Limpiar filtro
Artículo
Muhammad Waseem · 14 jun, 2022
Esta es una comparación creada en Python y Objectscript en InterSystems IRIS.
El objetivo es comparar la velocidad para enviar y recibir mil solicitudes/mensajes desde un BP a un BO en Python y en Objectscript.
Consultar [https://github.com/LucasEnard/benchmark-python-objectscript](https://github.com/LucasEnard/benchmark-python-objectscript) para más información.
**IMPORTANTE** : Aquí están los resultados del tiempo en segundos, para enviar **1000 mensajes** de *ida y vuelta* desde un `bp` a un `bo` usando Python, Graph Objectscript y Objectscript.
Los mensajes de cadena se componen de diez variables de cadena.
Los mensajes de objeto se componen de diez variables de objeto, cada objeto como su propio int, float, str y List(str).
| Cadenas de mensajes| Tiempo (segundos) para 1000 mensajes de ida y vuelta |
|------------------------|------------------|
| Python BP | 1.8 |
| BPL | 1.8 |
| ObjectScript | 1.4 |
| Objetos de mensajes| Tiempo (segundos) para 1000 mensajes de ida y vuelta |
|------------------------|------------------|
| Python BP | 3.2 |
| BPL | 2.1 |
| ObjectScript | 1.8 |
La función en la fila tiene x veces el tiempo de la función en la columna:
| Cadenas de mensajes| Python | BPL | ObjectScript |
|------------------------|------------|------------------------|------------------|
| Python | 1 | 1 | 1.3 |
| BPL | 1 | 1 | 1.3 |
| ObjectScript | 0.76 | 0.76 | 1 |
Por ejemplo, la primera fila nos dice que el tiempo de cadena de Python es 1 vez el tiempo de la función de cadena de gráficos de Objectscript y 1,3 veces el tiempo de la función de cadena de Objectscript. (gracias a la primera tabla podemos verificar nuestros resultados: 1.3 * 1.4 = 1.8 1.3 es la x en la tabla en la última columna de la primera fila, 1.4s es el tiempo para los mensajes de cadena en Objectscript vistos en la primera tabla de esta sección y 1.8s es de hecho el tiempo para los mensajes de cadena en python que podemos encontrar buscando en la primera tabla de esta sección o mediante el cálculo como se mostró antes).
Tenemos la función en la fila que tiene x veces el tiempo de la función en la columna:
| Cadenas de mensajes| Python | BPL | ObjectScript |
|------------------------|------------|------------------------|------------------|
| Python | 1 | 1.5 | 1.8 |
| BPL | 0.66 | 1 | 1.2 |
| ObjectScript | 0.55 | 0.83 | 1 |
Artículo
Jose-Tomas Salvador · 31 mayo, 2023
Este es un artículo de la página de "Preguntas frecuentes" (FAQ) de InterSystems.
1. Exportar API
a. Usa $system.OBJ.Export() para especificar rutinas individuales para exportar. Por ejemplo:
do $system.OBJ.Export("TEST1.mac,TEST2.mac","c:\temp\routines.xml",,.errors)
El formato que debes especificar es: NombreDeLaRutina.extension, y la extensión puede ser: mac, bas, int, inc, obj.
Los errores durante la exportación se almacenan en la variable "errors".
Echa un vistazo a la referencia de clase %SYSTEM.OBJ para más detalles sobre $system.OBJ.Export().
b. Usa $system.OBJ.Export() incluso al hacer una exportación genérica usando * (wildcards). Por ejemplo:
do $system.OBJ.Export("*.mac",c:\temp\allmacroutines.xml")
*Antes de la versión 2008.1, utiliza $system.OBJ.ExportPattern().
2. Importar API
a. Usa $system.OBJ.Load() para importar todas las rutinas contenidas en el fichero. Por ejemplo:
do $system.OBJ.Load("c:\temp\routines.xml",,.errors)
b. Importa solo algunas de las rutinas contenidas en el fichero
Observa el ejemplo de abajo. Si quieres seleccionar e importar solo algunas de las rutinas incluidas en el fichero XML, pon a 1 el 5º argumento "listonly" en una primera ejecución, y carga el archivo XML con $system.OBJ.Load(), estableciendo el 4º argumento (argumento de salida, list en el ejemplo abajo). Esto creará una lista de elementos en la variable list. Después podremos recorrer esa lista y decidir que elementos (loaditem) queremos cargar, volviendo a ejecutar $system.OBJ.Load() e indicando el elemento a cargar en el 6º argumento. Lo puedes ver más claramente en este ejemplo:
Set file="c:\temp\routines.xml" // First get the list of items contained in the XML Do $system.OBJ.Load(file,,.errors,.list,1 /* listonly */) Set item=$Order(list("")) Kill loaditem While item'="" { If item["Sample" Set loaditem(item)="" { // Import only those containing Sample Set item=$Order(list(item)) } } // Execute import process with created list Do $system.OBJ.Load(file,,.errors,,,.loaditem)
Artículo
Ricardo Paiva · 19 feb, 2021
Si está buscando una forma ingeniosa para integrar su solución de IRIS en el ecosistema de Amazon Web Services, en una aplicación sin servidor o en `Boto3` (un potente script de Python), usar la [API nativa de IRIS para Python](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_PYNATIVE) podría ser el camino a seguir. No es necesario que invierta demasiado tiempo en la implementación de una producción hasta que deba acercarse y obtener algo o establecer algo en IRIS para hacer que su aplicación ejecute su característica más sobresaliente, así que esperamos este artículo sea útil y desarrolle algo aunque solamente usted pueda usarlo, ya que eso también es importante.

Si necesita algunas excusas para implementarla, utilice las siguientes:
* Debe cargar el Activador que generará previamente los tokens en Cognito para buscar y completar el contexto de la identificación del paciente en el token. Esto con la finalidad de utilizar una solución basada en SMART on FHIR(R), la cual implementará un flujo de trabajo en OAUTH2.
* Quiere publicar el suministro de la configuración para los parámetros en IRIS que se basa en el tipo de instancia, grupo de nodo, Toaster o el clúster ECS que inició para ejecutar IRIS en el anillo cero.
* Quiere impresionar a su familia y amigos en Zoom con sus habilidades para administrar IRIS sin que su shell tenga que abandonar la CLI de AWS.
## Lo más importante
Aquí proporcionamos una función lambda de AWS que se comunica con IRIS y brindaremos algunos ejemplos sobre cómo utilizarla, además indicaremos cómo podemos interactuar con ella en varias funciones con la esperanza de que todos podamos discutir sobre ella y **publicarla en pip para facilitar las cosas.**
## ¿¿¿¿Tiene problemas????

Consulte el Stream
## En todos los casos...
Para participar en la diversión, necesitará eliminar algunas cosas de sus planes.
### Interconexión
Tiene a IRIS ejecutándose en cualquier lugar que desee, funcionando en una AWS VPC con exactamente dos subredes y un grupo de seguridad que permite el acceso al super servidor que inicia IRIS... utilizamos 1972 por razones nostálgicas y por el simple hecho de que InterSystems se tomó el tiempo para registrar ese puerto con [IANA](https://tools.ietf.org/html/rfc6335), y si agrega el nuevo puerto en `/etc/services` sin registrarlo, sufrirá las mismas consecuencias que si arrancara la etiqueta de un colchón nuevo. En nuestro caso, es un conjunto de réplicas de las instancias EC2 con las comprobaciones de estado adecuadas en torno a un balanceador de carga para la red AWS v2.
### Ejemplo de una clase importada
De alguna forma consiguió crear e importar la clase a en la raíz de este repositorio con el namespace `%SYS` en su instancia de IRIS. A continuación, se muestra el ejemplo de una clase que impulsa la salida anterior. Si se pregunta por qué necesitamos una clase para importar aquí, consulte la siguiente nota donde el enfoque recomendado es proporcionar algunas clases envolventes para utilizarlas con Python.
> Nota de los documentos: Aunque estos métodos también pueden utilizarse con las clases que se definieron en la Biblioteca de clases de InterSystems, una de las prácticas recomendadas consiste en llamarlos indirectamente, desde el interior de una clase o rutina definida por el usuario. Muchos métodos de clase devuelven solo un código de estado, y transmiten los resultados reales a un argumento (al que no es posible acceder por la API nativa). Las funciones definidas por el sistema (incluidas como parte de las Funciones de ObjectScript en la Referencia de ObjectScript) no pueden llamarse directamente.
Ejemplo de la clase:
```
Class ZDEMO.IRIS.Lambda.Operations Extends %Persistent
{
ClassMethod Version() As %String
{
Set tSC = 0
Set tVersion = $ZV
if ( tVersion '="" ) { set tSC = $$$OK }
Set jsonret = {}
Set jsonret.status = tSC
Set jsonret.payload = tVersion
Quit jsonret.%ToJSON()
}
}
```
Tenga en cuenta que decidí trabajar según lo establecido en los métodos, de modo que siempre emite un objeto JSON como respuesta, lo cual también me permite enviar el estado y posiblemente subsanar las deficiencias que implica devolver algunas cosas como referencia.
### AWS Access
Obtenga algunas claves de acceso IAM que le permitirán suministrar e invocar la función Lambda con la que cambiaremos el mundo.
Comprobación previa:
```
IRIS [ $$$OK ]
VPC [ $$$OK ]
Subnets [ $$$OK ]
Security Group [ $$$OK ]
IAM Access [ $$$OK ]
Imported Class [ $$$OK ]
```
$$$OK, **Lesgo**.
## Empaquetar la API nativa de IRIS para Python con el fin de utilizarla en la función Lambda
Esta parte sería fantástica si fuera un paquete pip, especialmente si solo es para Linux, ya que las funciones Lambda de AWS se ejecutan en Linux Boxen. Cuando realizamos esta asignación la API no estaba disponible por medio de pip, pero somos hábiles y podemos lanzar nuestro propio paquete.
```
mkdir iris_native_lambda
cd iris_native_lambda
wget https://github.com/intersystems/quickstarts-python/raw/master/Solutions/nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
unzip nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
```
A continuación, cree `connection.config`
Por ejemplo: [connection.config](https://raw.githubusercontent.com/basenube/iris_native_lambda/main/examples/connection.config)
Cree su controlador, `index.py` o utilice el que se encuentra en la carpeta de ejemplos, en el [repositorio con demostraciones de GitHub](https://github.com/basenube/iris_native_lambda). Tenga en cuenta que la versión de demostración utiliza tanto variables de entorno como un archivo externo para guardar la información de conectividad de IRIS.
Por ejemplo:
[index.py](https://raw.githubusercontent.com/basenube/iris_native_lambda/main/examples/index.py)
Ahora comprímalo para utilizarlo:
```
zip -r9 ../iris_native_lambda.zip *
```
Cree un bucket S3, y cargue la función zip en él.
```
cd ..
aws s3 mb s3://iris-native-bucket
s3 sync iris_native_lambda.zip s3://iris-native-bucket
```
> Con esto concluye el empaquetado de la API y el controlador para utilizarlos como una función Lambda de AWS.
Ahora, haga clic hasta que la consola termine para crear la función, o utilice algo como Cloudformation para realizar el trabajo:
```
IRISAPIFunction:
Type: "AWS::Lambda::Function"
DependsOn:
- IRISSG
- VPC
Properties:
Environment:
Variables:
IRISHOST: "172.31.0.10"
IRISPORT: "1972"
NAMESPACE: "%SYS"
USERNAME: "intersystems"
PASSWORD: "lovetheyneighbor"
Code:
S3Bucket: iris-native-bucket
S3Key: iris_native_lambda.zip
Description: "IRIS Native Python API Function"
FunctionName: iris-native-lambda
Handler: "index.lambda_handler"
MemorySize: 128
Role: "arn:aws:iam::8675309:role/BeKindtoOneAnother"
Runtime: "python3.7"
Timeout: 30
VpcConfig:
SubnetIds:
- !GetAtt
- SubnetPrivate1
- Outputs.SubnetId
- !GetAtt
- SubnetPrivate2
- Outputs.SubnetId
SecurityGroupIds:
- !Ref IRISSG
```
Eso fue MUCHO, pero ahora puede volverse loco, llamar a IRIS mediante la función lambda con Python y cambiar el mundo.
## ¡Vamos a iniciarlo!
De la forma en que se implementó lo anterior, se espera que la función sea aprobada en un evento del objeto que esté menos estructurado para reutilizarlo, puede ver la idea en el ejemplo para el evento del objeto que se muestra a continuación:
```
{
"method": "Version",
# important, if method requires no args, enforce "none"
"args": "none"
# example method with args, comma seperated
# "args": "thing1, thing2"
}
```
ahora puede hacerlo, si tiene cierta tolerancia para los ejemplos de la línea de comandos, eche un vistazo en la ejecución que se muestra a continuación utilizando la CLI de AWS:
```
(base) sween @ basenube-pop-os ~/Desktop/BASENUBE
└─ $ ▶ aws lambda invoke --function-name iris-native-lambda --payload '{"method":"Version","args":"none"}' --invocation-type RequestResponse --cli-binary-format raw-in-base64-out --region us-east-2 --profile default /dev/stdout
{{\"status\":1,\"payload\":\"IRIS for UNIX (Red Hat Enterprise Linux for x86-64) 2020.2 (Build 210U) Thu Jun 4 2020 15:48:46 EDT\"}"
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
```
Ahora bien, si vamos un poco más lejos, la CLI de AWS admite alias, así que cree uno y podrá jugar integrando completamente su increíble comando con AWS. Este es un ejemplo del alias para la CLI:
```
└─ $ ▶ cat ~/.aws/cli/alias
[toplevel]
whoami = sts get-caller-identity
iris =
!f() {
aws lambda invoke \
--function-name iris-native-lambda \
--payload \
"{\"method\":\""${1}"\",\"args\":\"none\"}" \
--invocation-type RequestResponse \
--log-type None \
--cli-binary-format raw-in-base64-out \
gar.json > /dev/null
cat gar.json
echo
echo
}; f
```
....y ahora puede hacerlo...

¡Manténgase a salvo!~ ¡Todos los argumentos técnicos son bienvenidos!
Artículo
Luis Angel Pérez Ramos · 25 abr, 2023
Una necesidad habitual en nuestros clientes es la configuración tanto de HealthShare HealthConnect como de IRIS en modo de alta disponibilidad.
Es común en otros motores de integración del mercado que se promocionen con configuraciones de "alta disponibilidad", pero realmente no suele ser del todo cierto. Por lo general dichas soluciones trabajan con bases de datos externas y por lo tanto, si estas no están a su vez configuradas en alta disponibilidad, al producirse una caída de la base de datos o la pérdida de conexión a la misma toda la herramienta de integración queda inutilizable.
En el caso de las soluciones de InterSystems este problema no existe, al ser la base de datos parte y nucleo de las propias herramientas. ¿Y cómo ha solucionado InterSystems el problema de la alta disponibilidad? ¿Con abstrusas configuraciones que podrían arrastrarnos a una espiral de enajenamiento y locura? ¡NO! Desde InterSystems hemos escuchado y atendido vuestras quejas (como siempre intentamos hacer ;) ) y hemos puesto a disposición de todos nuestros usuarios y desarrolladores la función de mirroring.
