos, que se reciben en la Tierra usando las antenas localizadas en Cebreros (Ávila, España), New Norcia (Australia) y Malargüe (Argentina). Cada antena envía los datos a Alemania, donde el Centro de Operaciones de Misiones (MOC, en inglés) recibe la telemetría consistente en los datos científicos y los del estado de la nave. El MOC comprueba el estado de la nave y envía los datos científicos al Centro de Operaciones Científicas (SOC en inglés) en ESAC (Madrid). El promedio diario de datos que recibe el SOC son 40GB, pero fluctúa bastante y puede llegar a los 110GB cuando Gaia está observando el plano de la Galaxia.
InterSystems Caché juega un papel fundamental en el análisis diario de los datos. Gracias a sus capacidades Caché permite acceder en línea a bases de datos de 40TB. Después de ser recibida la telemetría se descomprime e ingesta en InterSystems Caché. El análisis de los datos y las imágenes es llevado a cabo por diferentes programas, pero todos ellos emplean la instancia de Caché para almacenar y leer los resultados. El análisis preliminar de los resultados se tiene que llevar a cabo en menos de 24h para poder crear una alerta científica si, por ejemplo, explotase una Supernova. Caché es capaz de almacenar todos los datos del análisis y gracias a su velocidad y resilencia el SOC es capaz de llevar a cabo su trabajo muy satisfactoriamente. En la actualidad se está llevando a cabo la migración a InterSystems IRIS, la nueva evolución de Caché.
Además los científicos determinan el estado de los diferentes instrumentos y la calidad científica de los resultados. Estos son enviados al resto de centros encargados de su procesamiento (DPAC in inglés), formado por universidades, centros de investigación y observatorios. Los resultados de los estudios realizados por estos centros se guardan en ESAC y se publican como los diferentes catálogos de Gaia.
Rendimiento de IRIS
Vamos a comparar el rendimiento de InterSystems IRIS 2020.1 contra Postgress 12 usando los datos del catálogo Gaia DR2 que han sido descargados en formato CSV del archivo oficial Gaia Archive (esa.int).
Como el catálogo ocupa 1.1 TB y no disponemos de espacio suficiente solo usamos 99GB correspondiente a los archivos CSV cuyo nombre sigue este patrón: Gaia_Source_1*.csv.
En este repositorio de github se pueden encontrar las instrucciones completas para reproducir estos resultados.
Preparación
Servidor: Ubuntu 20.04 con los últimos parches. 32GB of RAM. Procesador: i7-4790 @ 4.00 GHz 4 cores físicos.
Disco: Sabrent 1TB NVME
Herramienta empleada para llevar a cabo las consultas: DBeaver 21.0.1, usa un driver jdbc apropiado para cada instancia.
IRIS: versión 2020.1, empleando10GB of RAM y archivos de base de datos de 8K.
Postgres: versión 12, instalación por defecto de Ubuntu.
Ingestión de los datos
Los archivos descargados del archivo han sido concatenados en un único archivo.
Ingestión de 115453122 filas con información de las estrellas (94 columnas)
IRIS
Hemos utilizado la utilidad de IRIS SimpleDataTransfer (incluida en la distribución de IRIS). Esta herramienta usa el driver jdbc de IRIS para llevar a cabo la ingestión. Ésta se lleva a cabo en paralelo usando 10 trabajos que ingestan 200000 líneas cada uno.
Postgres
Hemos empleado pg_bulkload, que también corre en paralelo y escribe directamente en los archivos de la base de datos sin tener el equivalente a los archivos "journal" activos.
IRIS: 1525 s
Postgres: 2562 s
Consultas simples
Las siguientes consultas son simples y devuelven un conjunto de estrellas que cumplen un requisito dado:
Posiciones: estrellas con un error pequeño en la posición
La consulta es:
SELECT * FROM gdr2 WHERE parallax_over_error > 1000
Los resultados son:
IRIS: 645 filas .5 s
Postgres: 645 filas 108 s
Estrellas azules
Seleccionar aquellas estrellas con una emisión importante en el azul. La consulta es:
select count(*) from gdr2 where bp_rp < -2
Los resultados son:
IRIS: 515 filas 2ms
Postgres: 515 filas 150s
Estrellas con movimiento propio importante
Esta consulta devuelve aquellas estrellas con una velocidad transversal importante con respecto a la Tierra:
select * from public.gdr2 where (
pmra < -707.1
or pmra > 707.1
or pmdec < -707.1
or pmdec > 707.1
)
and sqrt(pmra * pmra + pmdec * pmdec) > 1e3
IRIS 94 filas 34 ms
PG 94 filas 153 s
Resultados de alta calidad (errores pequeños y un número significativo de observaciones)
Anthony Brown el líder de DPAC (el consorcio dedicado al tratamiento de los datos) tiene en su github varios ejemplos. Entre ellos destaca una consulta "simple" que recopila aquellas estrellas con errores pequeños:
select source_id, ra, ra_error, dec, dec_error, parallax, parallax_error, parallax_over_error, pmra,
pmra_error, pmdec, pmdec_error, ra_dec_corr, ra_parallax_corr, ra_pmra_corr, ra_pmdec_corr,
dec_parallax_corr, dec_pmra_corr, dec_pmdec_corr, parallax_pmra_corr, parallax_pmdec_corr,
pmra_pmdec_corr, radial_velocity, radial_velocity_error,
phot_g_mean_mag, phot_bp_mean_mag, phot_rp_mean_mag, bp_rp, g_rp, bp_g,
2.5/log(10)*phot_g_mean_flux_over_error as phot_g_mean_mag_error,
2.5/log(10)*phot_bp_mean_flux_over_error as phot_bp_mean_mag_error,
2.5/log(10)*phot_rp_mean_flux_over_error as phot_rp_mean_mag_error,
sqrt(astrometric_chi2_al/(astrometric_n_good_obs_al-5)) as uwe
from gaiadr2.gaia_source
where parallax_over_error>5
and radial_velocity is not null
and astrometric_params_solved=31
and rv_nb_transits > 3
Resultados
IRIS: En 14m 22s devuelve una lista con 736496 estrellas.
PG: Después de 20m sólo ha encontrado 495895 estrellas.
Mapa de la Galaxia con densidad de estrellas
Desde el año 2009 se publican en https://www.galaxymap.org una serie de mapas de la Vía Láctea. Incluyen mucha información, como un mapa de densidad de estrellas. Mediante isosuperficies (superficies 3D en las que la densidad de estrellas es constante) podemos explorar la Vía Láctea. La última versión emplea los datos de Gaia y el código fuente está disponible en github. Hemos llevado a cabo las mismas consultas en IRIS y Postgress:
SELECT source_id,designation , l , b , parallax , parallax_over_error , phot_g_mean_mag , bp_rp , priam_flags , teff_val , a_g_val FROM gdr2 WHERE ( parallax_over_error > 10 ) and (parallax >= 1.0) and (parallax < 1.1)
Resultados:
IRIS: 11m 49s
PG: timeout
Imagen ejemplo, los colores indican las zonas con una densidad de estrellas constante:
Tal y como indica el autor en su blog el archivo oficial de Gaia tiene un tiempo máximo por consulta de 30 minutos, por lo que el autor se vió obligado a realizar muchas consultas y tardó 24 h en obtener todos los datos. IRIS es mucho más rápido y permite obtener los datos en menos tiempo.
Aquí se puede ver una animación de las isosuperficies:
y una descripción completa de los resultados:
Todos los materiales empleados se distribuyen bajo la licencia: Creative Commons By Attribution 4.0. Crédito: "galaxymap.org, Twitter: @galaxy_map".
Conclusión
IRIS es una plataforma de datos robusta que puede gestionar sin problemas las consultas más complejas y a máxima velocidad.
References
[1] Ancient Star Catalogs. Star chart - Wikipedia
[2] ESA Hipparcos mission. Hipparcos - Wikipedia
[3] ESA Gaia mission. ESA Science & Technology - Gaia
[4] Magnitude: Star brightness. Magnitude (astronomy) - Wikipedia
[5] Parsec: Astronomy unit of length corresponding to 3.26 light years Parsec - Wikipedia
Pregunta
Yone Moreno · 21 sep, 2022
Buenos días,
💭🧱🧑💻 Hemos estado indagando y construyendo gracias al enorme apoyo, soporte, y asistencia ofrecida por el siguiente ejemplo:
https://es.community.intersystems.com/post/ejemplo-de-integraci%C3%B3n-dicom-con-un-simulador
Y del código de Github de los circuitos de ejemplo para el FIND y el MOVE:
https://github.com/intersystems-ib/iris-dicom-sample
Sería de agradecer si ustedes nos leen y responden a las siguiente cuestiones:
Desarrollando el MOVE, nos hemos encontrado con que en los primeros envíos sí se realiza y obtenemos respuesta:
MOVE
STORE
Sin embargo, ocurre algo único cuando se ejecutan varias veces el MOVE. El proceso genera una Excepción:
ERROR <Ens>ErrBPTerminated: Finalizando BP DICOM Move Process # debido a un error: ERROR <Ens>ErrException: <READ>zAcceptPDU+4^EnsLib.DICOM.Adapter.TCP.1 -- - registrado como '-' número - @''> ERROR <Ens>ErrException: <READ>zAcceptPDU+4^EnsLib.DICOM.Adapter.TCP.1 -- - registrado como '-' número - @''
¿De qué manera se podría entender y comprender la Excepción? Para depurarla posteriormente
En concreto para dar más información actualmente estamos simulando ser ORIGEN mediante:
./movescu -b VNAPRE -c ESBPRE@AA.BBB.C.DDD:2021 -m StudyInstanceUID="1.2.156.14702.1.1000.16.0.20200311113603875" --dest ESBPRE
Y además simulamos un DESTINO empleando para ello:
./dcmqrscp --ae-config ./shared/ae.properties -b VNAPRE:11118 --dicomdir ./shared/DICOMDIR
Siendo el circuito del MOVE:
Estamos empleando el código original de la clase DICOM.BP.MoveProcess publicado en el ejemplo:
https://raw.githubusercontent.com/intersystems-ib/iris-dicom-sample/master/iris/src/DICOM/BP/MoveProcess.cls
Además hemos tratado de emplear distintos puertos para DESTINO: 11114, 11116 11118 etc
Y ocurre de igual forma:
ERROR <Ens>ErrBPTerminated: Finalizando BP DICOM Move Process # debido a un error: ERROR <Ens>ErrException: <READ>zAcceptPDU+4^EnsLib.DICOM.Adapter.TCP.1 -- - registrado como '-' número - @''> ERROR <Ens>ErrException: <READ>zAcceptPDU+4^EnsLib.DICOM.Adapter.TCP.1 -- - registrado como '-' número - @''
🎓🔎🐞🩹🧑💻 ¿De qué manera se podría entender y comprender la Excepción? Para depurarla posteriormente 🔍
Muchas gracias de antemano por su tiempo
Un saludo
Hola Yone,
Podrían ser errores de red, o de timeouts durante la transferencia.
Echa un vistazo a [Tasks for DICOM Productions](https://docs.intersystems.com/healthconnect20221/csp/docbook/DocBook.UI.Page.cls?KEY=EDICOM_tasks), en particular a [Configuring a DICOM Duplex Business Host](https://docs.intersystems.com/healthconnect20221/csp/docbook/DocBook.UI.Page.cls?KEY=EDICOM_tasks#EDICOM_task_duplex_host_configure). Tienes varios configuraciones que quizá te ayuden como `TraceVerbosity`, `ARTIM`, `TXTIM ` para mostrar más o menos información y modificar ciertos *timeouts*.
También te puede servir lo que te dice el otro lado de la comunicación (lo que parece que es el simulador).
De todas formas, ten en cuenta que parece que estás trabajando con un simulador y a veces pueden tener ciertas limitaciones. Hola Alberto,
Gracias por indicarme los recursos y sobre todo agradezco que me especificaras en concreto qué propiedades aportan en este caso.
He configurado:
Seguimiento del nivel de detalle = 2
ARTIM = 20
TXTIM = 20
Y ahora sí se recibe la respuesta del Establecer conexión desde el Simulador ( Destino ) hacia la Operacion TCP Dicom ( Receptora )
Lo que sí es cierto, resulta que ocurre la excepción de forma similar, casi igual en el paso [6]; justo antes de recibir la Notificación de Conexión establecida por parte del SIMULADOR dcm4che hacia la Operacion del ESB:
ERROR <Ens>ErrBPTerminated: Finalizando BP DICOM Move Process # debido a un error: ERROR <Ens>ErrException: <READ>zAcceptPDU+4^EnsLib.DICOM.Adapter.TCP.1 -- - registrado como '-' número - @''> ERROR <Ens>ErrException: <READ>zAcceptPDU+4^EnsLib.DICOM.Adapter.TCP.1 -- - registrado como '-' número - @''
Lo más acuciante e intrigante es el hecho de que el Simulador dcm4che que replica ser un Sistema ORIGEN (envía al servicio) se queda a la escucha, tras haber enviado el C-MOVE-RQ:
Y el simulador que actúa como DESTINO se queda en el estado de Asociación Establecida, sin embargo no le llega efecitamente el C-MOVE-RQ, lo cual es muy llamativo :
¿ De qué forma nos recomiendan depurar ?
Muchas gracias de antemano por su tiempo, por leerme y responder. Un saludo Hola de nuevo, Yone:
Puedes probar a subir los timeous por ejemplo a 60s.
Además, puedes activar las trazas detalladas de interoperabilidad. Quizá te ponga así más información. Mira en:
https://docs.intersystems.com/irisforhealth20221/csp/docbook/Doc.View.cls?KEY=EMONITOR_tracing
```
set ^Ens.Debug("TraceCat","queue")=1
```
En otro caso, quizá habría que ya verlo a nivel de red (e.g. captura con WireShark y demás), o si lo quieres ver muy en detalle abrir un caso WRC.
Artículo
Heloisa Paiva · 23 sep, 2022
En este artículo vas a encontrar un sencillo programa con Python en un entorno IRIS y otro sencillo programa con ObjectScript en un entorno Python. Además, me gustaría compartir algunos de los errores que tuve cuando empecé la implementación de estos códigos.
Python en entorno IRIS
Supongamos, por ejemplo, que estás en un entorno IRIS y quieres resolver un problema que crees más fácil o más eficiente de resolver en Python.
Puedes simplemente cambiar el entorno: crea tu método como cualquier otro, y al final del nombre y sus especificaciones, añade [ Language = python ]:
Puedes usar todo tipo de argumento en el método y, para acceder a ellos, haces lo mismo que harías en COS;
Supongamos que tenemos este argumento %String, llamado Arg, y un argumento OtherArg que viene de una clase custom. Esta clase puede tener propiedades como Title y Author. Puedes accederlas así:
Este método trae un output así:
Para acceder a los métodos de clase, es básicamente lo mismo. Si hay un método en Demo.Books.PD.Books (de OtherArg), llamado “CreateString”, que concatena el título y el autor en algo como "Title: <Title>; Author: <Author>", entonces, anãdir esto al final de nuestro método Python:
proporcionará este output:
Para acceder al método, solo es necesario OtherArg.CreateString(), pero elegí usar los mismos valores en OtherArg (CreateString(OtherArg)) para que los outputs sean similares y el código, más simple.