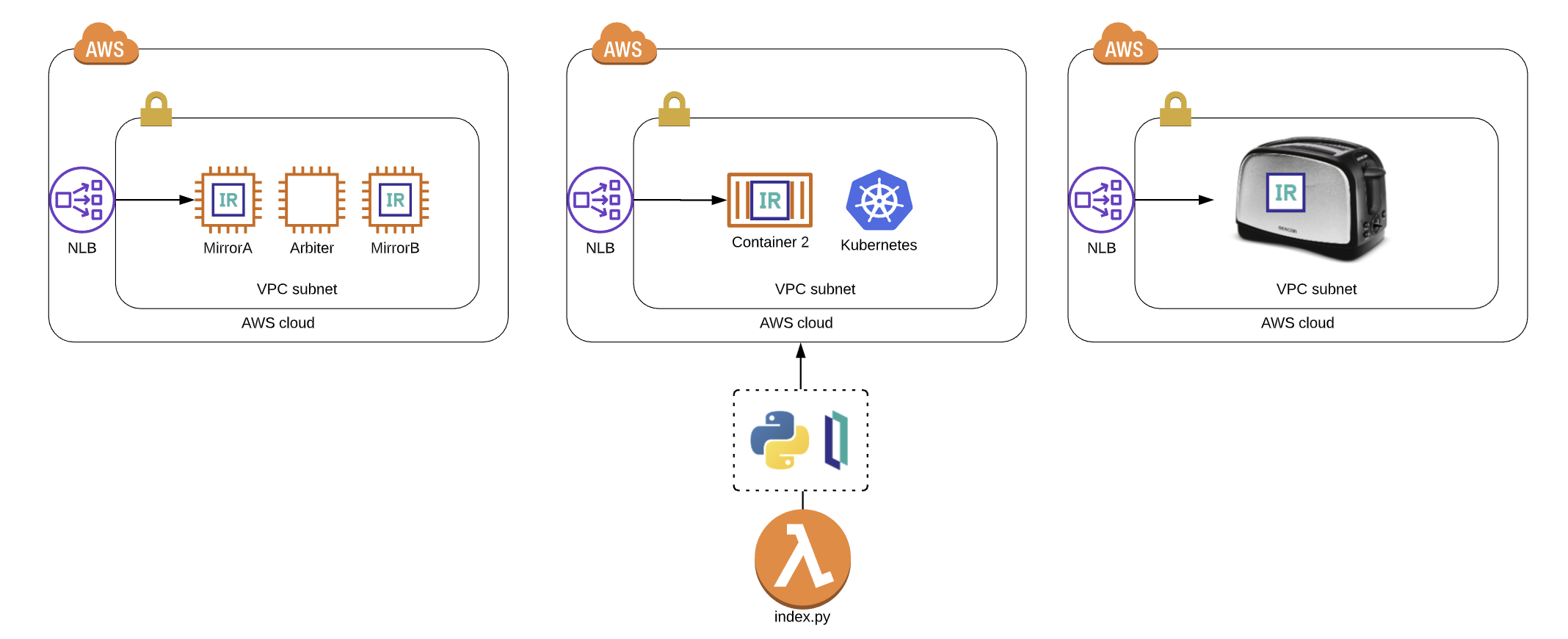
Mirroring
¿Cómo funciona el Mirror? El concepto en si es muy sencillo. Como ya sabréis tanto IRIS como HealthShare trabajan con un sistema de journaling que registra toda operación de actualización sobre las bases de datos de cada instancia. Este sistema de journaling es el que posteriormente nos sirve para recuperar las instancias sin apenas pérdida de datos en caso de caída de las mismas. Pues bien, son estos archivos de journal los que se envían entre las instancias configuradas en mirror y permiten mantener permanentemente actualizados las instancias configuradas en mirror.
Arquitectura
Expliquemos brevemente como sería la arquitectura de un sistema configurado en Mirror:
Dos instancias configuradas en modo Failover:
Nodo activo: recibe todas las operaciones de lectura/escritura habituales.
Nodo pasivo: en modo lectura, recibe de forma síncrona cualquier cambio producido en el nodo activo.
0-14 instancias asíncronas: tantas instancias asíncronas como se quieran utilizar, pueden ser de dos tipos:
DR async (Disaster Recovery): nodos en modo lectura que no forman parte del Failover aunque se le puede promocionar manualmente.De ser así podría llegar a promocionarse automáticamente a nodo primario en caso de caída de los otros dos nodos del Failover. La actualización de sus datos es en modo asíncrono, por lo que no se garantiza la frescura de los mismos.
Reporting Asyncs: nodos actualizados de forma asíncrona para su uso en tareas de BI o explotaciones de datos. No pueden ser promocionados al Failover ya que se pueden realizar escrituras sobre los datos.
ISCAgent: instalado en cada servidor donde se encuentre una instancia. Será el encargado de monitorizar el estado de las instancias de dicho servidor. Es otra vía de comunicación entre los servidores del Mirror además de la comunicación directa.
Arbiter: es un ISCAgent instalado de forma independiente a los servidores que forman el Mirror y permite aumentar la seguridad y el control de los failover dentro del mismo monitorizando tanto a los ISCAgent instalados como a las instancias de IRIS/HealthShare. Su instalación no es obligatoria.
Este sería el funcionamiento de un Mirror formado por un failover con dos únicos nodos:
Aviso previo
El proyecto asociado a este artículo no dispone de una licencia activa que permita la configuración del mirror. Si queréis probarlo enviadme directamente un email o añadid un comentario al final del artículo y me pondré en contacto con vosotros.
Despliegue en Docker
Para este artículo vamos primeramente a montar un pequeño proyecto en Docker que nos permita montar 2 instancias en failover con un Arbiter. Por defecto las imágenes de IRIS disponibles para Docker tienen ya instalado y configurado el ISCAgent, por lo que nos podremos saltar ese paso. Será necesario configurar el proyecto que viene asociado al artículo desde un Visual Studio Code, ya que nos permitirá posteriormente trabajar de una forma más cómoda con los archivos del servidor.
Veamos que forma tendría nuestro docker-compose.yml:
version: '3.3'
services:
arbiter:
container_name: arbiter
hostname: arbiter
image: containers.intersystems.com/intersystems/arbiter:2022.1.0.209.0
init: true
command:
- /usr/local/etc/irissys/startISCAgent.sh 2188
mirrorA:
image: containers.intersystems.com/intersystems/iris:2022.1.0.209.0
container_name: mirrorA
depends_on:
- arbiter
ports:
- "52775:52773"
volumes:
- ./sharedA:/shared
- ./install:/install
- ./management:/management
command:
--check-caps false
--key /install/iris.key
-a /install/installer.sh
environment:
- ISC_DATA_DIRECTORY=/shared/durable
hostname: mirrorA
mirrorB:
image: containers.intersystems.com/intersystems/iris:2022.1.0.209.0
container_name: mirrorB
depends_on:
- arbiter
- mirrorA
ports:
- "52776:52773"
volumes:
- ./sharedB:/shared
- ./install:/install
- ./management:/management
command:
--check-caps false
--key /install/iris.key
-a /install/installer.sh
environment:
- ISC_DATA_DIRECTORY=/shared/durable
hostname: mirrorB
Podemos ver que tenemos definidos 3 containers:
Arbiter: correspondiente al ISCAgent (aunque la imagen se llame Arbiter) que se desplegará para el control de las instancias de IRIS que formarán el Failover del Mirror. Al arrancar el container ejecutará un fichero shell que arrancará el ISCAgent escuchando en el puerto 2188 del container.
mirrorA: container en el que se desplegará la imagen de IRIS v.2022.1.0.209 y que posteriormente configuraremos como nodo primario del Failover.
mirrorB: container en el que se desplegará la imagen de IRIS v.2022.1.0.209 y que posteriormente configuraremos como nodo secundario del Failover.
Cuando ejecutemos el comando docker-compose up -d se desplegarán en nuestro Docker los contenedores definidos, debiendose ver tal que así en nuestro Docker Desktop (si lo hacemos desde Windows).
Configuración del mirror.
Con nuestros contenedores desplegados procederemos a acceder a las instancias que vamos a configurar en mirror, la primera se encontrará escuchando en el puerto 52775 (mirrorA) y la segunda en el 52776 (mirrorB). El usuario y la contraseña de acceso serán superuser / SYS
Debido a la que las instancias se encuentran desplegadas en Docker, tendremos dos opciones de para configurar las IP de nuestros servidores. La primera es usar directamente el nombre de nuestros contenedores en la configuración (que es la más sencilla) o bien comprobar las IP que Docker ha asignado a cada contenedor (abriendo la consola y ejecutando un ifconfig que nos devuelva la IP asignada). Por motivos de claridad utilizaremos para el ejemplo los nombres que les hemos dado a cada contenedor como dirección de cada uno dentro de Docker.
Primeramente configuraremos la instancia que utilizaremos como nodo activo del FailOver. En nuestro caso será la que hemos denominado mirrorA.
El primer paso será habilitar el servicio de mirroring, por lo que accederemos al menú de mirror desde el portál de gestión: System Adminsitration --> Configuration --> Mirror Settings --> Enable Mirror Service y marcaremos el check de Service Enabled:
Con el servicio habilitado ya podremos empezar a configurar nuestro nodo activo. Tras habilitar el servicio podréis observar que se han habilitado nuevas opciones en el menú de Mirror:
En este caso, al no tener ninguna configuración de mirror ya creada deberemos crear una nueva con la opción de Create Mirror. Cuando accedemos a dicha opción el portal de gestión nos abrirá una nueva ventana desde la que podremos configurar nuestro mirror:
Veamos con más detalle cada una de las opciones:
Mirror Name: el nombre con el que identificaremos a nuestro mirror. Para nuestro ejemplo lo llamaremos MIRRORSET
Require SSL/TLS: para nuestro ejemplo no configuraremos conexión mediante SSL/TLS aunque en entornos productivos sería más que conveniente para evitar que el archivo de journal se comparta sin ningún tipo de cifrado entre las instancias. Si tenéis interés en configurarlo tenéis toda la información necesaria en la siguiente URL de la documentación.
Use Arbiter: esta opción no es obligatoria, pero es bastante recomendable, ya que añade una capa de seguridad a la configuración de nuestro mirror. Para nuestro ejemplo lo dejaremos marcado e indicaremos la IP en el que tenemos funcionando nuestro Arbiter. Para nuestro ejemplo la IP será en nombre de contenedor "arbiter".
User Virtual IP: en entornos Linux/Unix está opción es muy intersante ya que nos permite configurar una IP virtual para nuestro nodo activo que será gestionada por nuestro Mirror. Esta IP virtual debe pertenecer a la misma subred en la que se encuentren los nodos del Failover. El funcionamiento de la IP virtual es muy sencillo, en caso de caída del nodo activo el mirror configurará automáticamente la IP virtual en el servidor en el que se encuentre el nodo pasivo que va a ser promocionado. De tal forma, la promoción del nodo pasivo a activo será totalmente transparente para los usuarios, ya que estos seguirán conectados a la misma IP, aunque esta se encontrará configurada en un servidor distinto. Si queréis saber más al respecto de la IP virtual podéis revisar esta URL de la documentación.
El resto de la configuración podemos dejarla tal como está. En el lado derecho de la pantalla veremos la información relativa a este nodo en el mirror:
Mirror Member Name: nombre de este miembro del mirror, por defecto tomará el nombre del servidor junto con el de la instancia.
Superserver Address: dirección IP del superserver de este nodo, en nuestro caso, mirrorA.
Agent Port: puerto en el que se ha configurado el ISCAgent correspondiente a este nodo. Por defecto el 2188.
Una vez configurado los campos necesarios podemos proceder a guardar el mirror. Podemos comprobar como ha quedado la configuración desde el monitor del mirror (System Operation --> Mirror Monitor).
Perfecto, aquí tenemos nuestro mirror recién configurado. Como véis únicamente figura el nodo activo que acabamos de crear. Muy bien, vayamos entonces a añadir nuestro nodo pasivo en el Failover. Accedemos al portal de gestión de mirrorB y accedemos al menú de Mirror Settings. Como ya hicimos para la instancia de mirrorA deberemos habilitar el servicio de Mirror. Repetimos la operación y en cuanto se actualicen las opciones del menú elegiremos Join as Failover.
Aquí tenemos la pantalla de conexión al mirror. Expliquemos brevemente que son cada uno de los campos:
Mirror Name: nombre que dimos al mirror en el momento de la creación, en nuestro ejemplo MIRRORSET.
Agent Address on Other System: IP del servidor en el que se encuentra desplegado el ISCAgent del nodo activo, para nosotros será mirrorA
Agent Port: puerto de escucha del ISCAgent del servidor en el que creamos el mirror. Por defecto el 2188.
InterSystems IRIS Instance Name: el nombre de la instancia de IRIS en el nodo activo. En este caso coincide con el del nodo pasivo, IRIS.
Tras grabar los datos del mirror tendremos la opción de definir la información relativa al nodo pasivo que estamos configurando. Echemos nuevamente un vistazo a los campos que podemos configurar del nodo pasivo:
Mirror Member Name: nombre que tomará el nodo pasivo en el mirror. Por defecto formado por el nombre del servidor y la instancia.
Superserver Address: dirección IP de acceso al superserver nuestro nodo pasivo. En este caso mirrorB.
Agent Port: puerto de escucha del ISCAgent instalado en el servidor del nodo pasivo que estamos configurando. Por defecto el 2188.
SSL/TLS Requirement: al no configurarlo en la declaración del mirror no es configurable.
Mirror Private Address: dirección IP del nodo pasivo. Como hemos visto, al usar Docker podremos usar el nombre del contenedor mirrorB.
Agent Address: dirección IP al servidor donde está instalado el ISCAgent. Igual que antes, mirrorB.
Grabamos la configuración tal y como hemos indicado y volvemos al monitor del mirror para comprobar que tenemos todo correctamente configurado. Podemos visualizar el monitor tanto del nodo activo en mirrorA como el del pasivo en mirrorB. Veamos las sutiles diferencias entre ambos.
Monitor del mirror en nodo activo mirrorA:
Monitor del mirror en nodo pasivo mirrorB:
Como véis la información mostrada el similar, cambiando básicamente el orden de los miembros del failover. También las opciones son distintas, veamos alguna de ellas:
Nodo activo mirrorA:
Set No Failover: impide la ejecución del failover en caso de parada de alguna de las instancias que forman parte de él.
Demote other member: elimina al otro miembro del failover (en este caso mirrorB) de la configuración del mirror.
Nodo pasivo mirrorB:
Stop Mirror On This Member: detiene la sincronización del mirror en el nodo pasivo del failover.
Demote To DR Member: "degrada" a este nodo pasando de formar parte del failover con su sincronización en tiempo real al modo Disaster Recovery en modo asíncrono.
Perfecto, ya tenemos nuestros nodos configurados, ahora nos queda el paso final en nuestra configuración. Decidir que tablas pasaran a formar parte del mirror y configurarlo en ambos nodos. Si observáis el README.md del proyecto asociado a este artículo veréis que indicamos la existencia de dos aplicaciones que usamos habitualmente para las formaciones y que son automáticamente desplegadas al arrancar los contenedores de Docker.
La ventaja de usar esta configuración es que no tendremos que replicar a mano los NAMESPACES ni las bases de datos relacionadas de cara a configurar a mano el mirror, ya tenemos en ambas instancias los mismos namespaces y bases de datos.
La primera es COMPANY que nos permite guardar registros de empresas y la segunda es PHONEBOOK que nos permite añadir contactos de personal relacionados con las empresas registradas, así como clientes.
Añadamos una compañía:
Y a continuación un contacto de dicha compañía:
Los datos de la compañía se registrarán en la base de datos COMPANY y los del contacto en PERSONAL, ambas bases de datos están mapeadas para que puedan ser accesibles desde el Namespace PHONEBOOK. Si comprobamos las tablas en ambos nodos veremos que en mirrorA tenemos los datos tanto de la compañía como del contacto pero que el mirrorB aún no hay nada, como es lógico.
Compañías registradas en mirrorA:
Muy bien, procedamos a configurar las bases de datos en nuestro mirror. Para ello, desde nuestro nodo activo (mirrorA), accedemos a la pantalla de administración de las bases de datos locales (System Administrator --> Configuration --> System Configuration --> Local Databases) y pulsamos en la opción de Add to Mirror, seleccionamos de la lista las bases de datos que queremos añadir leyendo con detenimiento el mensaje que se nos muestra en pantalla:
Una vez que hayamos añadido las bases de datos al mirror desde el nodo activo deberemos realizar un backup de las mismas o bien copiar los archivos de base de datos (IRIS.dat) y restaurarlos sobre el nodo pasivo. Si decidís realizar la copia directa de los archivos IRIS.dat tened en cuenta que debería realizarse previamente una pausa de la escritura en el fichero, podéis ver los comandos necesarios en la siguiente URL de la documentación. En nuestro ejemplo no será necesario realizar dicha pausa ya que nadie más que nosotros estamos escribiendo en ella.
Antes de realizar dicha copia de los archivos de las bases de datos comprobemos el estado del mirror desde el monitor del nodo activo:
Veamos ahora el nodo pasivo:
Como podemos observar, desde el nodo pasivo se nos está informando que si bien tenemos configuradas 3 bases de datos en el mirror la configuración aún no está hecha. Procedamos a copiar las bases de datos del nodo activo al pasivo, no olvidemos que debemos desmontar las bases de datos del nodo pasivo para poder hacer la copia y para ello accederemos desde el portal de gestión a System Configuration --> Databases y accediendo a cada una de ellas procedemos a desmontarlas.
¡Perfecto! Bases de datos desmontadas. Accedamos al código del proyecto asociado al artículo desde Visual Studio Code y vemos que tenemos una serie de carpetas donde se encuentran las instalaciones de IRIS, sharedA para el mirrorA y sharedB para el mirrorB. Accedamos a las carpetas donde se encuentran las base de datos COMPANY, CUSTOMER y PERSONAL en (/sharedA/durable/mgr) y procedamos a copiar los IRIS.dat de cada base de datos en el mirror a los directorios oportunos del mirrorB (/sharedB/durable/mgr).
Una vez finalizada la copia montamos nuevamente las bases de datos de mirrorB y comprobamos desde el monitor del mirror en mirrorB el estado de las bases de datos configuradas:
¡Bingo! nuestro mirror ha reconocido las bases de datos y ahora sólo necesitaremos activarlas y ponerlas al día. Para ello pulsaremos sobre la acción Activate y a continuación sobre Catchup, que aprecerá tras la activación. Veamos como quedan finalmente:
Perfecto, nuestras bases de datos ya están correctamente configuradas en mirror, si consultamos la base de datos de COMPANY deberíamos ver la que registramos inicialmente desde mirrorA:
Obviamente nuestra base de datos COMPANY tiene el registro que introdujimos con anterioridad en mirrorA, al fin y al cabo hemos copiado toda la base de datos. Procedamos a añadir una nueva empresa desde mirrorA a la que llamaremos "Another company" y procedamos a consultar nuevamente la tabla de la base de datos COMPANY:
Aquí la tenemos. Únicamente nos quedará asegurarnos de que nuestras bases de datos configuradas en mirror se encuentran únicamente en modo lectura en nuestro nodo pasivo mirrorB:
¡Ahí están! en modo R de lectura. Pues ya tenemos nuestro mirror configurado y nuestras bases de datos sincronizadas. En el caso de que tuviesemos funcionando producciones no sería ningún problema ya que el mirror se encarga de forma automática de gestionarlas, arrancándolas en el nodo pasivo caso de caída del nodo activo.
¡Muchas gracias todos los que habéis llegado hasta este punto! Ha sido largo pero confío que os resulte de utilidad.
Artículo
Mario Sanchez Macias · 13 sep, 2022
Nota: Lo que sigue es solo una guía. Cada cliente es diferente.
A través de nuestra experiencia en soporte ayudando a clientes, hemos visto muchos casos en los que no tener un plan de actualización adecuado (y documentado) conduce a problemas inesperados con prioridad de Crisis. En algunos casos, podemos solucionar el problema durante el periodo de actualización, pero no siempre, ya que algunas situaciones pueden requerir una investigación más exhaustiva que puede llevar días o incluso meses.
Es esencial documentar el proceso de actualización, incluyendo los pasos que se deben efectuar antes, durante y después de la actualización, ¡incluso en servidores y aplicaciones pequeñas! Además, un plan de actualización documentado es muy útil cuando involucra a terceros, como proveedores de software o hardware. Al entregar este documento a un proveedor externo (como InterSystems) se acelerará la comprensión de todo el contexto.
Después de trabajar con diferentes documentos, me gustaría compartir unas instrucciones generales para ayudaros a crear un plan de actualización o para ponerlo al día. Por supuesto, se me escaparán algunas cosas. Estoy seguro de que algunos de vosotros tenéis mucha experiencia y podréis añadir ideas y sugerencias, ¡así que no dudéis en comentar este artículo!
Nota: Lo que sigue es solo una guía. Cada cliente es diferente.
Manual para realizar actualizaciones con éxito
Cada actualización a una versión principal (major) debería tener unos pasos y estrategias imprescindibles, similares a las que se describen aquí. Nuestra experiencia con clientes demuestra que un plan detallado es clave para una actualización con éxito, con pruebas y acciones documentadas.
Introducción
Incluye una breve descripción de la actualización, sin detalles. Incluye el objetivo y la situación actual.
1. Infraestructura
Incluye una tabla con los datos esenciales y documentos detallados (listos para ser enviados). Debe incluir la arquitectura actual y la futura (si corresponde).
Arquitectura ACTUAL (ejemplo general)
Servidor
IP
FUNCIÓN
HW
Producto
Sistema Operativo
PROD1
192.178.1.10
REPLICAR
10 cores 20 RAM
Caché 2017.2
Windows 2012
PROD2
192.178.1.11
REPLICAR
10 cores 20 RAM
Caché 2017.2
Windows 2012
192.178.1.30
VIP
ARB
192.178.1.12
Árbitro
2 cores 4 RAM
Caché 2017.2
Windows 2012
BCK
192.178.1.13
Recuperación en caso de desastre (DR)
24cores 10 RAM
Caché 2017.2
Windows 2012
DetallesExtrae los siguientes datos y guárdalos en un sitio compartido, listos para ser enviados si alguien los requiere:
Informe de ^Buttons o ^SystemCheck para cada servidor
Informe de ^Buttons o ^SystemPerformance para cada servidor. Los datos deben abarcar unos cuantos días, incluyendo el día de mayor actividad
Detalles del hardware (proveedor, especificaciones, etc.)
Arquitectura FUTURA (si está prevista su actualización)
Obtener datos similares a los de la arquitectura actual.
2. Contactos
Puede parecer de sentido común, pero es esencial saber quién tiene autoridad para tomar decisiones relacionadas con las actualizaciones, quién está a cargo de qué y a quién hay que contactar en caso de emergencia. Es imprescindible disponer de una tabla sencilla adjunta al documento de actualización.
Nombre
Función
Empresa
Teléfono
Correo electrónico
John
Administrador
ACME
+34222222
John@acme.com
Gary
Desarrollador
ACME
+34222222
Gary@acme.com
Susan
Gestor
ACME
+34222222
susana@acme.com
Centro de Soporte Internacional (WRC)
Soporte de InterSystems (ISC)
InterSystems
+112321321
support@intersytems.com
Dell
Soporte de Dell
Dell
+1xxx
support@delll.com
3. Plan de prueba y detalles
Incluye una descripción de las pruebas realizadas actualmente y las previstas. Las pruebas deben abarcar una actualización completa con un entorno similar. Las pruebas de actualización deberían permitir completar las siguientes secciones sobre la actualización. Si no hay pruebas o no se han completado, deberá anotarse y prepararse para cruzar los dedos. ;-)
4. Principales pasos de la actualización
Debería incluir un resumen sencillo de los diferentes pasos. Por ejemplo:
Stop instances (Prod1 and Prod2)
Copy database folders to new systems (NewProd1 and NewProd2)
Start NewProd1
Compile classes on new Prod1, run update data scripts
Start NewProd2
Check Mirror synch
Assign old IPs
Allow users to connect
5. Detalles del plan
Detalla los pasos anteriores y cómo realizarlos, incluyendo los comandos que se deben ejecutar, los archivos para importar, etc. La mayoría de los pasos no son útiles para empresas externas que no conocen las aplicaciones, y puede que no sea necesario incluirlas cuando se envíe el plan a terceros.
6. Tareas relacionadas
Las actualizaciones, incluyendo los cambios en las aplicaciones, normalmente requieren tareas que hay que realizar antes, durante y después. Se puede crear una sencilla tabla de tareas para controlar todos los pasos, los tiempos, etc.
Un plan detallado pueden incluir cosas como:
Tareas previas a la actualización (ejemplo)
(Detallar todas las tareas necesarias antes de la actualización)
Tarea
Fecha
Estado
Responsable
Notas
Actualizar índices
09/07/22
Hecho
Integración
Actualizar los índices en X para soportar XY
Actualizar el IIS
09/08/22
Pendiente
Administración Web
Actualizar los servidores web antes de realizar la actualización final
Obtener el informe de integridad
09/07/22
Hecho
Administración de Iris
Obtener un informe de integridad de todas las bases de datos
Tareas durante la actualización (ejemplo)
(Detallar las tareas y el plan de actualización paso a paso)
Tarea
Hora (planificada)
Hora (real)
Estado
Responsable
Notas
Parar a los usuarios
06:00
06:10
Pendiente
Integración
Llamar a X para detener las conexiones
Obtener ^SystemCheck
06:10
Pendiente
Administración de Iris
...
..
...
...
Permitir conexiones
09:10
Pendiente
Administración de Iris
Tareas después de la actualización
(Detallar todas las tareas necesarias después de la actualización)
Tarea
Fecha
Estado
Responsable
Notas
Activar ^SystemPerformance
01/01/22
Pendiente
Administración de Iris
Ejecutar el funcionamiento durante unos días
5. Incidencias/Problemas durante la actualización
Escribe los problemas encontrados durante la actualización. Especialmente los problemas que no impidan la actualización. Esta lista puede incluir una falta de comandos necesarios, mensajes de error nuevos, etc. Esta lista te ayudará a mejorar los documentos de actualización futuros y a que no te olvides de arreglar los problemas actuales.
6. Plan de recuperación en caso de desastres / Regresar
Describe el plan en caso de que la actualización falle. Esto debería implicar volver a los antiguos servidores, detener los nuevos, iniciar X, Z, etc. Es útil tener escritos todos los pasos para volver a un escenario de seguridad. Recuerda que el plan de recuperación en caso de desastres normalmente se realiza bajo estrés, y es fácil omitir pasos y olvidar cómo hacerlo o dónde están los archivos, las configuraciones, etc.
Este plan de recuperación debería ser un enlace o ampliación al documento de recuperación existente. Y sino hubiese ninguno, sería un buen momento de crearlo, ya sabéis, la ley de Murphy...
* * *
El objetivo principal de esta guía es que conozcas las dificultades del proceso de actualización y que pienses por adelantado.
Probar, documentar y volver a probar es la garantía de actualizaciones con éxito.
Artículo
Ricardo Paiva · 25 feb, 2021
> **Nota (junio de 2019)**: han cambiado muchas cosas [para obtener los detalles más recientes, haz clic aquí](https://community.intersystems.com/post/unpacking-pbuttons-yape-update-notes-and-quick-guides)
> **Nota (septiembre de 2018)**: ha habido grandes cambios desde que esta publicación apareció por primera vez; sugiero que utilices la versión del contenedor en Docker dado que el proyecto y la información para que se ejecute como un contenedor sigue [publicada en GitHub](https://github.com/murrayo/yape), en el mismo lugar, para que puedas descargarlo, ejecutarlo y modificarlo, si lo necesitas.
Cuando trabajo con clientes en revisiones de rendimiento, planificaciones de capacidad y resolución de problemas, con frecuencia tengo que descomprimir y revisar las métricas del sistema operativo y de caché desde pButtons. En vez de lidiar con los archivos html para cortar y pegar secciones que serán graficadas en Excel, [hace algún tiempo escribí una publicación sobre una herramienta para descomprimir las métricas de pButtons](https://community.intersystems.com/post/extracting-pbuttons-data-csv-file-easy-charting), escrita con el intérprete de unix, perl y los scripts de awk. Si bien este es un *valioso ahorro de tiempo*, no es la historia completa…
También utilizo scripts para realizar automáticamente gráficos de las métricas, para revisiones rápidas y para inconporarlos a informes. Sin embargo, estos gráficos realizados con scripts no se mantienen fácilmente y se vuelven especialmente confusos cuando se necesita una configuración específica del sitio, por ejemplo, una lista de discos para iostat o windows perfmon. Por eso, nunca publiqué las herramientas para hacer gráficos. Pero estoy muy contento de anunciar que ahora existe una solución mucho más sencilla.
El descubrimiento fortuito ocurrió cuando estaba en las instalaciones de un cliente observando el rendimiento del sistema con [ Fabian, y él me mostró lo que hacía para utilizar ciertos módulos de Python para realizar gráficos](https://community.intersystems.com/post/visualizing-data-jungle-part-i-lets-make-graph). Esta es una solución mucho más flexible y fácil de mantener que los scripts que utilizaba. Y la facilidad de integrar los módulos de Python para administrar archivos y gráficos, incluyendo la posibilidad de compartir el html interactivo, significa que el resultado puede ser mucho más útil. Al tomar las publicaciones de Fabian como base, escribí __Yape__ para extraer de forma rápida y sencilla, y luego hacer gráficos de los archivos pButtons de los clientes, en varios formatos. El proyecto se [publicó en GitHub](https://github.com/murrayo/yape) para que puedas descargarlo, ejecutarlo y modificarlo, si lo necesitas.
## Resumen
Actualmente, este proceso consiste en _dos_ pasos.
### Paso 1. `extract_pButtons.py`
Extrae las secciones de interés desde pButtons, y escríbelas en archivos de tipo .csv para abrirlos con Excel o para que se procesen con gráficos utilizando `graph_pButtons.py`.
### Paso 2. `graph_pButtons.py`
Los archivos de gráficos se crearon en el Paso 1. Actualmente las salidas pueden ser gráficas de líneas o de puntos que se representan como `.png` o `.html interactivos` e incluyen opciones de vista panorámica, zoom, impresión, etc.
_Readme.md_ en GitHub tiene especificaciones sobre cómo configurar y ejecutar los dos scripts de Python, y será la referencia más reciente.
## Notas adicionales
Por ejemplo: si utilizas las opciones para agregar prefijos a los directorios de entrada y salida, podrás examinar fácilmente un directorio con un conjunto de archivos pButtons de html (por ejemplo, semanas) y enviarlos a un directorio separado para cada archivo pButtons.
for i in `ls *.html`; do ./extract_pButtons.py $i -p ${i}_; done
for i in `ls *.html`; do ./graph_pButtons.py ./${i}_metrics -p ${i}_; done
A corto plazo, mientras continúo con la serie sobre [cómo planificar y aumentar rendimiento de la plataforma de datos InterSystems IRIS](https://community.intersystems.com/post/intersystems-data-platforms-capacity-planning-and-performance-series-index), utilizaré los gráficos creados con estas herramientas.
Lo probé en OS X, pero no en Windows. No debería tener ningún problema para instalar y ejecutar Python en Windows. Supongo que necesitarás realizar algunos cambios en las barras que se encuentran en la ruta de un archivo. Deja tus comentarios si lo pruebas.
> Nota: hasta hace unas semanas nunca había escrito nada en Python, así que si es un experto en este lenguaje, posiblemente te darás cuenta de que algunas partes del código no siguen las prácticas recomendadas. Sin embargo, utilizo los scripts casi todos los días, por lo que seguiré mejorándolos. Espero perfeccionar mis habilidades en Python, ¡pero siéntete libre de “educarme” si ves algo que debería corregirse!
Si descubres que los scripts te resultan útiles, házmelo saber y vuelve con frecuencia para obtener nuevas características y actualizaciones.
Artículo
Pablo Frigolett · 22 nov, 2021
Servidor Externo de Lenguaje Python en un contenedor
La primera vez que se intenta iniciar un servidor externo de lenguaje Python (de aquí en adelante Gateway de Python), en la versión en contenedor, intenta ejecutar cierto código para detectar si está instalado el paquete python3-venv.
La imagen que está en containers.intersystems.com:
a la fecha de este artículo es la versión 2021.1.0.215.0
está basada en Ubuntu 18 LTS
viene con python 3.6.9 instalado
Para trascender al contenedor en inicio de nuestro Gateway de Python - para las actualizaciones por ejemplo - es necesario tener un punto de montaje externo para /usr/irissys/dev/python/virtual. Allí se registra los entornos virtuales de python que IRIS crea cuando inicia por primera vez un Gateway de Python. El usuario de sistema operativo que ejecuta los scripts de inicio del Gateway de Python, debe poder escribir en ese directorio. La razón es que además de crear allí el entorno virtual de python, cada vez que se intenta iniciar el Gateway, intenta crear un archivo temporal de prueba allí.
A continuación haremos:
creación de un contenedor con pasos adicionales para el inicio por primera vez del Gateway de Python. Los pasos adicionales son incluir un punto de mensaje, instalar unos paquetes e iniciar por primera vez el Gateway de Python.
creación de un contenedor con menos pasos adicionales para los subsecuentes inicios del Gateway Python. Los pasos adicionales son incluir el punto de montaje para python y darle privilegio de escritura a todos los usuarios.