ObjectScript en entorno Python
También hay situaciones en las que estás desarrollando en Python, pero quieres utilizar ObjectScript para ayudarte.
Para empezar, puede que quieras revisar esta lista para poder acceder a tus archivos COS desde un entorno Python de muchas maneras (nos las voy a usar todas aquí):
¿Tienes los requisitos previos? Compruébalo aquí
¿Puedes usar un servidor externo Python? Compruébalo aquí
¿Tienes todos los drivers necesarios? Descárgalos aquí o Aprende más aquí
Siempre puedes volver a esos enlaces o leer la lista de errores que encontré mientras creaba mis primeros programas Python con COS, por si te ayuda.
¡Entonces, empecemos a programar!
Antes de todo, hay que adaptar lo que viene de COS para Python. Por suerte, InterSystems ya lo hizo y solo hay que escribir “import iris” al comienzo del código para acceder a todo!
En el próximo paso, creamos una conexión al namespace deseado, usando una ruta con el host, port y namespace (host:port/namespace) y dándole usuario y contraseña:
Fíjate cómo creamos un OBJETO IRIS, para poder usar esta conexión para acceder a todo que necesitamos del namespace.
Finalmente, puedes “programar” todo lo que quieras!
Puedes acceder a métodos con irispy.classMethodValue(), dando el nombre de la clase y el nombre y los argumentos del método, puedes manipular objetos con .set() (para propiedades), y muchas otras posibilidades, mientras usas Python como quieras.
Para más informaciones sobre funciones de iris y cómo usarlas, echa un vistazo a Introduction to the Native SDK for Python
En este ejemplo, en la línea 16, he instanciado una clase %Persistent para, en las próximas líneas darles los valores “Lord of The Rings” y “Tolkien” para las propiedades Title y Author.
En la línea 20, llamé un método de otra clase que guarda el objeto en una tabla y vuelve un status si funciona. Finalmente, en la línea 23, vuelve el status.
Mezcla!
En un entorno ObjectScript, puedes necesitar de las conocidas librerías de Python, o tus propios archivos con tus funciones y rutinas.
Puedes usar el comando “import” con NumPy, SciPy y cualquier otro que quieras (considerando que las tienes correctamente instaladas: mira aquí cómo hacerlo)
Pero también, si quieres acceder a tus archivos locales hay muchas maneras de hacerlo y es fácil encontrar tutoriales para eso, ya que Python es muy popular.
A mí personalmente esta es la que más me gusta:
Aquí importé todo del archivo testesql.py, situado en C:/python y dejé impreso todos los resultados de la función select()
Extras - problemas que encontré
SHELLS: Cuando usas Shells, acuerdate de que Windows PowerShell funciona cómo un sistema UNIX-based (porque está basado en .NET) y el Command Prompt es el que funcionará con los ejemplos de Windows en la documentación oficial de InterSystems. Eso puede parecer simple para programadores con más experiencia, pero si no estás prestando mucha atención puedes perder un tiempo con este detalle.
USUARIOS Y PRIVILEGIOS: El usuario actual para programar con ObjectScript en un entorno Python necesita tener privilegios para los recursos del namespace. Recuerda que si no se selecciona ningún usuario, el actual es UnkownUser, y si no se selecciona ningún namespace, el actual es USER. Entonces, en el acceso más simple: Portal de Administración > Administración del Sistema > Seguridad > Usuarios > Unknown User > Roles, y selecciona %DB_USER, y guarda.
NO SÉ QUÉ PASA: Para tener más informacion sobre los errores que estás teniendo, ve a: Portal de Administración > System Explorer > SQL y escribe “SELECT * FROM %SYS.Audit ORDER BY UTCTimeStamp Desc”, y ahí vas a tener las más recientes audits. Acordate de seleccionar el namespace correcto para la consulta de la query. Así, puedes leer las causas de errores como IRIS_ACCESSDENIED() y mucho más, que puedes tener hacia fuera del ambiente IRIS.
ERROR COMPILANDO PYTHON: Evita llamar a Métodos con nombres como try() o con los de otras funciones de Python. El compilador no sabrá la diferencia entre el nombre del método y el nombre de la función.
¡Gracias por leer y, por favor, comparte tus comentarios, sugerencias o dudas!
Artículo
Luis Angel Pérez Ramos · 31 ene, 2023
Hola Comunidad:
En este artículo, enumero 5 funciones bastánte útiles de SQL, con sus explicaciones y algunos ejemplos de consultas👇🏻Las 5 funciones son:
COALESCE
RANK
DENSE_RANK
ROW_NUMBER
Función para obtener totales acumulados
¡Empezamos!
#COALESCE
La función COALESCE evalúa una lista de expresiones en orden de izquierda a derecha y devuelve el valor de la primera expresión non-NULL (no nula). Si todas las expresiones se corresponden con NULL (nulo), se devuelve NULL.
La siguiente sentencia devolverá el primer valor no nulo, que es 'intersystems'.
SELECT COALESCE(NULL, NULL, NULL,'intersystems', NULL,'sql')
Vamos a crear una tabla para ver otro ejemplo.
CREATE TABLE EXPENSES(
TDATE DATE NOT NULL,
EXPENSE1 NUMBER NULL,
EXPENSE2 NUMBER NULL,
EXPENSE3 NUMBER NULL,
TTYPE CHAR(30) NULL)
Ahora vamos a insertar algunos valores ficticios para probar nuestra función
INSERT INTO sqluser.expenses (tdate, expense1,expense2,expense3,ttype )
SELECT {d'2023-01-01'}, 500,400,NULL,'Present'
UNION ALL
SELECT {d'2023-01-01'}, NULL,50,30,'SuperMarket'
UNION ALL
SELECT {d'2023-01-01'}, NULL,NULL,30,'Clothes'
UNION ALL
SELECT {d'2023-01-02'}, NULL,50,30 ,'Present'
UNION ALL
SELECT {d'2023-01-02'}, 300,500,NULL,'SuperMarket'
UNION ALL
SELECT {d'2023-01-02'}, NULL,400,NULL,'Clothes'
UNION ALL
SELECT {d'2023-01-03'}, NULL,NULL,350 ,'Present'
UNION ALL
SELECT {d'2023-01-03'}, 500,NULL,NULL,'SuperMarket'
UNION ALL
SELECT {d'2023-01-04'}, 200,100,NULL,'Clothes'
UNION ALL
SELECT {d'2023-01-06'}, NULL,NULL,100,'SuperMarket'
UNION ALL
SELECT {d'2023-01-06'}, NULL,100,NULL,'Clothes'
Consultamos los datos
Ahora, al usar la función COALESCE recuperaremos el primer valor not NULL (no nulo) de las columnas expense1, expense2 y expense 3
SELECT TDATE,
COALESCE(EXPENSE1,EXPENSE2,EXPENSE3),
TTYPE
FROM sqluser.expenses ORDER BY 2
Funciones #RANK vs DENSE_RANK vs ROW_NUMBER
RANK()— asigna un número entero de clasificación (ranking) a cada fila dentro del mismo "marco de ventana" (conjunto de datos obtenidos en la consulta), empezando en 1. Los números del ranking pueden incluir valores duplicados si varias filas contienen el mismo valor en el campo definido para la función de ventana.
ROW_NUMBER() — asigna un número entero único y secuencial a cada fila dentro del mismo "marco de ventana", empezando en 1. Si varias filas contienen el mismo valor para el campo definido en la función de ventana, a cada fila se le asigna un número entero único y secuencial.
DENSE_RANK() no se salta ningún valor en el ranking si hay valores duplicados.