Creación de un contenedor e inicio del Gateway de Python por primera vez
Este paso crea el contenedor de la misma forma que se creará en otras ocasiones agregando la instalación del paquete python3-venv y sus dependencias, el inicio del Gateway de Python. Se asume que en el directorio /data/durable (también en negrita en el comando) está el archivo iris.key. Y la versión del contenedor es la que existía al momento de escribir este artículo. En el directorio /data/python se creará el entorno virtual de python. Ese directorio se vuelve read-only al menos en versiones docker-desktop en Mac y docker-ce en linux. Por eso el comando que sigue a la creación busca dar permiso para la creación del entorno virtual de python al usuario que ejecute IRIS en el contenedor.
Entonces para crear el contenedor aqui va el método más crudo (directo con docker):
docker run -d -v /data/durable:/dur -v /data/python:/usr/irissys/dev/python/virtual --name iris --cap-add IPC_LOCK containers.intersystems.com/intersystems/iris:2021.1.0.215.0 --key /dur/iris.key
chmod 777 /data/python
Ahora es necesario instalar el paquete python3-venv con sus dependencias e iniciar el Gateway de Python. El contenedor necesita acceso a internet y el comando se ejecuta como root (-u 0).
docker exec -u 0 iris bash -c "apt-get update && apt-get install -y python3-venv"
Si todo va bien, veremos en la últimas líneas "Setting up python3-venv" entre otros mensajes.
Con esto, solamente faltaría iniciar el Gateway de Python que puede tomar desde los 20s mientras crea el entorno virtual, instala el módulo de iris nativo e inicia el proceso :
docker exec iris iris terminal IRIS <<EOFCMD
w "Iniciando:",\$system.external.startServer("%Python Server")
w "Terminando:",\$system.external.stopServer("%Python Server")
halt
EOFCMD
con esto, el entorno virtual queda creado en /data/python/'%Python Server_3252368016' que puede ser compartido con otros contenedores. Para no seguir con un contenedor con paquetes instalados inútilmente, eliminamos el contenedor para volver a crearlo en el próximo paso.
docker stop iris
docker rm iris
Creación de un contenedor con menos pasos adicionales
Ya creado nuestro entorno virtual Python, el único paso adicional necesario a dar permiso de escritura en la carpeta que es montada (en Mac y Linux al menos). De nuevo, directo desde docker:
docker run -d -v /data/durable:/dur -v /data/python:/usr/irissys/dev/python/virtual --name iris --cap-add IPC_LOCK containers.intersystems.com/intersystems/iris:2021.1.0.215.0 --key /dur/iris.key
chmod 777 /data/python
El tema de los permisos en mi caso fue devastador. Tuve la suerte de encontrarme con ese problema y tener que indagar qué estaba haciendo que fallara el inicio del Gateway de Python. Los scripts setup.sh y runpython.sh ubicados en /usr/irissys/dev/python eran los que se caian con diversos problemas (que no podían crear un archivo, que no estaba el paquete python3-venv, etc.).
Suerte!
Artículo
Ricardo Paiva · 9 feb, 2023
Hola a todos,
Aquí estamos de nuevo. Nuevo año, nuevo concurso, nuevo proyecto, viejos motivos.
¡Triple Slash ya está en casa!
1999, el año que aprendí a programar, mi primer "if," mi primer "Hello world."
Aún recuerdo a mi profesor explicándonos en aquella clase el sencillo "while" y cómo podemos saber si se cumplió una condición específica. ¿Te acuerdas, @Renato.Banzai? El profesor Barbosa, un tipo único.
Desde entonces, me ha encantado la idea de programar, transformando ideas en proyectos, en algo útil. Pero todos sabemos que para crear algo, necesitamos asegurarnos de que está funcionando; necesitamos no solo crear, sino también probar si funciona y si no se rompe si añadimos algo nuevo.
Y para ser honesto con todos vosotros, hacer pruebas es aburrido. Al menos para mí, no tengo nada contra vosotros si os gusta.
Usando una analogía, podría decir que crear métodos de prueba es como limpiar la casa o planchar la ropa. Es aburrido, pero necesario.
Con estas ideas en mente, ¿por qué no desarrollar una forma mejor y más sencilla de probar?
Así que, inspirado por el estilo de elixir y por esta idea de InterSystems Ideas (gracias, @Evgeny.Shvarov), intentamos mejorar el proceso de prueba y convertirlo en una tarea divertida otra vez.
Simplificamos el %UnitTest y para mostraros cómo usar TripleSlash para crear pruebas unitarias (unit tests), vamos a utilizar un ejemplo sencillo.
Pongamos que tienes la siguiente clase y método del que te gustaría escribir una prueba unitaria:
Class dc.sample.ObjectScript
{
ClassMethod TheAnswerForEverything() As %Integer
{
Set a = 42
Write "Hello World!",!
Write "This is InterSystems IRIS with version ",$zv,!
Write "Current time is: "_$zdt($h,2)
Return a
}
}
Como se puede ver, el método TheAnswerForEverything() solo devuelve el número 42. Así que vamos a marcar en la documentación del método cómo TripleSlash debería crear una prueba unitaria para este método:
/// A simple method for testing purpose.
///
/// <example>
/// Write ##class(dc.sample.ObjectScript).Test()
/// 42
/// </example>
ClassMethod TheAnswerForEverything() As %Integer
{
...
}
Las pruebas unitarias deben estar todas en una etiqueta <example></example>. Se puede añadir cualquier tipo de documentación, pero todas las pruebas tienen que estar dentro de ese tipo de etiqueta.
Ahora, arranca una instancia de IRIS e inicia una sesión de terminal, ve al namespace IRISAPP, crea una instancia de la clase Core pasando el nombre de clase (o su nombre de paquete para todas sus clases) y después ejecuta el método Execute():
USER>ZN "IRISAPP"
IRISAPP>Do ##class(iris.tripleSlash.Core).%New("dc.sample.ObjectScript").Execute()
TripleSlash interpretará esto como "Dado el resultado del método Test(), afirmo que es igual a 42". Así que se creará una nueva clase dentro de la prueba unitaria:
Class iris.tripleSlash.tst.ObjectScript Extends %UnitTest.TestCase
{
Method TestTheAnswerForEverything()
{
Do $$$AssertEquals(##class(dc.sample.ObjectScript).TheAnswerForEverything(), 42)
}
}
Ahora, vamos a añadir un nuevo método para probar otras formas de decir a TripleSlash cómo escribir las pruebas unitarias.
Class dc.sample.ObjectScript
{
ClassMethod GuessTheNumber(pNumber As %Integer) As %Status
{
Set st = $$$OK
Set theAnswerForEveryThing = 42
Try {
Throw:(pNumber '= theAnswerForEveryThing) ##class(%Exception.StatusException).%New("Sorry, wrong number...")
} Catch(e) {
Set st = e.AsStatus()
}
Return st
}
}
Como se puede ver, el método GuessTheNumber() espera un número, devuelve $$$OK solo cuando se pasa como argumento el número 42 o un error para cualquier otro valor. Así que vamos a marcar en la documentación del método cómo TripleSlash debería crear una prueba unitaria para este método:
/// Another simple method for testing purpose.
///
/// <example>
/// Do ##class(dc.sample.ObjectScript).GuessTheNumber(42)
/// $$$OK
/// Do ##class(dc.sample.ObjectScript).GuessTheNumber(23)
/// $$$NotOK
/// </example>
ClassMethod GuessTheNumber(pNumber As %Integer) As %Status
{
...
}
Ejecuta otra vez el método Execute() y verás un nuevo método de prueba en la clase de prueba unitaria iris.tripleSlash.tst.ObjectScript:
Class iris.tripleSlash.tst.ObjectScript Extends %UnitTest.TestCase
{
Method TestGuessTheNumber()
{
Do $$$AssertStatusOK(##class(dc.sample.ObjectScript).GuessTheNumber(42))
Do $$$AssertStatusNotOK(##class(dc.sample.ObjectScript).GuessTheNumber(23))
}
}
En este momento, las siguientes afirmaciones están disponibles: $$$AssertStatusOK, $$$AssertStatusNotOK y $$$AssertEquals.
TripleSlash nos permite generar pruebas desde ejemplos de código que se encuentran en las descripciones de métodos. Te ayuda a matar dos pájaros de un tiro, mejorando tu documentación de clase y creando automatización de pruebas.
ReconocimientoUna vez más, me gustaría agradecer todo el apoyo de la Comunidad en todas las aplicaciones que creamos! Muchas gracias @Ricardo.Paiva Muito obrigado pelo excelente artigo @Henrique.GonçalvesDias
Artículo
David Reche · 9 jun, 2019
¡Hola Comunidad!Este artículo es una guía sencilla sobre cómo preguntar y cómo conseguir respuestas en la Comunidad. Ya que el objetivo obvio cuando publicamos una pregunta en la Comunidad es obtener una respuesta, veamos cómo conseguir buenas preguntas que tengan visibilidad para encontrar fácilmente.Cuando se publica una pregunta es necesario completar tres campos: Título, Cuerpo y Grupo, además de las etiquetas.1. El TítuloUn buen título debería contener una descripción breve de tu problema - no debería ser más largo de 80 o 90 caracteres.Pero tampoco debería ser demasiado breve - un título de una única palabra tampoco es una buena idea. Ejemplos de buenas preguntas:Consultar una lista de propiedades con SQLCómo ignorar la cabecera en un fichero CSV cuando se usa Record MapperEquivalente a $CASE o $SELECT en SQL2. El CuerpoEl cuerpo debería contener una descripción de tu problema de manera textual y opcionalmente con un ejemplo de código como ObjectScript, SQL, JS u otros lenguajes. Utiliza bloques de código para resaltar el código ObjectScript.Proporcionar la versión del producto utilizado siempre es útil (puedes obtenerla con $zversion desde el Terminal).Y siempre que sea posible, pregunta solo una cosa en el cuerpo. Si tienes más de una pregunta y puedes separarlas, es mejor crear dos entradas diferentes. De esta forma, será más fácil para otros miembros encontrar respuestas a tus preguntas.3. El GrupoEl grupo es una etiqueta obligatoria que ayuda a categorizar tus preguntas, asociándolas a uno de los Productos de InterSystems (IRIS, Caché, Ensemble, HealthShare), Tecnologías (DeepSee, iKnow) or Servicios (Online Learning, WRC).4. EtiquetasUtiliza etiquetas para facilitar a otros miembros expertos (que están suscritos a diferentes etiquetas) a encontrar tu pregunta. Puedes elegir diferentes etiquetas relacionadas con desarrollo, pruebas, gestión de cambios, despliegues y entornos.Si preguntas correctamente y el texto es claro, se suelen obtener respuestas en poco tiempo. Puedes observar qué preguntas tienen respuestas en el contador de respuestas con fondo verde, a la derecha de cada pregunta. Y acuérdate de marcar una respuesta como aceptada (indicando que la pregunta ha sido resuelta) en caso de que la respuesta resuelva tu duda y se ajuste a lo que necesitabas.Por supuesto, esta no es la lista definitiva de recomendaciones sobre cómo hacer buenas preguntas. Así que puedes añadir tus comentarios e ideas sobre el post, para complementar lo que creas oportuno. ¡Gracias!
Artículo
Nancy Martínez · 20 abr, 2021
Al trabajar desde casa durante estos "días de coronavirus", me faltan recursos.
- no tengo ninguna máquina Linux disponible
- espacio en disco limitado
Además, Docker Desktop (en Windows10) bloqueó de alguna manera los scripts de [Durable %SYS](https://docs.intersystems.com/iris20192/csp/docbook/Doc.View.cls?KEY=ADOCK_iris_durable) como se describe [**aquí.**](https://community.intersystems.com/post/docker-vs-durability)
Investigando el caso, descubrí que se almacenaban muchos más datos de los que realmente necesitaba.
Así que diseñé mi durabilidad personalizada.
De forma similar a lo que hice tiempo atrás para los contenedores de Caché.
Utilizando las características de [**iris-main **](https://docs.intersystems.com/iris20192/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_iscmain)agrego un script de pre-procesamiento para iniciar mi contenedor con
Después de que termina, guardo lo que creo necesitar para el próximo inicio.
Y eso es bastante menos.
De acuerdo: Puede que se me escapen algunas cosas y finalmente es más lento en start/stop. Muy bien. ¡Pero está en mis manos!
Los scripts para ejecutar y también los datos guardados están almacenados en el directorio externo que necesito para la licencia.
Y esos scripts son bastante sencillos:
# post.copycp -uf /usr/irissys/iris.cpf /external/iris.cpfcp -uf /usr/irissys/mgr/IRIS.DAT /external/mgr/IRIS.DATcp -uf /usr/irissys/mgr/messages.log /external/console.log
y
# pre.copycp -f /external/iris.cpf /usr/irissys/iris.cpfcp -f /external/mgr/IRIS.DAT /usr/irissys/mgr/IRIS.DATrm -f /usr/irissys/mgr/messages.log
Como no hay nada que configurar en la primera ejecución, omito pre.copy como la primera ejecución hecha.
Por lo demás, mi comando de ejecución en Docker tiene el siguiente aspecto:
docker run --name iris1 --init -it -p 52773:52773 -p 51773:51773 --volume c:/external:/external --rm intersystems/iris:2020.2.0.198.0 --key /external/key/iris.key -e /external/post.copy -b /external/pre.copy
Si tiempo después descubro que necesito guardar/recuperar algo más (por ejemplo, para CSP, ... ) es fácil añadirlo.
La clave del éxito fue dejar la base de datos IRISSYS en la ubicación que se incluye en el contenedor. Su tamaño de ~92 MB (en mi caso) no es relevante.
Anuncio
Esther Sanchez · 8 jun, 2022
¡Hola desarrolladores!
Hemos hecho algunos cambios en los sitios web de las Comunidades de Desarrolladores de InterSystems:
🆕 Mejor seguimiento de eventos en marcha
🆕 Programación de publicaciones
🆕 Formato del código mejorado
🆕 Creación de tablas mejorada
🆕 Mejor seguimiento de respuestas
🆕 Nuevo diseño en la parte inferior de las publicaciones
Vamos a explicar en detalle cada uno de ellos.
Eventos EN MARCHA AHORA
Para que la búsqueda de eventos sea aún más sencilla, hemos añadido una nueva sección "EN MARCHA AHORA" en la esquina superior derecha de la página.
Si hacéis clic ahí, iréis a la página del evento.
Programación de publicaciones
Lo habíais pedido... ¡y ya está aquí! Ahora se pueden programar las publicaciones, para que se publiquen en un momento determinado.
Para programar una publicación, solo hay que hacer clic en la flecha hacia abajo al lado del botón "Publicar" y elegir "Programar publicación".
Aparecerá un calendario en el que se puede elegir el día y hora en el que se quiere publicar.
Después, hay que hacer clic en el botón "Programar publicación" y la publicación se publicará en el día y hora elegida. ¡Así de fácil!
Formato del código
Para compartir el código con otras personas, hemos añadido un editor integrado cuando se introduce código.
En él, se puede elegir el lenguaje de programación y el tamaño de la tabulación.
Además, el resaltado de sintaxis se produce automáticamente cuando escribes el texto. Y el lenguaje de programación se muestra en la esquina superior izquierda.
Como resultado, en tu publicación verás el código bonito y ordenado, en el lenguaje de programación elegido.
Creación de tablas
Para simplificar el formato de las tablas, hemos añadido una función para crear tablas rápidamente, solo eligiendo el número de celdas que se necesiten.
Al hacer clic en el botón "More" (Más) se abre una ventana para configurar las propiedades de la tabla.
Respuestas y suscripciones
Para ver toda la información sobre las respuestas de una publicación, hemos añadido el número de respuestas y también el icono de suscribirse al debate, para recibir notificaciones de las nuevas respuestas.
Nuevo diseño en la parte inferior de las publicaciones
Hemos reorganizado y cambiado los iconos en la parte inferior de las publicaciones.
¡Esperamos que os resulten útiles estos cambios!
Podéis solicitar mejoras o reportar errores en el GitHub de la Comunidad. O en los comentarios de esta publicación, claro.
¡Muchas gracias!
Pregunta
LUIS VENDITTELLI · 1 sep, 2022
Hola!!!! Tengo un tablepane con una propiedad "where Clause = CAMPO > ?"
Cuando desde un ClassMethod quiero actualizar el query de ese tablePane usando "zen(tablePane).parameters[0].value = valor"me devuelve el siguiente error:
Cannot set properties of undefined (setting 'value')
Alguna idea de qué estoy haciendo mal?
Muchas gracias!!!!! Es difícil saber qué está pasando sin ver el código y probarlo. Antes de verlo, diría que el tableare no tiene definido parámetros en la descripción de la tabla. Ejemplo:
<tablePane id="table"
sql="SELECT ID,Name FROM MyApp.Employees
WHERE Name %STARTSWITH ? ORDER BY Name"
>
<parameter value="Z"/>
</tablePane>
Podrías intentar simplificar el código al máximo en una clase copiada de la original, y, cuando no puedas reducir más el código, nos lo mandes y podamos echarle un vistazo.
Hola Luis,
Parece que estás en una versión muy antigua (2012) y utilizando una tecnología (ZEN) también antigua. ZEN se soporta aún por compatibilidad, pero échale un vistazo al InterSystems IRIS Migration Guide en el [WRC > Software Distribution > Docs](https://wrc.intersystems.com/wrc/coDistDocs.csp).
Sobre tu cuestión, el error probablemente viene dado de que intentas establecer el `value` de algo nulo. No consigues referencia el parámetro. Prueba con el ejemplo que te ha pasado Mario, o incluso mejor añade un `id` al parámetro para que puedas referenciarlo directamente a través del identificador.
```
```
Mira por ejemplo en [Query Parameters](https://docs.intersystems.com/ens201815/csp/docbook/DocBook.UI.Page.cls?KEY=GZCP_tables#GZCP_table_parameters)
Este es el tablepane:
<tablePane id="tpDIGI" showQuery="true" valign="top" maxRows="300" tableName="NombreTabla" showRowSelector="false" width="490px" showFilters="true" showValueInTooltip="true" autoExecute="true" fixedHeaders="true" whereClause="CAMPO = ?" onselectrow="" useSnapshot="true" initialExecute="true" rowSelect="false"> <column ... /> </tablePane>
Más abajo, tengo un ClassMethod que ejecuta:
zen('tpDIGI').parameters[0].value='1111'
Ahi me da el error antes mencionado. Alguna idea??? Ya encontré el problema!!! Faltaba el tag <parameter />
Lo agregué y se solucionó!!!
Saludos a toda la comunidad.
Artículo
Ricardo Paiva · 12 nov, 2021
Este curso de formación está dirigido a todas las personas interesadas en conocer el *framework* de Interoperabilidad de IRIS. Utilizaremos Docker y VSCode.
GitHub: https://github.com/grongierisc/formation-template
# 1. **Formación en Ensemble/Interoperabilidad**
El objetivo de esta formación es aprender el *framework* de interoperabilidad de InterSystems, y en particular el uso de:
* Producciones
* Mensajes
* *Business Operations*
* Adaptadores
* *Business Processes*
* *Business Services*
* Operaciones y servicios REST
**ÍNDICE:**
- [1. **Formación de Ensemble/Interoperabilidad**](#1-ensemble--interoperability-formation)
- [2. *Framework*](#2-framework)
- [3. Adaptación del *framework*](#3-adapting-the-framework)
- [4. Requisitos previos](#4-prerequisites)
- [5. Configuración](#5-setting-up)
- [5.1. Contenedores de Docker](#51-docker-containers)
- [5.2. Portal de Administración](#52-management-portal)
- [5.3. Guardar el progreso](#53-saving-progress)
- [6. Producciones](#6-productions)
- [7. Operaciones](#7-operations)
- [7.1. Creación de nuestra clase de almacenamiento](#71-creating-our-storage-class)
- [7.2. Creación de nuestra clase para mensajes](#72-creating-our-message-class)
- [7.3. Creación de nuestra operación](#73-creating-our-operation)
- [7.4. Cómo añadir la operación a la producción](#74-adding-the-operation-to-the-production)
- [7.5. Pruebas](#75-testing)
- [8. *Business processes*](#8-business-processes)
- [8.1. *Business processes* simples](#81-simple-bp)
- [8.1.1. Creación del proceso](#811-creating-the-process)
- [8.1.2. Modificación del contexto de un *business process*](#812-modifying-the-context-of-a-bp)
- [8.2. Cómo hacer que el *business process* lea líneas CSV](#82-bp-reading-csv-lines)
- [8.2.1. Creación de un mapa de registro](#821-creating-a-record-map)
- [8.2.2. Creación de una transformación de datos](#822-creating-a-data-transformation)
- [8.2.3. Añadir la transformación de datos al *business process*](#823-adding-the-data-transformation-to-the-business-process)
- [8.2.4. Configuración de la producción](#824-configuring-production)
- [8.2.5. Pruebas](#825-testing)
- [9. Obtener acceso a una base de datos externa usando JDBC](#9-getting-access-to-an-extern-database-using-jdbc)
- [9.1. Creación de nuestra nueva operación](#91-creating-our-new-operation)
- [9.2. Configuración de la producción](#92-configuring-the-production)
- [9.3. Pruebas](#93-testing)
- [9.4. Ejercicio](#94-exercise)
- [9.5. Solución](#95-solution)
- [10. Servicio REST](#10-rest-service)
- [10.1. Creación del servicio](#101-creating-the-service)
- [10.2. Añadir nuestro *business service* (BS)](#102-adding-our-bs)
- [10.3. Pruebas](#103-testing)
- [Conclusión](#conclusion)
# 2. *Framework*
Este es el *framework* de IRIS.
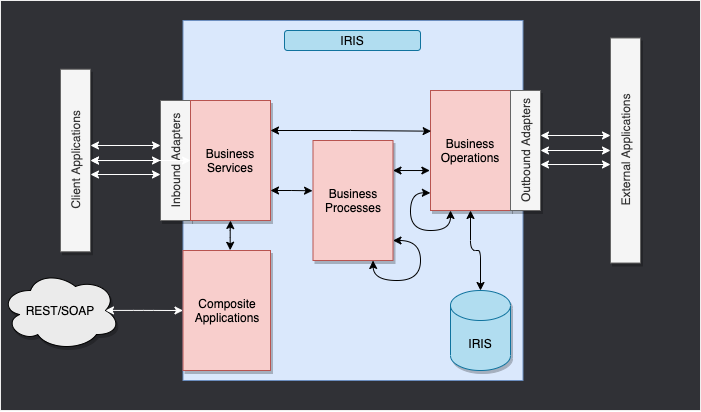
Los componentes que están en el interior de IRIS representan una producción. Los adaptadores de entrada y de salida nos permiten utilizar diferentes tipos de formato como entrada y salida para nuestra base de datos. Las aplicaciones compuestas nos darán acceso a la producción a través de aplicaciones externas como los servicios REST.
Las flechas que están entre todos estos componentes son **mensajes**. Estos pueden ser solicitudes o respuestas.
# 3. Adaptación del *framework*
En nuestro caso, leeremos las líneas desde un archivo CSV y las guardaremos en la base de datos IRIS.
Entonces, añadiremos una operación que nos permitirá guardar los objetos en una base de datos externa, utilizando JDBC. Esta base de datos se ubicará en un contenedor de Docker, utilizando postgre.
Por último, veremos cómo utilizar aplicaciones compuestas para insertar nuevos objetos en nuestra base de datos, o para consultar esta base de datos (en nuestro caso, a través de un servicio REST).
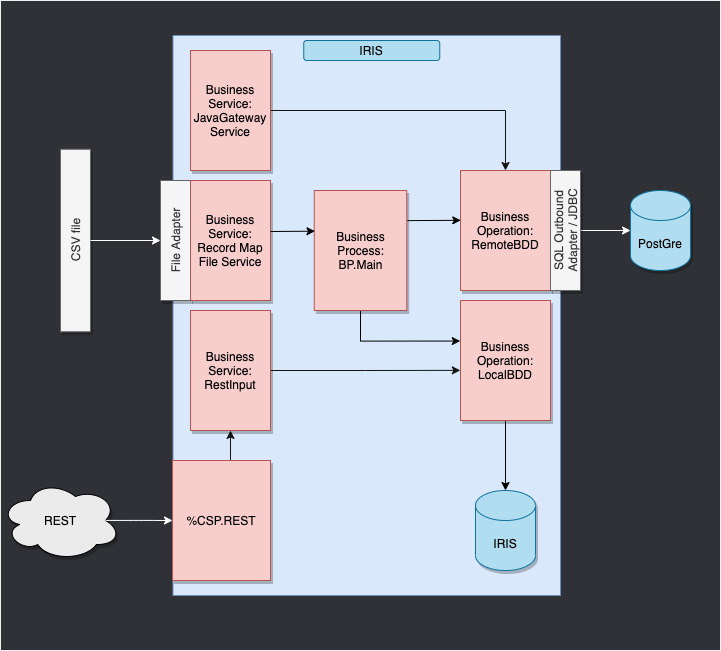
El *framework* adaptado a nuestro propósito nos ofrece:
# 4. Requisitos previos
Para esta formación, necesitarás:
* VSCode: https://code.visualstudio.com/
* El conjunto de *addons* de InterSystems para VSCode: https://intersystems-community.github.io/vscode-objectscript/installation/
* Docker: https://docs.docker.com/get-docker/
* El *addon* de Docker para VSCode
# 5. Configuración
## 5.1. Contenedores de Docker
Para tener acceso a las imágenes de InterSystems, hay que ir a esta URL: http://container.intersystems.com. Después de iniciar sesión con nuestras credenciales de InterSystems, obtendremos nuestra contraseña para conectarnos al registro. En el *addon* de Docker para VSCode, que se encuentra en la pestaña de imágenes, hacemos clic en Conectar Registro, introducimos la misma URL que antes (http://container.intersystems.com) como registro genérico y se nos pedirá que demos nuestras credenciales. El inicio de sesión es el habitual pero la contraseña es la que obtuvimos del sitio web.
A partir de ahí, deberíamos ser capaces de crear y componer nuestros contenedores (con los archivos `docker-compose.yml` y `Dockerfile` que se nos dieron).
## 5.2. Portal de Administración
Abriremos un Portal de Administración. Esto nos dará acceso a una página web desde la que podremos crear nuestra producción. El portal debe estar ubicado en la URL: http://localhost:52775/csp/sys/UtilHome.csp?$NAMESPACE=IRISAPP. Necesitarás las siguientes credenciales:
> LOGIN: SuperUser
>
> PASSWORD: SYS
## 5.3. Guardar el progreso
Una parte de las cosas que haremos se guardarán localmente, pero todos los procesos y producciones se guardan en el contenedor de Docker. Con el fin de conservar todo nuestro progreso, necesitamos exportar todas las clases que se crean desde el Portal de Administración con ayuda del *addon* `ObjectScript` de InterSystems:
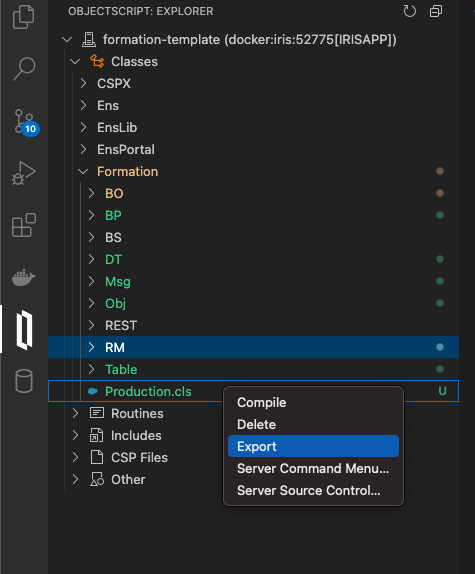
Tendremos que guardar de esta forma nuestra producción, mapa de registros, *business processes* y transformaciones de datos. Después de hacerlo, cuando cerremos nuestro contenedor Docker y hagamos la compilación nuevamente, aún tendremos todo nuestro progreso guardado de forma local (por supuesto, hay que hacer esto después de cada cambio que hagamos a través del portal). Para que sea accesible a IRIS de nuevo, tenemos que compilar los archivos exportados (cuando los guardemos, los *addons* de InterSystems se encargarán del resto).
# 6. Producciones
Ahora podemos crear nuestra primera producción. Para hacerlo, nos moveremos por los menús [Interoperability] y [Configure]:

Ahora hacemos clic en [New], seleccionamos el paquete [Formation] y elegimos un nombre para nuestra producción:
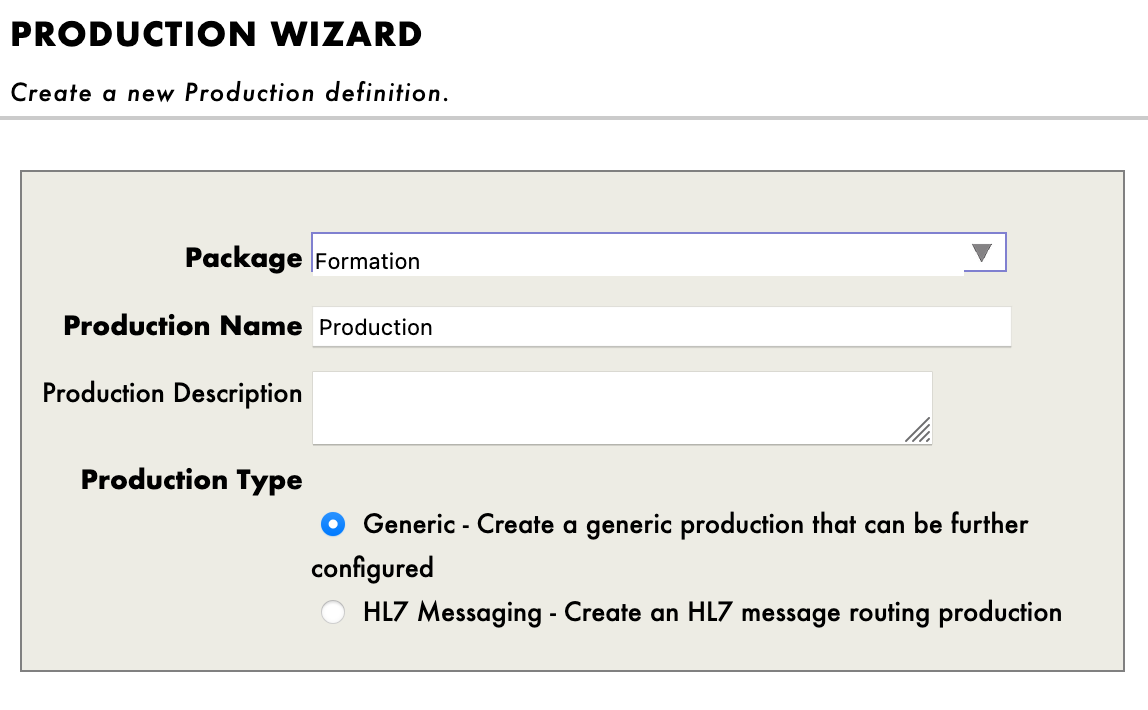
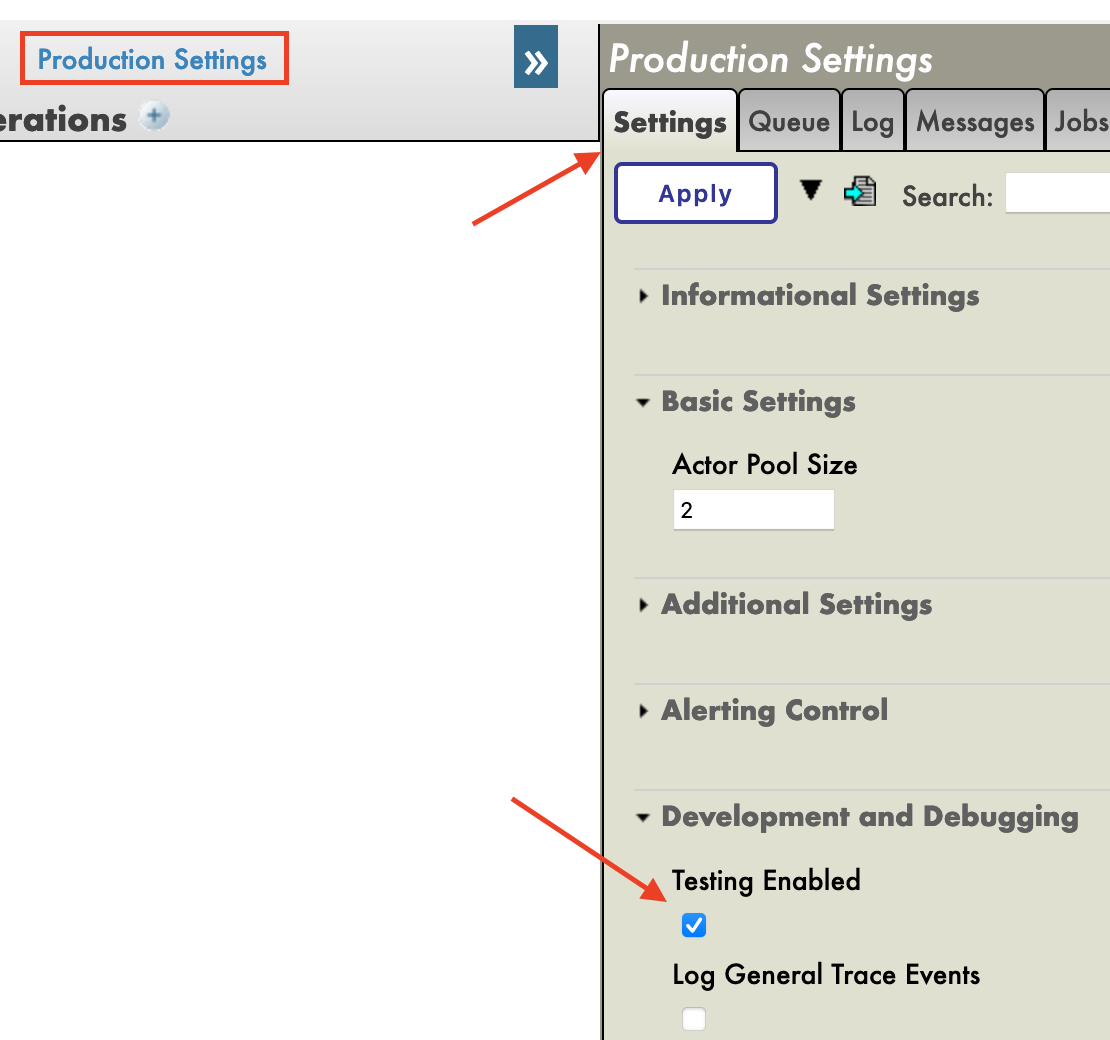
Inmediatamente después de crear nuestra producción, hay que hacer clic en la opción \[Production Settings], situada encima de la sección [Operations]. En el menú de la barra lateral derecha, tendremos que activar la opción [Testing Enabled] en la sección [Development and Debugging] de la pestaña [Settings\] (no te olvides de hacer clic en [Apply]).