En SQL, hay varias formas de asignar un ranking a una fila, que analizaremos en detalle con un ejemplo. Consideramos de nuevo el mismo ejemplo anterior, pero ahora queremos saber cuál es el gasto mayor.
Queremos saber donde gasto más dinero y para ello tenemos diferentes formas de hacerlo. Podemos usar las tres funciones: ROW_NUMBER() , RANK() y DENSE_RANK() . Ordenaremos la tabla anterior usando las tres funciones y veremos las diferencias entre ellas usando la siguiente consulta:
Esta es nuestra consulta:
La principal diferencia entre las tres funciones es cómo tratan los empates. Vamos a explicar las diferencias un poco más en detalle:
ROW_NUMBER()devuelve un número único para cada fila empezando en el 1. Cuando hay empates, asigna un número de forma arbitraria si no se define un segundo criterio.
RANK()devuelve un número único para cada fila empezando en el 1, excepto cuando hay empates. Entonces asignará el mismo número. Y se saltará un valor en el ranking tras el puesto del ranking duplicado.
DENSE_RANK() asigna el mismo valor del ranking a los valores duplicados, pero no se salta ningún puesto del ranking.
#Calculando Totales Acumulados (Running Totals)
La función running total (total acumulado) es probablemente una de las funciones de ventana más útiles, especialmente cuando se quiere visualizar el crecimiento. Al usar una función de ventana con SUM(), se puede calcular una agregación acumulativa.
Para hacerlo, solo necesitamos sumar una variable usando el agregador SUM() pero ordenar la función usando una columna TDATE.
Esta sería la consulta:
Como se puede ver en la tabla, ahora tenemos la suma acumulada de la cantidad de dinero gastada, según pasan los días.
Conclusión
SQL es excelente. Las funciones utilizadas en este artículo pueden ser útiles para el análisis de datos, la ciencia de datos y cualquier otro campo relacionado con los datos.
Por eso es importante seguir actualizando y mejorando los conocimientos de SQL.
¡Espero que os resulte útil!
Artículo
Dmitrii Kuznetsov · 19 sep, 2022
Una sesión simultánea en IRIS: SQL, Objects, REST y GraphQL
Kazimir Malevich, "Deportistas" (1932)
"¡Pues claro que no lo entiende! ¿Cómo puede una persona que siempre ha viajado en un carruaje tirado por caballos entender los sentimientos e impresiones del viajero expres o del piloto de aviones?"Kazimir Malevich (1916)
Introducción
Ya hemos abordado el tema de por qué la representación de objetos/clases es superior a la de SQL para implementar modelos de áreas temáticas. Y esas conclusiones y hechos son tan ciertos ahora como lo han sido siempre. Entonces, ¿por qué deberíamos dar un paso atrás y hablar sobre las tecnologías que arrastran las abstracciones de vuelta al nivel global, donde habían estado en la era pre-objetos y pre-clases? ¿Por qué debemos fomentar el uso de "código espagueti", que provoca errores que son difíciles de rastrear y se basa en las habilidades de desarrolladores virtuosos?
Hay varios argumentos a favor de la transmisión de datos por medio de APIs basadas en SQL/REST/GraphQL en lugar de representarlos como clases/objetos:
Estas tecnologías están muy bien estudiadas y son bastante fáciles de implementar
Disfrutan de una increíble popularidad y han sido ampliamente implementadas en software accesible y de código abierto
Con frecuencia no hay otra alternativa que utilizar estas tecnologías, especialmente en la web y en las bases de datos
Lo más importante es que las APIs siguen utilizando objetos, ya que ofrecen la forma más apropiada de implementar las APIs en el código
Antes de hablar de la implementación de las APIs, vamos a echar un vistazo a las capas de abstracción por debajo. El siguiente diagrama muestra cómo se mueven los datos entre el lugar donde se almacenan permanentemente y el lugar donde se procesan y se presentan al usuario de nuestras aplicaciones.
Actualmente, los datos se almacenan en discos duros giratorios (HDD) o, para utilizar una tecnología más moderna, en chips de memoria flash en un SSD. Los datos se escriben y se leen utilizando un flujo que consiste en bloques de almacenamiento separados en el HDD/SSD.
La división en bloques no es aleatoria. Más bien, está determinado por la física, la mecánica y la electrónica del medio de almacenamiento de datos. En un disco duro, estas son las pistas/sectores de un disco magnético giratorio. En un SSD, son los segmentos de memoria en un chip de silicio regrabable.
La esencia es la misma: son bloques de información que debemos encontrar y reunir para recuperar los datos que necesitamos. Los datos deben ensamblarse en estructuras que emparejen nuestro modelo/clase de datos con los valores que corresponden al momento de la consulta. El DBMS (Sistema de Administración de Bases de Datos) integrado en el subsistema de archivos del sistema operativo es el responsable del proceso de ensamblaje y recuperación de datos.
Podemos evitar el DBMS dirigiéndonos directamente al sistema de archivos o incluso al HDD/SSD. Pero entonces perdemos dos puentes súper importantes para los datos: entre los bloques de almacenamiento y los flujos de archivos; y entre los archivos y la estructura ordenada en el modelo de base de datos. En otras palabras, asumimos la responsabilidad del desarrollo de todo el código para procesar bloques, archivos y modelos, incluyendo todas las optimizaciones, la depuración minuciosa y las pruebas de fiabilidad a largo plazo.
El DBMS nos ofrece una excelente oportunidad para tratar los datos en un lenguaje de alto nivel, utilizando modelos y representaciones comprensibles. Esta es una de las grandes ventajas de estos sistemas. Los DBMS y las plataformas de datos, como InterSystems IRIS, ofrecen aún más: la capacidad de acceder simultáneamente a los datos ordenados de muy diversas maneras. Y cada uno decide cuál utilizar en su proyecto.
Vamos a aprovechar la variedad de herramientas que nos ofrece IRIS. Vamos a hacer el código más atractivo y limpio. Utilizaremos directamente ObjectScript, el lenguaje orientado a objetos, para utilizar y desarrollar APIs. En otras palabras, por ejemplo, llamaremos al código SQL directamente desde el software ObjectScript. Para otras APIs, utilizaremos librerías listas y herramientas integradas en ObjectScript.
Tomaremos nuestros ejemplos del proyecto de Internet SQLZoo, que ofrece recursos de aprendizaje para SQL. Utilizaremos los mismos datos en nuestros otros ejemplos de API.
Si quieres obtener una visión general de la variedad de enfoques para el diseño de API y aprovechar las soluciones ya hechas, esta es una interesante y útil colección de APIs públicas, que han sido reunidas en un único proyecto en GitHub.
SQL
No hay una forma más natural de empezar que con SQL. ¿Quién no lo conoce?
Hay un enorme cantidad de tutoriales y libros sobre SQL. Nos basaremos en SQLZoo. Es un buen curso de SQL para principiantes, con ejemplos, tutoriales y una referencia del lenguaje SQL.
Vamos a trasladar algunas tareas de SQLZoo a la plataforma de IRIS y a resolverlas utilizando diversos métodos.
¿Con qué rapidez puedes acceder a InterSystems IRIS en tu ordenador? Una de las opciones más rápidas es implementar un contenedor en Docker a partir de una imagen ya preparada de la Community Edition de InterSystems IRIS. La Community Edition es una versión gratuita de InterSystems IRIS Data Platform para desarrolladores.Otras maneras de acceder a la Community Edition de InterSystems IRIS en el Portal de Formación.
Para pasar los datos de SQLZoo a nuestro propia instancia de almacenamiento de IRIS.