En esta primera producción añadiremos ahora las *business operations*.
# 7. Operaciones
Una *business operation* (BO) es un tipo de operación específica que nos permitirá enviar solicitudes desde IRIS hacia una aplicación/sistema externo. También se puede utilizar para guardar lo que queramos directamente en IRIS.
Crearemos esas operaciones de forma local, es decir, en el archivo `Formation/BO/`. Cuando guardemos los archivos los compilaremos en IRIS.
En nuestra primera operación, guardaremos el contenido de un mensaje en la base de datos local.
Para hacerlo, primero necesitamos tener una forma de almacenar este mensaje.
## 7.1. Creación de nuestra clase de almacenamiento
En IRIS, las clases de almacenamiento extienden el tipo `%Persistent`. Se guardarán en la base de datos interna.
En nuestro archivo `Formation/Table/Formation.cls` tenemos lo siguiente:
```objectscript
Class Formation.Table.Formation Extends %Persistent
{
Property Name As %String;
Property Salle As %String;
}
```
Ten en cuenta que al guardar, de forma automática se añaden líneas adicionales al archivo. Son obligatorias y las añaden los *addons* de InterSystems.
## 7.2. Creación de nuestra clase para mensajes
Este mensaje contendrá un objeto `Formation`, situado en el archivo `Formation/Obj/Formation.cls`:
```objectscript
Class Formation.Obj.Formation Extends (%SerialObject, %XML.Adaptor)
{
Property Nom As %String;
Property Salle As %String;
}
```
La clase `Message` utilizará el objeto `Formation`, `src/Formation/Msg/FormationInsertRequest.cls`:
```objectscript
Class Formation.Msg.FormationInsertRequest Extends Ens.Request
{
Property Formation As Formation.Obj.Formation;
}
```
## 7.3. Creación de nuestra operación
Ahora que ya tenemos todos los elementos que necesitamos, podemos crear nuestra operación, en el archivo `Formation/BO/LocalBDD.cls`:
```objectscript
Class Formation.BO.LocalBDD Extends Ens.BusinessOperation
{
Parameter INVOCATION = "Queue";
Method InsertLocalBDD(pRequest As Formation.Msg.FormationInsertRequest, Output pResponse As Ens.StringResponse) As %Status
{
set tStatus = $$$OK
try{
set pResponse = ##class(Ens.Response).%New()
set tFormation = ##class(Formation.Table.Formation).%New()
set tFormation.Name = pRequest.Formation.Nom
set tFormation.Salle = pRequest.Formation.Salle
$$$ThrowOnError(tFormation.%Save())
}
catch exp
{
Set tStatus = exp.AsStatus()
}
Quit tStatus
}
XData MessageMap
{
InsertLocalBDD
}
}
```
El MessageMap nos proporciona el método que debemos lanzar, dependiendo del tipo de solicitud (el mensaje que se envió a la operación).
Como podemos ver, si la operación recibió un mensaje del tipo `Formation.Msg.FormationInsertRequest`, se llamará al método `InsertLocalBDD`. Este método guardará el mensaje en la base de datos local de IRIS.
## 7.4. Cómo añadir la operación a la producción
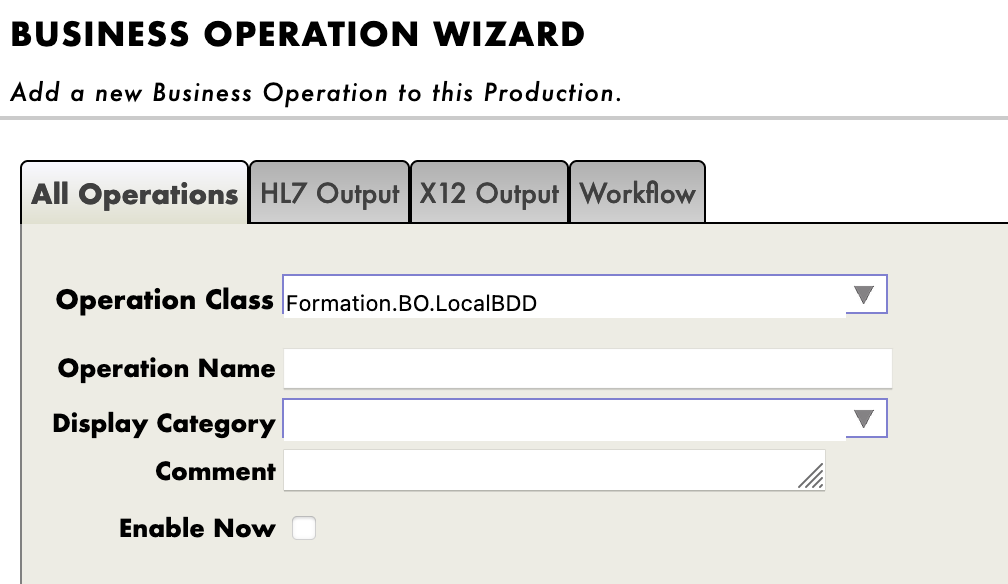
Ahora necesitamos añadir esta operación a la producción. Para hacerlo, utilizaremos el Portal de Administración. Al hacer clic en el signo [+] junto a [Operations], tendremos acceso al [Business Operation Wizard]. Allí, elegiremos la clase de la operación que acabamos de crear en el menú desplegable.
## 7.5. Pruebas
Si hacemos doble clic en la operación podremos activarla. Después de hacerlo, al seleccionar la operación e ir a las pestañas [Actions] que están en el menú de la barra lateral derecha, deberíamos poder probar la operación (si no ves la sección para crear la producción, puede que tengas que iniciar la producción si se encuentra detenida).
De este modo, enviaremos a la operación un mensaje del tipo que declaramos anteriormente. Si todo sale bien, los resultados deberían ser similares a los que se muestran a continuación:
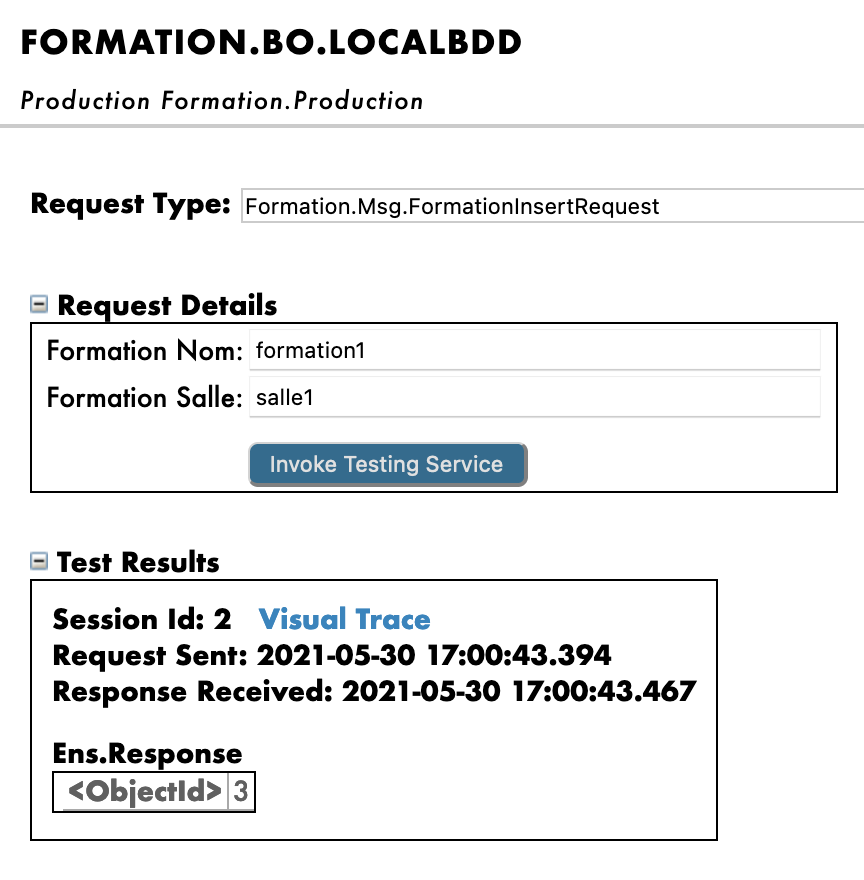
Mostrar el registro visual nos permitirá ver lo que ocurrió entre los procesos, servicios y operaciones. Aquí, podemos ver el mensaje que se envía a la operación por parte del proceso, y a la operación cuando envía de vuelta una respuesta (que en este caso solo es una cadena vacía).
# 8. *Business Processes*
Los *business processes* (BP) son la lógica empresarial de nuestra producción. Se utilizan para procesar las solicitudes o retransmitirlas a otros componentes de la producción.
Los *business processes* se crean dentro del Portal de Administración:
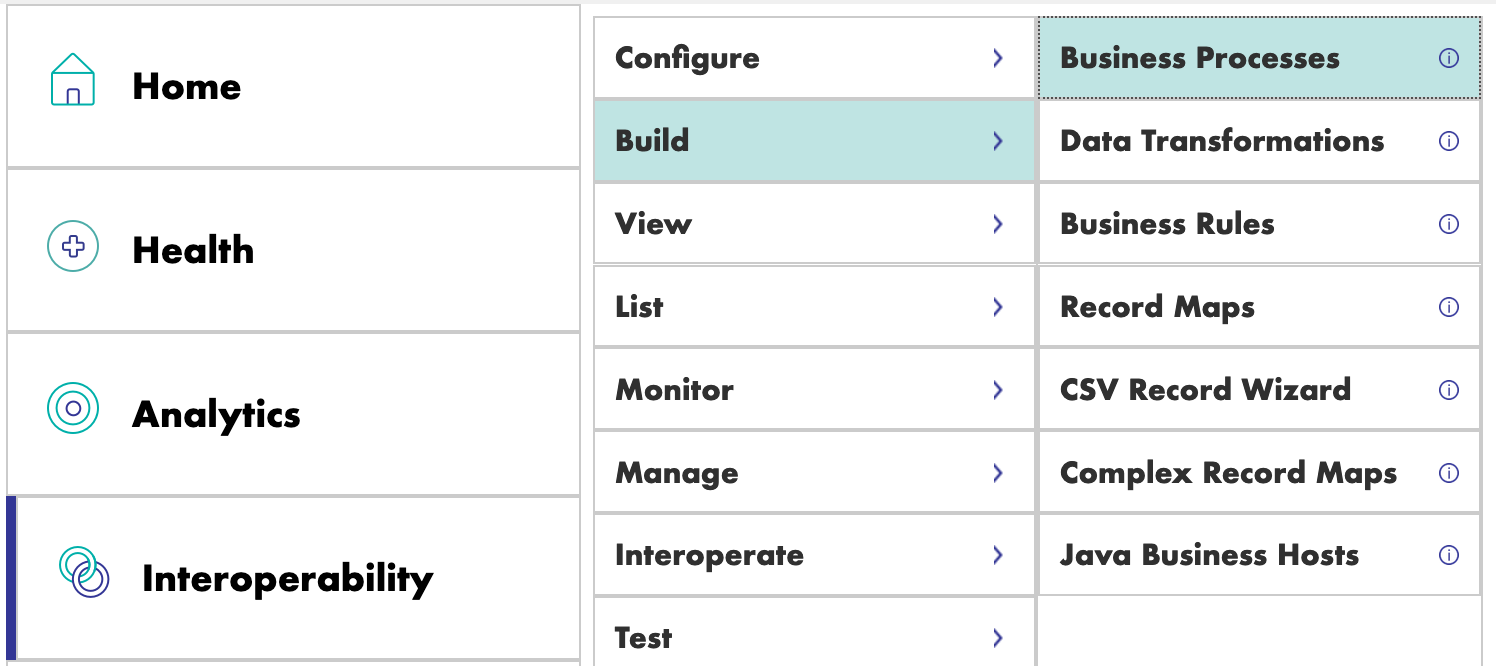
## 8.1. *Business processes* simples
### 8.1.1. Creación del proceso
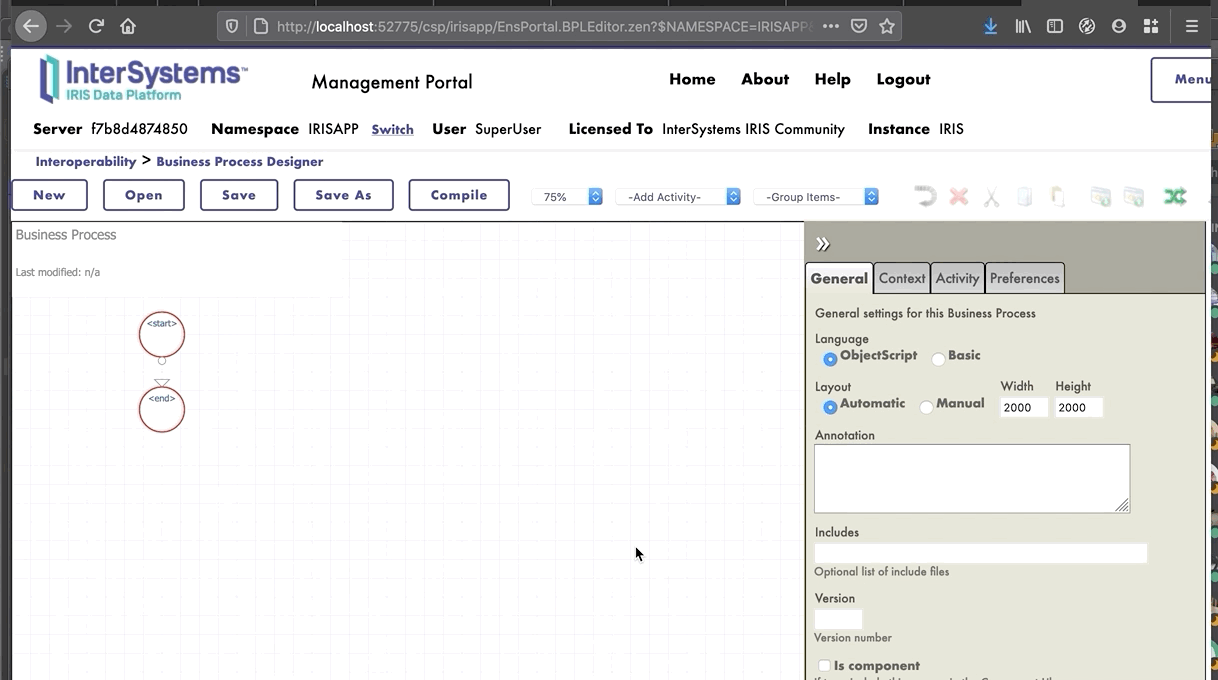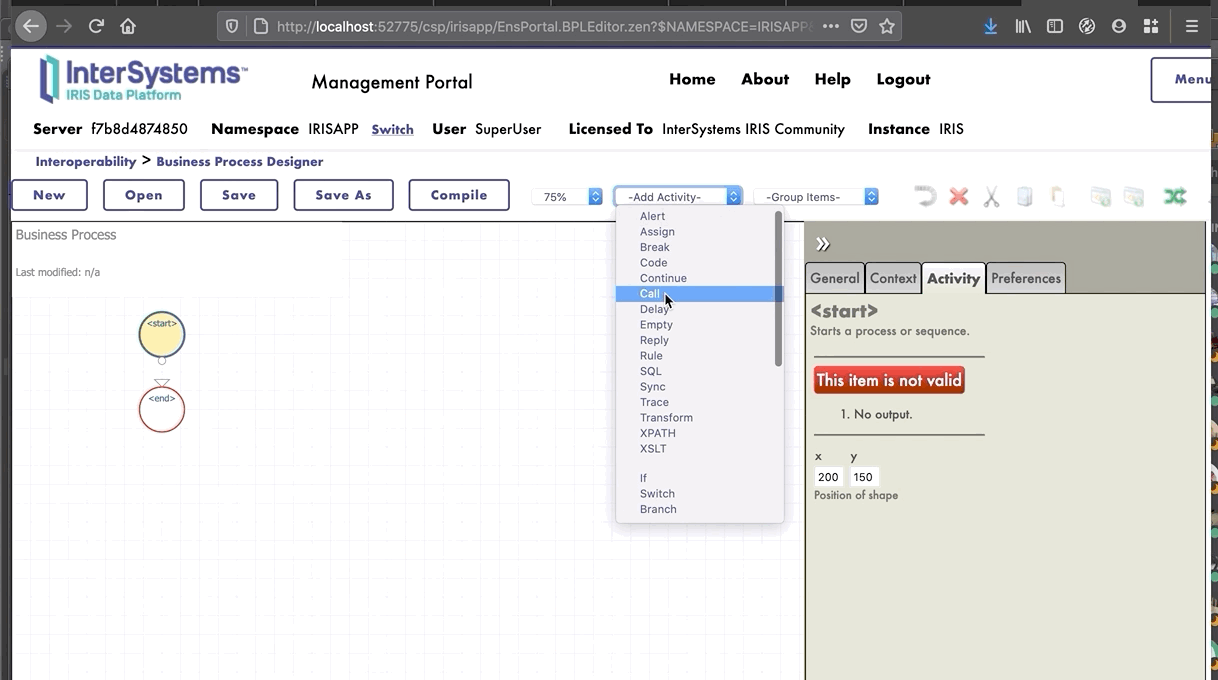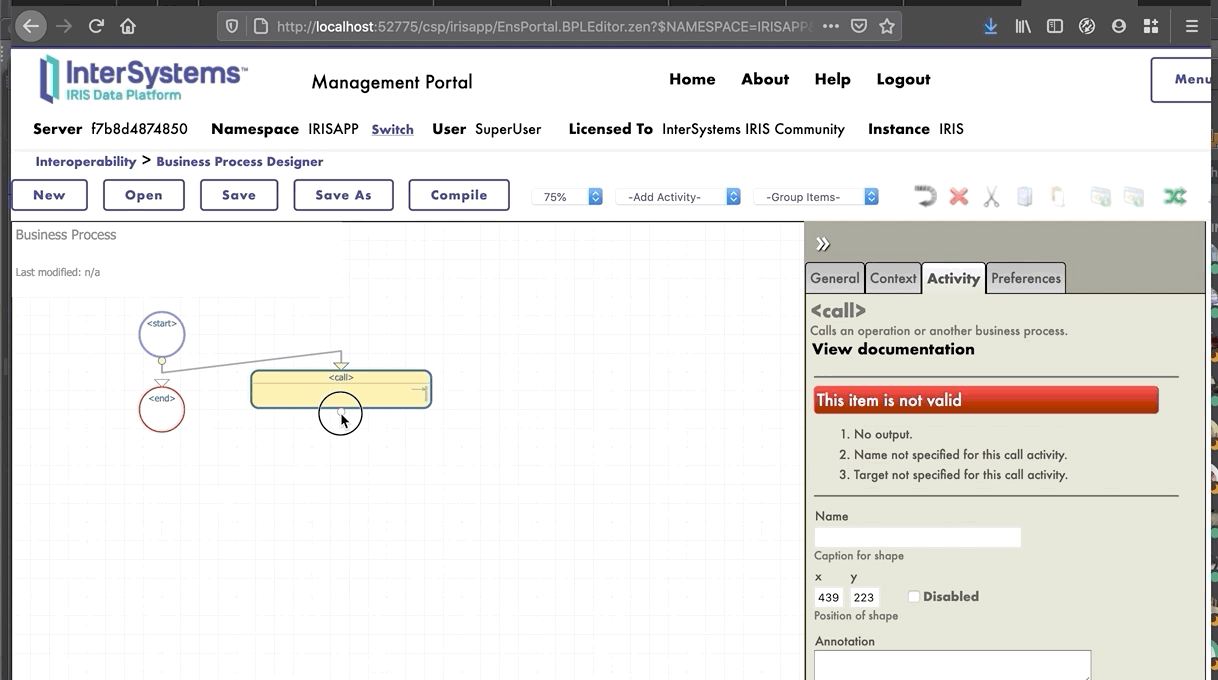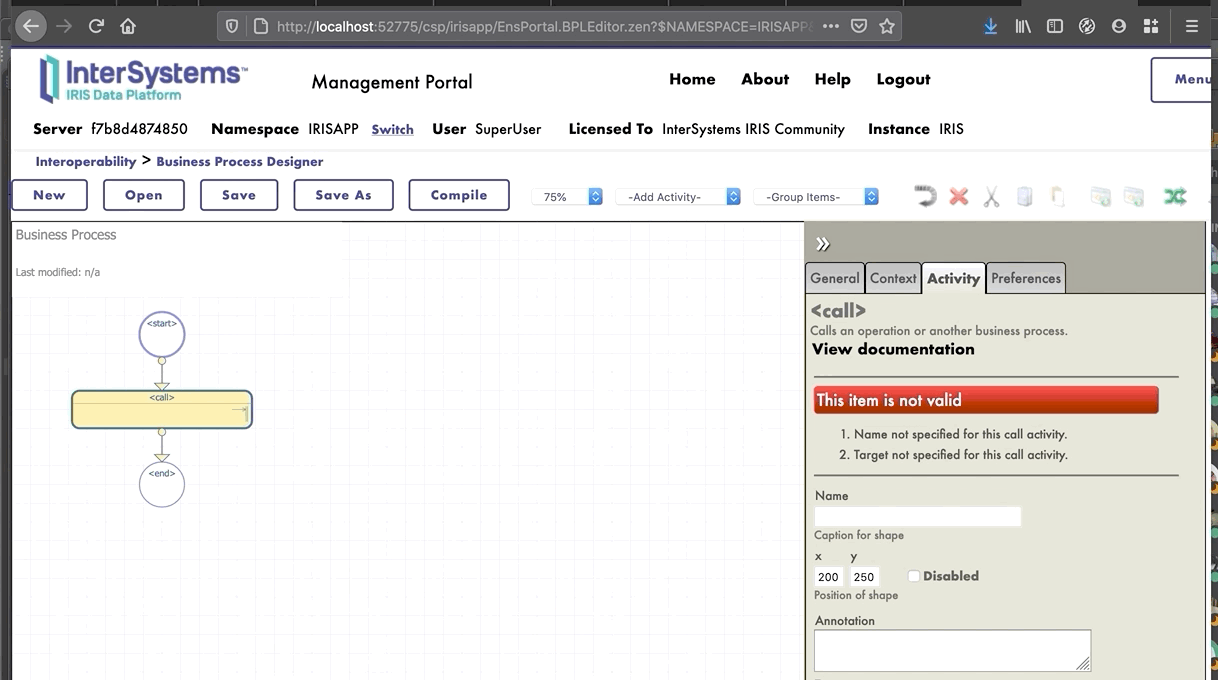
Ahora estamos en el Diseñador de *Business Process*. Vamos a crear un *business process* simple que llamará nuestra operación:
### 8.1.2. Modificación del contexto de un *business process*
Todos los *business processes* tiene un **contexto**. Se compone de una clase para la solicitud, la clase de la entrada, una clase para la respuesta y la clase de la salida. **Los *business processes* solo tienen una entrada y una salida**. También es posible agregar propiedades.