Para hacer esto:
Abre el Portal de Administración (el mío, por ejemplo, está en http://localhost:52773/csp/sys/UtilHome.csp),
Cambia al área USER: en el Namespace %SYS haz clic en el enlace “Switch” y selecciona USER
Ve a System > SQL - abre el Explorador del Sistema, luego SQL y haz clic en el botón “Go”.
En la parte derecha se abrirá la pestaña "Execute query" con el botón "Execute", que es lo que necesitamos.
Para obtener más información sobre cómo trabajar con SQL a través del Portal de Administración, consulta esta documentación.
Echa un vistazo a los scripts listos para implementar la base de datos y el conjunto de datos de prueba de SQLZoo en la descripción de la sección Datos.
Aquí hay un par de enlaces directos para la tabla world:
Un script que se utiliza para crear la base de datos world
Los datos que entran en esa tabla
El script para crear la base de datos se puede ejecutar en el formulario Query Executor que está en el Portal de administración de IRIS.
CREATE TABLE world(
name VARCHAR(50) NOT NULL
,continent VARCHAR(60)
,area DECIMAL(10)
,population DECIMAL(11)
,gdp DECIMAL(14)
,capital VARCHAR(60)
,tld VARCHAR(5)
,flag VARCHAR(255)
,PRIMARY KEY (name)
)
Para cargar el conjunto de pruebas para el formulario Query Executor, ve al menú Wizards > Data Import. Ten en cuenta que el directorio con el archivo de datos de prueba debe añadirse previamente, cuando creas el contenedor, o cargarse desde el ordenador por medio del navegador. Esta opción está disponible en el panel de control del asistente de importación de datos.
Revisa si la tabla con los datos está presente ejecutando este script en el formulario del Query Executor:
SELECT * FROM world
Ahora podemos acceder a los ejemplos y las tareas desde la página web de SQLZoo. Los siguientes ejemplos requieren que implementes una consulta SQL en la primera asignación:
SELECT population
FROM world
WHERE name = 'France'
De esta manera, podrás seguir trabajando sin problemas con la API, transfiriendo tareas de SQLZoo a la plataforma IRIS.
Nota: como he descubierto, los datos en la interfaz de SQLZoo son diferentes de los datos exportados. Al menos en el primer ejemplo, los valores para la población de Francia y Alemania difieren. No te preocupes por eso. Utiliza los datos de Eurostat como referencia.
Otra forma práctica de obtener acceso SQL a la base de datos en IRIS es el editor de Visual Studio Code con el plugin SQL Tools y el driver SQLTools para InterSystems IRIS. Esta solución es muy popular entre los desarrolladores - dale una vuelta.
Con el fin de proceder sin problemas al siguiente paso y obtener acceso a través de objetos a nuestra base de datos, vamos a tomar un pequeño desvío desde las consultas SQL "puras" a las consultas SQL embebidas en el código de la aplicación en ObjectScript, que es un lenguaje orientado a objetos integrado en IRIS.
Cómo configurar el acceso a IRIS y desarrollar en ObjectScript en VSCode.
Class User.worldquery
{
ClassMethod WhereName(name As %String)
{
&sql(
SELECT population INTO :population
FROM world
WHERE name = :name
)
IF SQLCODE<0 {WRITE "SQLCODE error ",SQLCODE," ",%msg QUIT}
ELSEIF SQLCODE=100 {WRITE "Query returns no results" QUIT}
WRITE name, " ", population
}
}
Vamos a comprobar el resultado en el terminal:
do ##class(User.worldquery).WhereName("France")
Deberías recibir el nombre del país y el número de habitantes como respuesta.
Objetos/Tipos
Ahora, vamos a la historia de REST/GraphQL. Estamos implementando una API para protocolos web. La mayoría de las veces, tendríamos el código fuente oculto en el lado del servidor en un lenguaje que tiene un buen soporte para clases, o incluso un paradigma totalmente orientado a objetos. Estos son algunos de los lenguajes de los que hablamos: Spring en Java/Kotlin, Django en Python, Ruby en Rails, ASP.NET en C#, o Angular en TypeScript. Y, por supuesto, objetos en ObjectScript, que es nativo de la plataforma IRIS.
¿Por qué esto es importante? Las clases y objetos en tu código se simplificarán a estructuras de datos cuando se envían. Hay que tener en cuenta cómo se simplifican los modelos en el programa, lo que es similar a tener en cuenta las pérdidas en los modelos relacionales. También hay que asegurarse de que, al otro lado de la API, los modelos se restauran adecuadamente y se pueden utilizar sin distorsiones. Esto supone una carga adicional: una responsabilidad adicional para ti como programador. Fuera del código y más allá de la ayuda de traductores, compiladores y otras herramientas automáticas, hay que asegurarse continuamente de que los modelos se transfieren correctamente.
Si nos fijamos en el problema anterior desde una perspectiva diferente, todavía no vemos ninguna tecnología ni herramienta que se pueda utilizar para transferir fácilmente clases/objetos de un programa en un lenguaje a un programa en otro. ¿Qué es lo que queda? Hay implementaciones simplificadas de SQL/REST/GraphQL, y una infinidad de documentación que describen la API en un lenguaje amigable. La documentación más informal (desde la perspectiva del ordenador) para desarrolladores describe exactamente lo que debería ser traducido en código formal utilizando todos los medios disponibles, para que el ordenador pueda procesarlos.
Los programadores desarrollan constantemente diferentes enfoques para resolver los problemas anteriores. Uno de los enfoques exitosos es el paradigma del lenguaje cruzado en el objeto DBMS de la plataforma IRIS.
La siguiente tabla te ayudará a entender la relación entre los modelos OPP y SQL en IRIS:
Programación orientada a objetos (OOP)
Lenguaje de consulta estructurado (SQL)
Paquete
Esquema
Clase
Tabla
Propiedad
Columna
Método
Procedimiento almacenado
Relación entre dos clases
Clave foránea, join
Objeto(en memoria o en disco)
Fila (en el disco)
Puedes obtener más información sobre la visualización de objetos y modelos relacionales en la documentación de IRIS.
Al ejecutar nuestra consulta SQL para crear la tabla world a partir del ejemplo anterior, IRIS generará automáticamente las descripciones del objeto correspondiente en la clase denominada User.world.
Class User.world Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {_SYSTEM}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = world ]
{
Property name As %Library.String(MAXLEN = 50) [ Required, SqlColumnNumber = 2 ];
Property continent As %Library.String(MAXLEN = 60) [ SqlColumnNumber = 3 ];
Property area As %Library.Numeric(MAXVAL = 9999999999, MINVAL = -9999999999, SCALE = 0) [ SqlColumnNumber = 4 ];
Property population As %Library.Numeric(MAXVAL = 99999999999, MINVAL = -99999999999, SCALE = 0) [ SqlColumnNumber = 5 ];
Property gdp As %Library.Numeric(MAXVAL = 99999999999999, MINVAL = -99999999999999, SCALE = 0) [ SqlColumnNumber = 6 ];
Property capital As %Library.String(MAXLEN = 60) [ SqlColumnNumber = 7 ];
Property tld As %Library.String(MAXLEN = 5) [ SqlColumnNumber = 8 ];
Property flag As %Library.String(MAXLEN = 255) [ SqlColumnNumber = 9 ];
Parameter USEEXTENTSET = 1;
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
/// DDL Primary Key Specification
Index WORLDPKey2 On name [ PrimaryKey, Type = index, Unique ];
}
Esta es una plantilla que puedes utilizar para desarrollar tu aplicación en un estilo orientado a objetos. Todo lo que necesitas hacer es añadir métodos a la clase en ObjectScript, que tiene paquetes listos para la base de datos. De hecho, los métodos para esta clase son "procedimientos almacenados", para tomar prestada la terminología SQL.
Vamos a intentar implementar el mismo ejemplo que completamos antes de utilizar SQL. Añade el método WhereName a la clase User.world, que desempeñará el papel del diseñador de objetos "Información del país" para el nombre del país introducido:
ClassMethod WhereName(name As %String) As User.world
{
Set id = 1
While ( ..%ExistsId(id) ) {
Set countryInfo = ..%OpenId(id)
if ( countryInfo.name = name ) { Return countryInfo }
Set id = id + 1
}
Return countryInfo = ""
}
Verifica las siguientes líneas de comando en el terminal:
set countryInfo = ##class(User.world).WhereName("France")
write countryInfo.name
write countryInfo.population
De este ejemplo podemos entender que, para encontrar el objeto deseado por el nombre del país, a diferencia de una consulta SQL, necesitamos ordenar manualmente los registros de la base de datos uno por uno. En el peor de los casos, si nuestro objeto está al final de la lista (o no está allí en absoluto), tendremos que ordenar todos los registros. Hay un debate aparte sobre cómo se puede acelerar el proceso de búsqueda mediante la indexación de campos de objeto y la autogeneración de métodos de clase en IRIS. Puedes leer más en la documentación y en este artículo de la Comunidad de Desarrolladores.
Por ejemplo, para nuestra clase, conociendo el nombre del índice generado por IRIS a partir del nombre del país WORLDPKey2, se puede iniciar/diseñar un objeto desde la base de datos utilizando una sola consulta rápida:
set countryInfo = ##class(User.world).WORLDPKey2Open("France")
Revisa también:
write countryInfo.name write countryInfo.population
En esta documentación puedes encontrar algunas pautas para decidir si utilizar acceso a través de objetos o SQL.
Por supuesto, siempre debes tener en cuenta que puede que sólo necesites uno de ellos para realizar tus tareas.
Además, gracias a la disponibilidad de paquetes binarios listos en IRIS que son compatibles con los lenguajes OOP más comunes, como Java, Python, C, C# (.Net), JavaScript, e incluso Julia (consulta GitHub y OpenExchange), que está ganando popularidad rápidamente, siempre podrás elegir las herramientas de desarrollo de lenguajes que más te convengan.
Ahora vamos a profundizar en el debate sobre los datos en la API web.
REST, o la API web RESTful
Vamos a salir de los límites del servidor y del terminal familiar y a utilizar algunos interfaces más convencionales: el navegador y aplicaciones similares. Estas aplicaciones dependen de los protocolos de hipertexto de la familia HTTP para administrar las interacciones entre sistemas. IRIS incorpora varias herramientas adecuadas para este fin, incluyendo un servidor de base de datos real y el servidor HTTP Apache.
La Transferencia de Estado Representacional (REST) es un estilo de arquitectura para diseñar aplicaciones distribuidas y, en particular, aplicaciones web. Aunque es popular, REST solo es un conjunto de principios arquitectónicos, mientras que SOAP es un protocolo estándar preservado por el Consorcio World Wide Web (W3C), y por tanto las tecnologías basadas en SOAP están respaldadas por un estándar.
El ID global en REST es una URL, y define cada unidad de información sucesiva cuando se intercambia con una base de datos o una aplicación back-end. Consulta esta documentación para desarrollar servicios REST en IRIS.
En nuestro ejemplo, el identificador base será algo parecido a la base desde la dirección del servidor IRIS, http://localhost:52773, y la ruta /world/ a nuestros datos que es un subdirectorio de ella. En particular, se trata de nuestro directorio de países /world/France.
En un contenedor Docker tendrá un aspecto similar a este:
http://localhost:52773/world/France
Si estás desarrollando una aplicación completa, asegúrate de revisar las recomendaciones de la documentación de IRIS. Una de ellos se basa en la descripción de la API REST, según la especificación OpenAPI 2.0.
Hagamos esto de la manera fácil, implementando la API manualmente. En nuestro ejemplo, crearemos la solución REST más simple, que solo requiere dos pasos en IRIS:
Crear una clase monitor (API) que se ejecutará al llamar a la URL. Esta clase heredará de la clase del sistema %CSP.REST
Configurar una aplicación web para que invoque a nuestra clase API cuando se llame a la URL.
Paso 1: Clase API
Debería estar claro cómo se puede implementar una clase. Sigue las instrucciones en la documentación para crear una REST "manual".
/// Description
Class User.worldrest Extends %CSP.REST
{
Parameter UseSession As Integer = 1;
Parameter CHARSET = "utf-8";
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Url="/:name" Method="GET" Call="countryInfo" />
</Routes>
}
}
Asegúrate de incluir un método que gestione la llamada. Debería realizar exactamente la misma función que las llamadas en el terminal del ejemplo anterior:
ClassMethod countryInfo(name As %String) As %Status
{
set countryInfo = ##class(User.world).WhereName(name)
write "Country: ", countryInfo.name
write "<br>"
write "Population: ", countryInfo.population
return $$$OK
}
Como se puede ver, el parámetro que empieza con dos puntos, :name,está indicado para que se pase como variable al método que gestiona la llamada.
Paso 2: Configurando la aplicación web IRIS
En System Administration > Security > Applications > Web Applications, añade una nueva aplicación web con una dirección de entrada URL en /world y este handler o manejador: la clase API que has implementado en el paso anterior.
Después de que se configura, la aplicación web debería responder inmediatamente cuando vayas a http://localhost:52773/world/France. Ten en cuenta que la base de datos distingue entre mayúsculas y minúsculas, por lo que se debe utilizar la letra correcta al transmitir los datos de la solicitud al parámetro del método.
Consejos útiles:
Utiliza las herramientas de depuración si es necesario. Puedes encontrar una buena descripción en este artículo de dos partes (echa un vistazo a los comentarios también)
Si aparece el error "401 Unauthorized", y estás seguro de que la clase monitor está en el servidor y de que no hay errores en el enlace, intenta añadir la función %All en la pestaña Application Roles que se encuentra en la configuración de la aplicación web. Este no es un método totalmente seguro, y es necesario comprender las posibles implicaciones de permitir el acceso para todas las funciones, pero es aceptable para una instalación local.
GraphQL
Este es un terreno nuevo desde el punto de vista de que no encontrarás nada en la documentación actual de IRIS sobre APIs que utilizan GraphQL. Sin embargo, esto no debería impedirnos utilizar esta maravillosa herramienta.
Hace sólo cinco años que GraphQL salió a la luz. Desarrollado por la Fundación Linux, GraphQL es un lenguaje de consulta para APIs. Y probablemente se puede decir que se trata de la mejor tecnología derivada de la mejora de la arquitectura REST y de las distintas APIs web. Aquí hay un breve artículo introductorio para principiantes. Y, gracias a los esfuerzos de los seguidores de InterSystems y a sus ingenieros, IRIS ofrece aplicaciones de ejemplo para GraphQL desde 2018.
Aquí está el artículo relacionado “Cómo implementar GraphQL en las plataformas de InterSystems”.
La aplicación GraphQL se compone de dos módulos: el backend de la aplicación en el lado de IRIS y el frontend que se ejecuta en el navegador. En otras palabras, es necesario configurarlo de acuerdo con las instrucciones para la aplicación web GraphQL y GraphiQL.
Por ejemplo, así se ve la configuración de la aplicación para mí en IRIS dentro de un contenedor Docker. Estas son las configuraciones para una aplicación web GraphQL que actúa como API REST y un gestor de esquemas de base de datos:
Y la segunda aplicación GraphQL es una interfaz de usuario para el navegador, escrita en HTML y JavaScript:
Se puede ejecutar visitando http://localhost:52773/graphiql/index.html.
Sin ninguna configuración restrictiva adicional, la aplicación inmediatamente buscará todos los esquemas de la base de datos que pueda encontrar en el área de instalación. Esto significa que nuestros ejemplos comenzarán a funcionar de inmediato. Además, el frontend proporciona un maravilloso conjunto organizado de pistas de los objetos disponibles.
Este es un ejemplo de una consulta GraphQL en nuestra base de datos:
{
User_world ( name: France ) {
name
population
}
}
Y aquí está la respuesta correspondiente:
{
"data": {
"User_world": [
{
"name": "France",
"population": 65906000
}
]
}
}
Así es como se ve en el navegador:
Resumen
Tecnología
Antiguedad de la tecnología
Ejemplo de consulta
SQL
50 años
Edgar F. Codd
SELECT population
FROM world
WHERE name = 'France'
OOP
40 años
Alan Kay and
Dan Ingalls
set countryInfo = ##class(User.world).WhereName("France")
REST
20 años
Roy Thomas Fielding
http://localhost:52773/world/France
GraphQL
5 años
Lee Byron
{ User_world ( name: France ) {
name
population
}
}
Se está invirtiendo mucha energía en tecnologías como SQL, REST y probablemente también en GraphQL. También hay mucha historia detrás de ellas. Todas funcionan bien entre sí, dentro de la plataforma IRIS, para crear programas que procesan datos
Aunque no se menciona en este artículo, IRIS también es compatible con otras APIs, basadas en XML (SOAP) y JSON, que están bien implementadas
A menos que te ocupes específicamente de, por ejemplo, organizar tus objetos, recuerda que los datos intercambiados con la ayuda de APIs siguen representando una versión incompleta y reducida de una transferencia de objetos. Como desarrollador (no el código), eres responsable de garantizar la correcta transferencia de información sobre el tipo de datos de un objeto
Una pregunta para vosotros, estimados lectores
El propósito de este artículo no era solo comparar las API modernas, y ni siquiera revisar las funciones básicas de IRIS. Era ayudar a que se viera lo fácil que es cambiar de una API a otra cuando se accede a una base de datos, aprender a dar los primeros pasos en IRIS y obtener rápidamente resultados de las tareas.
Por esta razón estoy muy interesado en saber cuál es vuestra opinión:
¿Esta clase de enfoque ayuda a empezar a trabajar con el software?
¿Qué pasos del proceso dificultan el dominio de las herramientas para trabajar con la API en IRIS?
¿Podríais nombrar un obstáculo que no habéis podido prever?
Si conocéis a alguien que está aprendiendo a utilizar IRIS, podéis pedirle que deje un comentario en este artículo. Las preguntas y respuestas siempre son útiles para todos.
Artículo
Nancy Martínez · 16 abr, 2020
A partir de la versión 2019.2, InterSystems IRIS ofrece su API nativa para Python como un método de alto rendimiento para acceso a datos. La API nativa permite interactuar directamente con la estructura de datos nativa de IRIS.
Globals
Como desarrolladores de InterSystems, seguramente ya estais familiarizados con los globals. Vamos a revisar los aspectos básicos por si os apetece un repaso, pero podéis saltar a la siguiente sección si no lo necesitáis.InterSystems IRIS usa globals para almacenar los datos. Un global es una matriz dispersa formada por nodos que pueden, o no, tener un valor y subnodos. Lo que sigue es un ejemplo abstracto de un global:
En este ejemplo, a es un nodo raíz, al que nos referimos con el nombre del global. Cada nodo tiene una dirección de nodo, que consiste en el nombre del global y uno o múltiples subscripts (nombres de subnodos). a tiene los subscripts b y c; la dirección de nodo de esos nodos es s a->b y a->c.
Los nodos a->b y a->c->g tienen un valor (d y h), los nodos a->b->e y a->b->f no tienen valor. El nodo a->b tiene subscripts e y f.
Podéis encontrar una descripción detallada de esta estructura en el libro de InterSystems "Using Globals".Leer y escribir en el Global
La API nativa de Python permite leer y escribir los datos directamente en el global de IRIS. El paquete irisnative está disponible en GitHub - o si tienes InterSystems IRIS instalado de forma local en tu equipo, lo encontrarás en el subdirectorio dev/python de tu directorio de instalación.
La función irisnative.createConnection te permite crear una conexión con IRIS y la función irisnative.createIris te ofrece un objeto de esta conexión con el que se puede manipular el global. Este objeto tiene un método get and set para leer/escribir desde/hacia el global, y un método kill para eliminar un nodo y sus subnodos. También tiene un método isDefined, que devuelve 0 si el nodo solicitado no existe; 1 si tiene un valor, pero ningún descendiente; 10 si no tiene valor y tiene descendientes; u 11 si tiene un valor y descendientes.
import irisnative conn = irisnative.createConnection("127.0.0.1", 51773, "USER", "", "
") iris = irisnative.createIris(conn) iris.set("value", "root", "sub1", "sub2") # sets "value" to root->sub1->sub2 print(iris.get("root", "sub1", "sub2")) print(iris.isDefined("root", "sub1")) iris.kill("root") conn.close()
También tiene un método iterator para hacer un bucle sobre los subnodos de un determinado nodo. (Mostraré su uso en la siguiente sección)
Podéis leer una descripción completa de cada método en la documentación de la API nativa para Python.
Archivos de datos de tránsito del GTFS de San Francisco
Almacenamiento de datos en un global
El General Transit Feed Specification (GTFS) es un formato para horarios y rutas de transporte público. Vamos a ver cómo podemos usar la API nativa de IRIS para trabajar con datos del GTFS de San Francisco a partir del 10 de junio de 2019.
Primero, almacenaremos en el global IRIS la información de los archivos de datos. (En esta demostración no usaremos todos los archivos y columnas). Los archivos están en formato CSV, en el que la primera fila muestra los nombres de las columnas, y las otras filas contienen los datos. En Python, comenzaremos con las importaciones necesarias y estableceremos una conexión con IRIS:
import csv import irisnative conn = irisnative.createConnection("127.0.0.1", 51773, "USER", "", "
") iris = irisnative.createIris(conn)
En base a los nombres de las columnas y los datos, podemos construir una estructura de árbol razonable para cada archivo y usar iris.set para almacenar los datos en el global.
Empecemos con el archivo stops.txt, que contiene todas las paradas (stops) del transporte público en la ciudad. De este archvo, solo usaremos las columnas stop_id y stop_name. Las almacenaremos en un global llamado stops dentro de una estructura de árbol con una capa de nodos, con los IDs de parada como subscripts y los nombres de paradas como valores de nodos. Así, nuestra estructura tendrá este aspecto stops → [stop_id]=[stop_name]. (Para este artículo, usaré los corchetes para indicar cuándo un subscript no es literal, sino que es un valor leído de los archivos de datos).
with open("stops.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # stops -> [stop_id]=[stop_name] for row in reader: iris.set(row[6], "stops", row[4])
csv.reader devuelve un iterador de listas que contienen los valores separados por comas. La primera línea contiene los nombres de las columnas, por lo que la omitiremos connext(reader). Usaremos iris.set para definir el nombre de la parada como valor de stops -> [stop_id].
A continuación viene el archivo routes.txt, del que usaremos las columnas route_type, route_id, route_short_name y route_long_name. Una estructura de global razonable es routes -> [route_type] -> [route_id] -> [route_short_name]=[route_long_name]. (El tipo de ruta (route) es 0 para un tranvía, 3 para un autobús y 5 para un tranvía). Podemos leer el archivo CSV y colocar los datos en el global exactamente de la misma forma.
with open("routes.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # routes -> [route_type] -> [route_id] -> [route_short_name]=[route_long_name] for row in reader: iris.set(row[0], "routes", row[1], row[5], row[8])
Cada ruta tiene viajes (trips), almacenados en trips.txt, del que usaremos las columnas route_id, direction_id, trip_headsign and trip_id. Los viajes se identifican de forma única con su ID de viaje ("trip ID"), que veremos más adelante en el archivo de horarios de parada. Los viajes de una ruta pueden separarse en dos grupos según su dirección, y las direcciones tienen letreros ("head signs") asociados a ellas. Esto nos lleva a la estructura de árbol trips -> [route_id] -> [direction_id]=[trip_headsign] -> [trip_id].
Aquí necesitamos dos llamadas a iris.set - una para definir el valor al nodo ID de dirección, y otra para crear el nodo sin valor del ID del viaje.
with open("trips.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # trips -> [route_id] -> [direction_id]=[trip_headsign] ->[trip_id] for row in reader: iris.set(row[3], "trips", row[1], row[2]) iris.set(None, "trips", row[1], row[2], row[6])
Por último, leeremos y almacenaremos los horarios de las paradas. Se almacenan en stop_times.txt y usaremos las columnas stop_id, trip_id, stop_sequence y departure_time. Una primera opción podría ser usar stoptimes -> [stop_id] -> [trip_id] -> [departure_time] o, si queremos mantener la secuencia de paradas, stoptimes -> [stop_id] -> [trip_id] -> [stop_sequence]=[departure_time].
with open("stop_times.txt", "r") as csvfile: reader = csv.reader(csvfile) next(reader) # Ignore column names # stoptimes -> [stop_id] -> [trip_id] -> [stop_sequence]=[departure_time] for row in reader: iris.set(row[2], "stoptimes", row[3], row[0], row[4])
Consultar los datos usando la API nativa
A continuación, nuestro objetivo es encontrar todos los horarios de salida para la parada con el nombre dado.
Primero, recuperamos el ID de parada desde el nombre de parada dado, y luego usaremos ese ID para encontrar los horarios relevantes en stop_times.
La llamada iris.iterator("stops") nos permite iterar sobre los subnodos del nodo raíz de paradas. Queremos iterar sobre los pares de subscripts y valores (para comparar los valores con el nombre dado, e inmediatamente conocer el subscript si coinciden), por lo que llamamos a .items() en el iterador, lo que define la clase de devolución como tuplas (de subscripts, valores). Luego podemos iterar sobre todas estas tuplas y encontrar la parada correcta.
stop_name = "Silver Ave & Holyoke St" iter = iris.iterator("stops").items() stop_id = None for item in iter: if item[1] == stop_name: stop_id = item[0] break if stop_id is None: print("Stop not found.") import sys sys.exit()
Merece la pena observar que buscar una clave por su valor mediante iteración no es muy eficiente si hay muchos nodos. Una forma de evitar esto sería tener otra matriz, en la que los subscripts sean los nombres de las paradas y los valores sean sus ID. El valor --> búsqueda clave consistiría entonces en una consulta a esta nueva matriz.
De forma alternativa, puede usar el nombre de parada como identificador en cualquier parte del código en vez del ID de parada - el nombre de parada también es único.
Como puedes ver, si tenemos una cantidad de paradas significativa, esta búsqueda puede tardar bastante. También se le conoce como "full scan" (análisis completo). Pero podemos aprovecharnos de los globals y construir la matriz invertida, en la que los nombres serán claves con IDs como valores.
iter = iris.iterator("stops").items() stop_id = None for item in iter: iris.set(item[0], "stopnames", item[1])
Tener el global de nombres de paradas (stopnames), en el que el índice es el nombre y el valor es el ID, cambiará el código anterior para encontrar el stop_id por nombre. El código será el siguiente, que se ejecutará sin una búsqueda de análisis completo:
stop_name = "Silver Ave & Holyoke St" stop_id=iris.get("stopnames", stop_name) if stop_id is None: print("Stop not found.") import sys sys.exit()
En este punto, podemos encontrar los horarios de parada. El subárbol stoptimes -> [stop_id] tiene los ID de viajes como subnodos, que tienen los horarios de paradas como subnodos. No nos interesan los ID de los viajes, solo los horarios de parada, por lo que iteraremos sobre todos los ID de viajes y recopilaremos todos los horarios de paradas para cada uno de ellos.
all_stop_times = set() trips = iris.iterator("stoptimes", stop_id).subscripts() for trip in trips: all_stop_times.update(iris.iterator("stoptimes", stop_id, trip).values())
Aquí no estamos usando .items() en el iterador, pero usaremos .subscripts() y .values() porque los IDs de viajes son subscripts (sin valores asociados)([stop_sequence]=[departure_time]), solo nos interesan los valores y horas de salida. La llamada .update agrega todos los elementos del iterador a nuestro conjunto existente. El nuevo conjunto ahora contiene todos los horarios (únicos) de paradas:
for stop_time in sorted(all_stop_times): print(stop_time)
Ahora vamos a hacerlo un poco más complicado. En vez de encontrar todas las horas de salida para una parada, encontraremos únicamente las horas de salida para una parada de una ruta dada (en ambas direcciones), cuyo ID de ruta es dado. El código para encontrar el ID de parada a partir del nombre de parada puede preservarse por completo. Entonces, se recuperarán todos los ID de paradas de la ruta dada. Estos ID se usan entonces como una restricción adicional al recuperar las horas de salida.
El subárbol de trips -> [route_id] se parte en dos direcciones, que tienen todo los ID de viajes como subnodos. Podemos iterar sobre las direcciones como antes, y agregar todos los subnodos de las direcciones a un conjunto.
route = "14334" selected_trips = set() directions = iris.iterator("trips", route).subscripts() for direction in directions: selected_trips.update(iris.iterator("trips", route, direction).subscripts())
En el siguiente paso, queremos encontar los valores de todos los subnodos de stoptimes -> [stop_id] -> [trip_id] donde [stop_id] es el ID de parada recuperado y [trip_id] es cualquiera de los IDs de viaje seleccionados. Iteramos sobre el conjunto selected_trips para encontrar todos los valores relevantes:
all_stop_times = set() for trip in selected_trips: all_stop_times.update(iris.iterator("stoptimes", stop_id, trip).values()) for stop_time in sorted(all_stop_times): print(stop_time)
Un último ejemplo muestra el uso de la función isDefined. Ampliaremos el código escrito anteriormente: en lugar de realizar un "hard-code" del ID de ruta, se ofrece el nombre corto de una ruta y luego el ID de la ruta se deberá recuperar en base a esto. Los nodos con los nombres de rutas están en la capa inferior del árbol. La capa de arriba contiene los ID de rutas. Podemos iterar sobre todos los tipos de rutas, luego sobre todos los ID de rutas y, si el nodo routes -> [route_type] -> [route_id] -> [route_short_name] existe y tiene un valor (isDefined returns 1), sabemos entonces que [route_id] es el ID que buscamos.
route_short_name = "44" route = None types = iris.iterator("routes").subscripts() for type in types: route_ids = iris.iterator("routes", type).subscripts() for route_id in route_ids: if iris.isDefined("routes", type, route_id, route_short_name) == 1: route = route_id if route is None: print("No route found.") import sys sys.exit()
El código sirve como sustituto de la línea route = "14334" en "hard-code".
Una vez finalizadas todas las operaciones de IRIS, podemos cerrar la conexión a la base de datos:
conn.close()
Próximos pasos
Hemos explicado cómo se puede usar la API nativa para Python para acceder a la estructura de datos de InterSystems IRIS. Después, lo hemos aplicado a los datos de transporte público de San Francisco. Para profundizar más en la API, podéis visitar esta documentación. La API nativa también está disponible para Java, .NET y Node.js.