Como nuestro *business process* solo se utilizará para llamar a nuestra *business operation*, podemos poner la clase del mensaje que hemos creado como clase para la solicitud (no necesitamos una salida ya que solo queremos insertarlo en la base de datos).
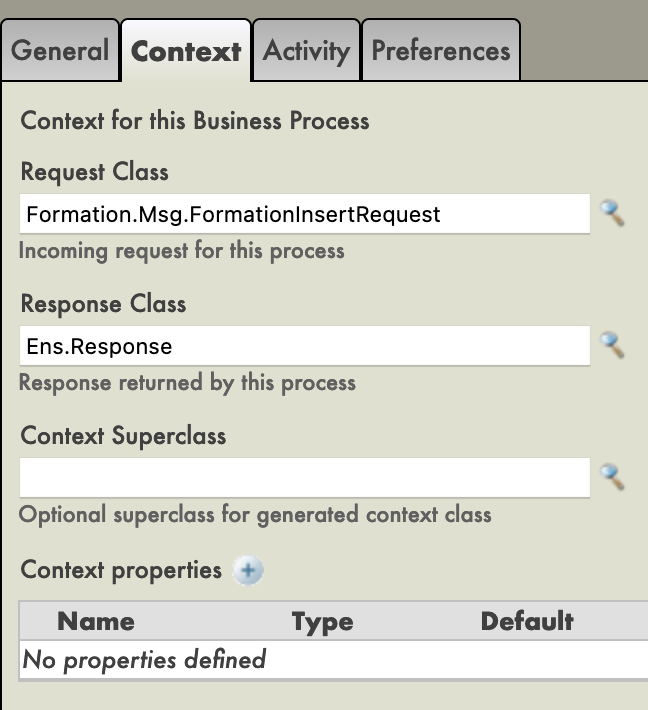
Ahora, elegiremos el objetivo de la función Call: nuestra *business operation*. Esa operación, al ser **llamada** tiene una propiedad **callrequest**. Necesitamos vincular esa propiedad callrequest con la solicitud del *business process* (ambos pertenecen a la clase Formation.Msg.FormationInsertRequest) y para ello, hacemos clic en la función Call y utilizaremos el creador de peticiones:
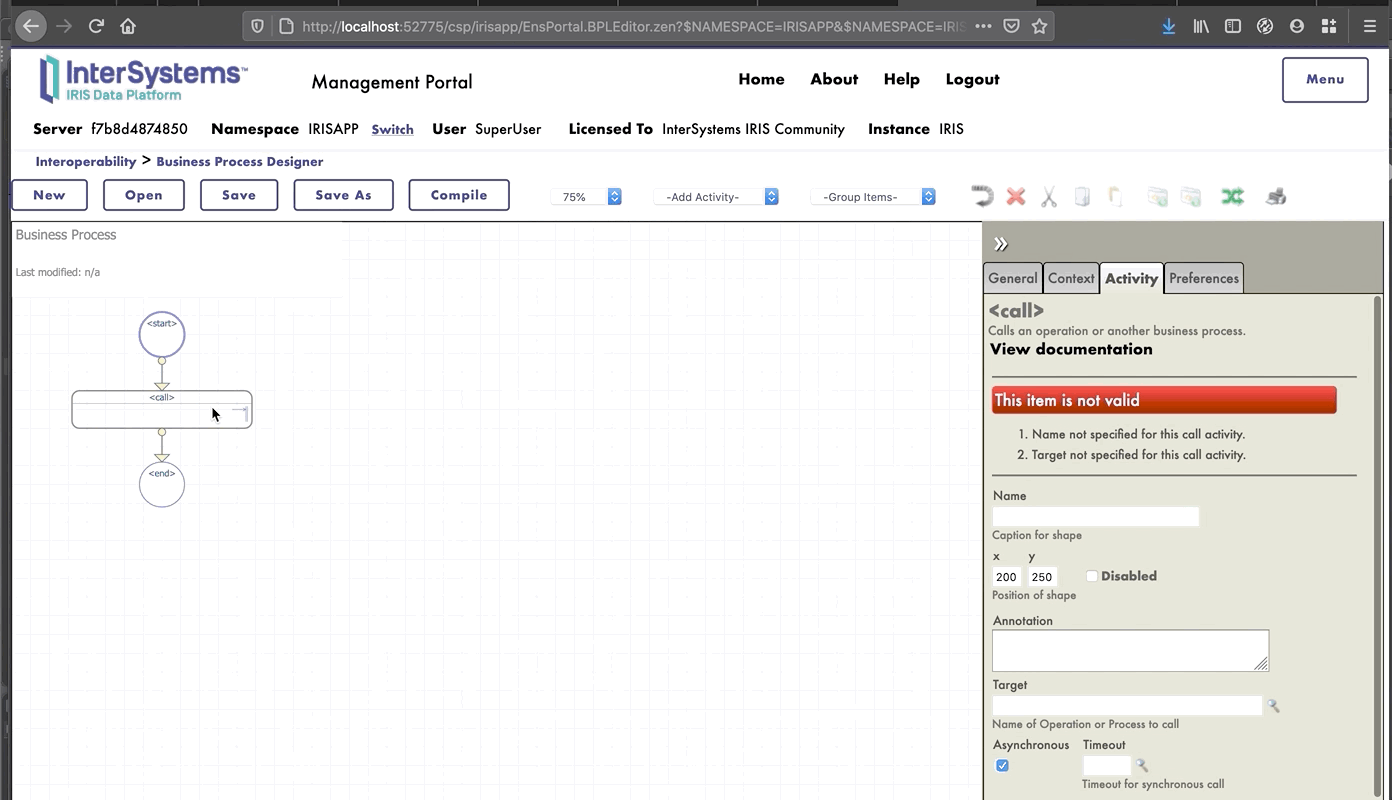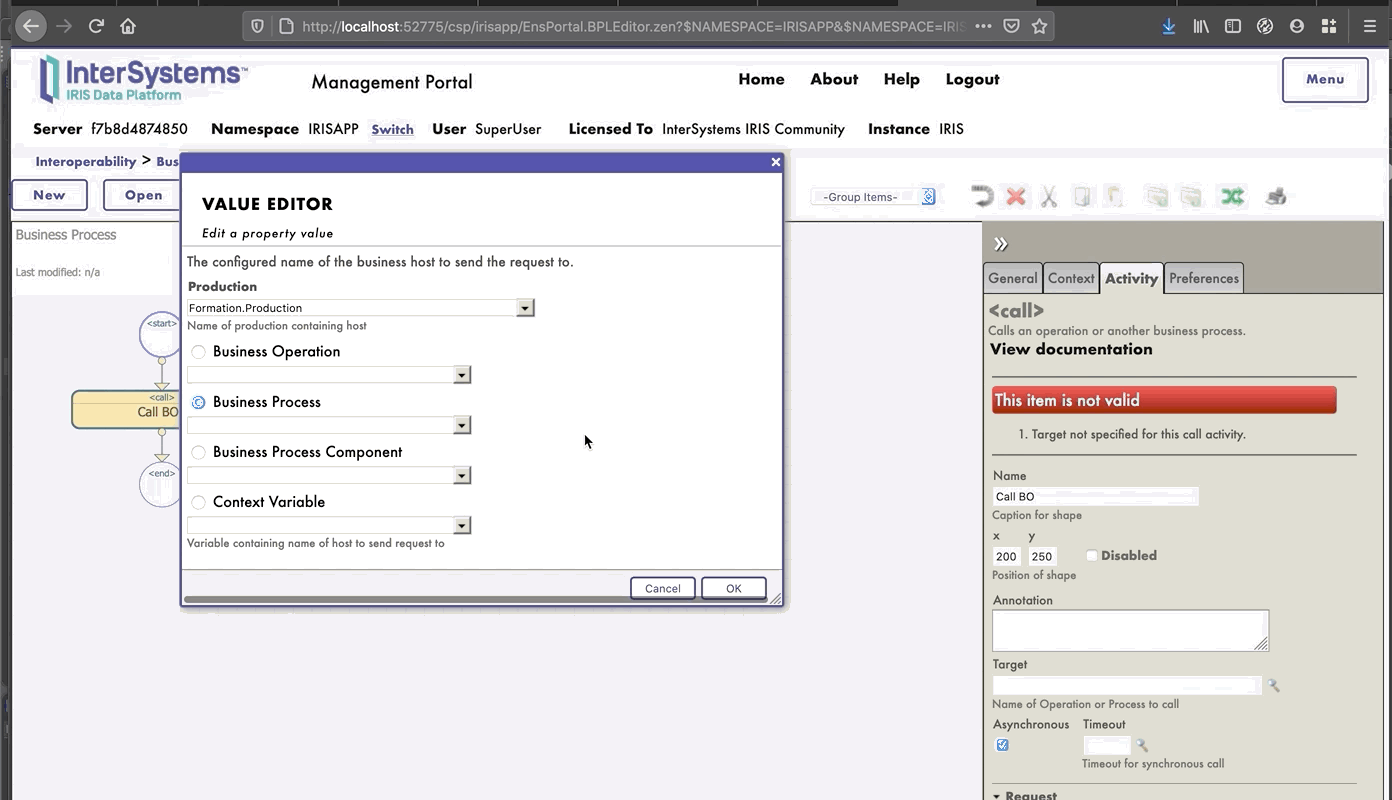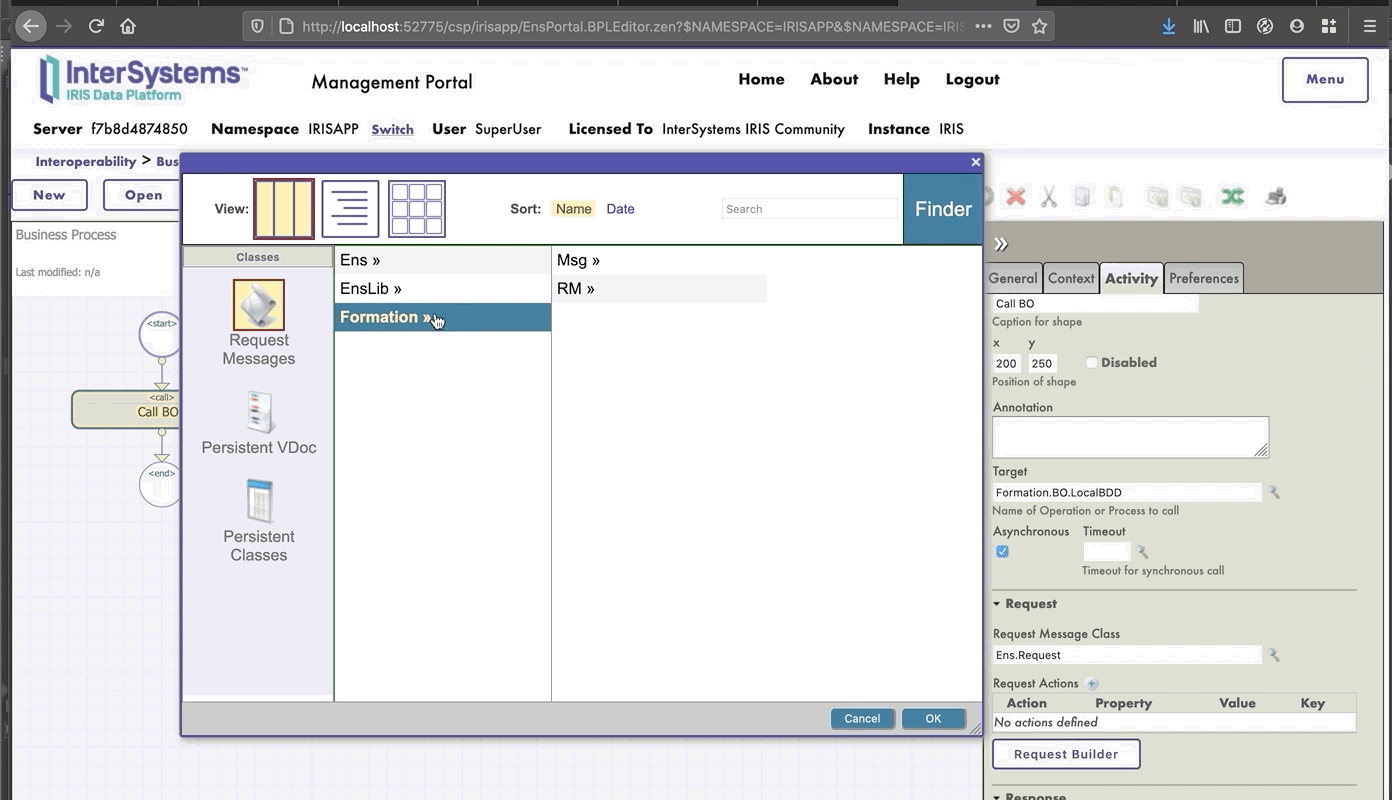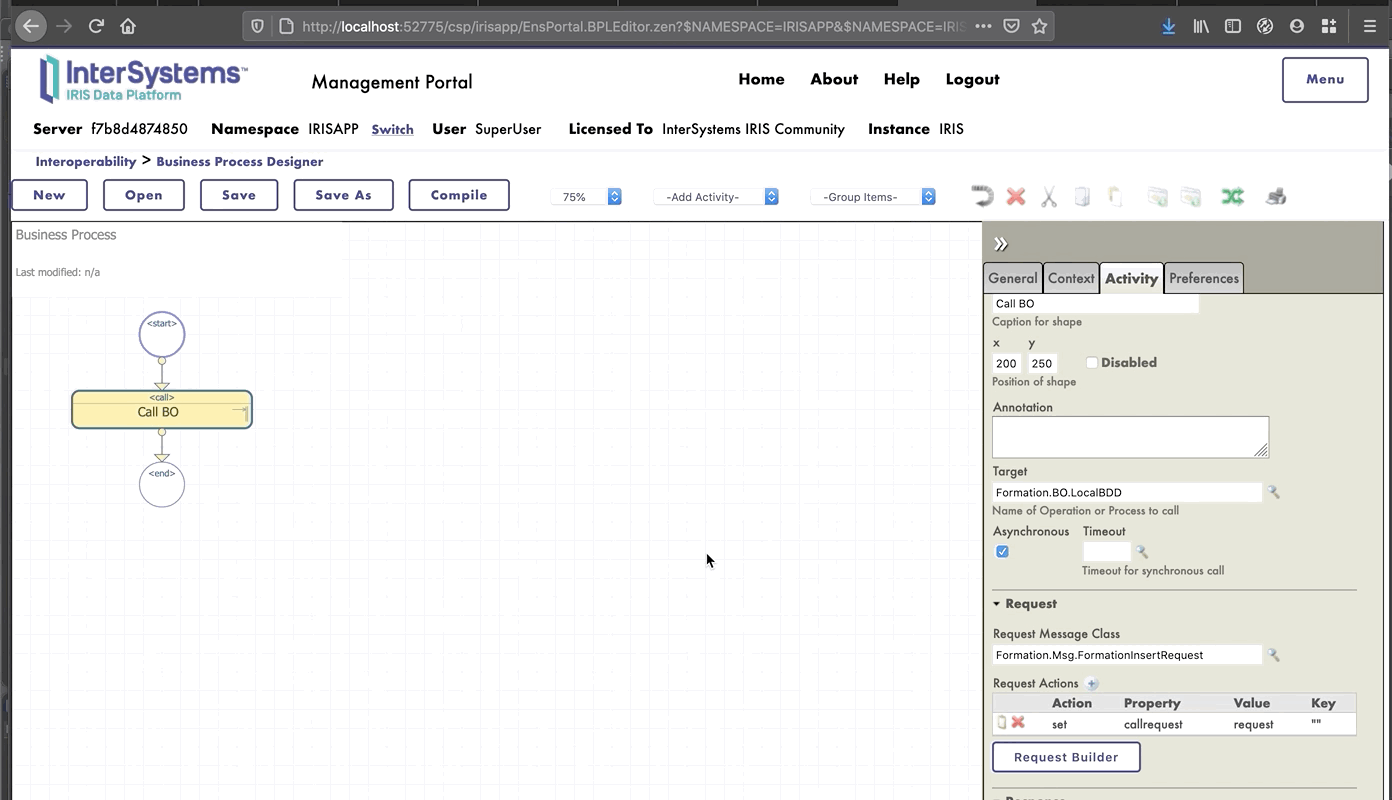
Ahora podemos guardar este *business process* (en el paquete 'Formation.BP' y, por ejemplo, con el nombre 'InsertLocalBDD' o 'Main'). Al igual que las operaciones, pueden crearse instancias de los procesos y se pueden probar mediante la Configuración de la producción, aunque para esto necesitan compilarse previamente (en la pantalla del *Business Process Designer*).
Por ahora, nuestro proceso solo pasa el mensaje a nuestra operación. Vamos a aumentar la complejidad para que el business process tome como entrada una línea de un archivo CSV.
## 8.2. Cómo hacer que el *business process* lea líneas CSV
### 8.2.1. Creación de un mapa de registro
Para leer un archivo y poner su contenido en otro archivo, necesitamos un Mapa de Registros (RM). En el menú [Interoperability > Build] del Portal de Administración hay un servicio para mapear los registros, especializado en archivos CSV:
Crearemos el servicio para elaborar mapas de esta manera:
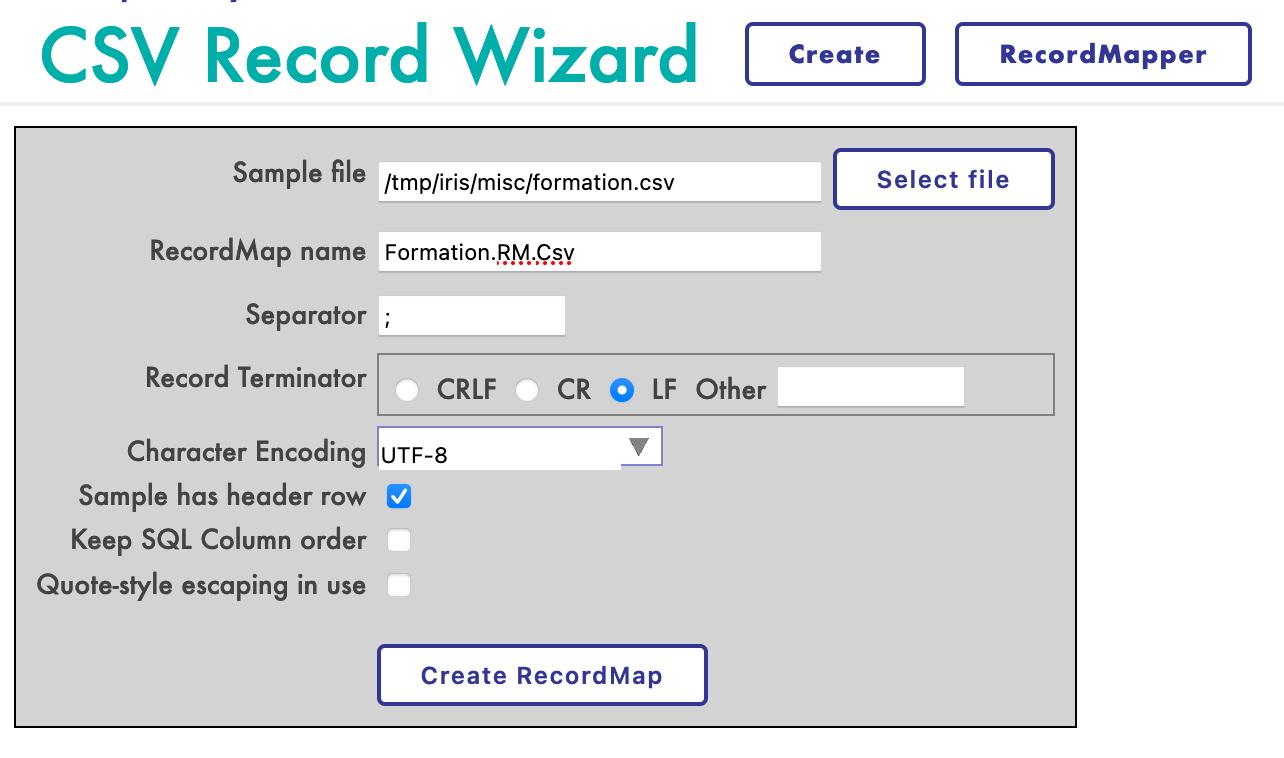
Ahora deberías tener el siguiente Mapa de Registros:
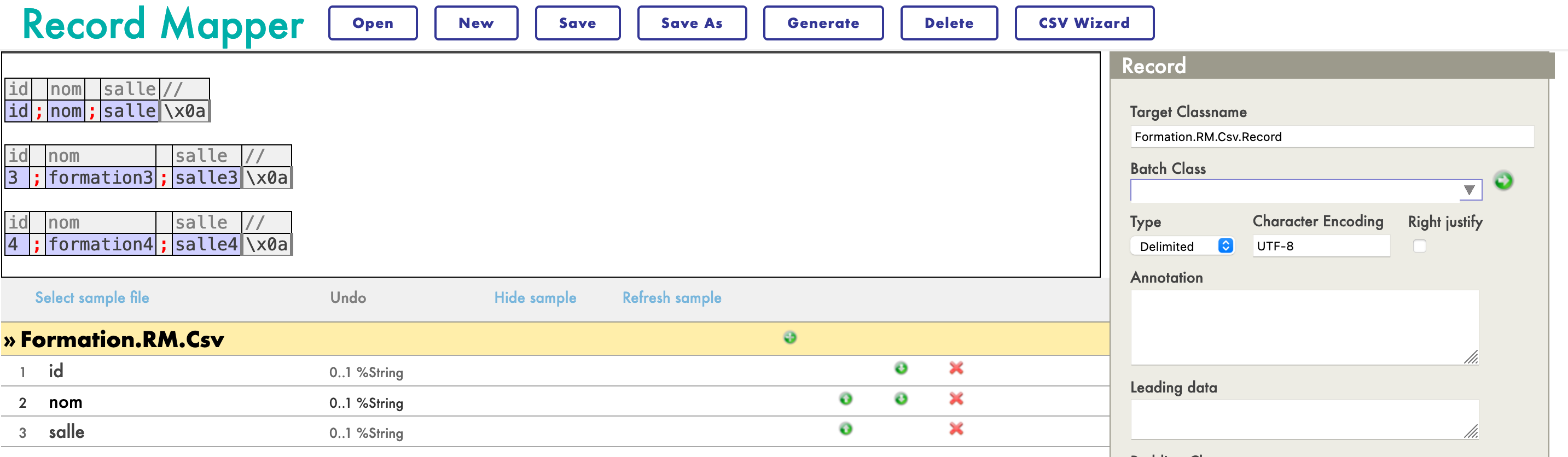
Ahora que el mapa está creado, debemos generarlo (con el botón *Generate*). También debemos efectuar una Transformación de datos desde el formato del Mapa de registros y un mensaje de inserción.
### 8.2.2. Creación de una transformación de datos
Encontraremos el Generador para la Transformación de datos (DT) en el menú [Interoperability > Builder]. A continuación, crearemos nuestra DT de esta forma (si no encuentras la clase Formation.RM.Csv.Record, tal vez no se generó el Mapa de Registros):
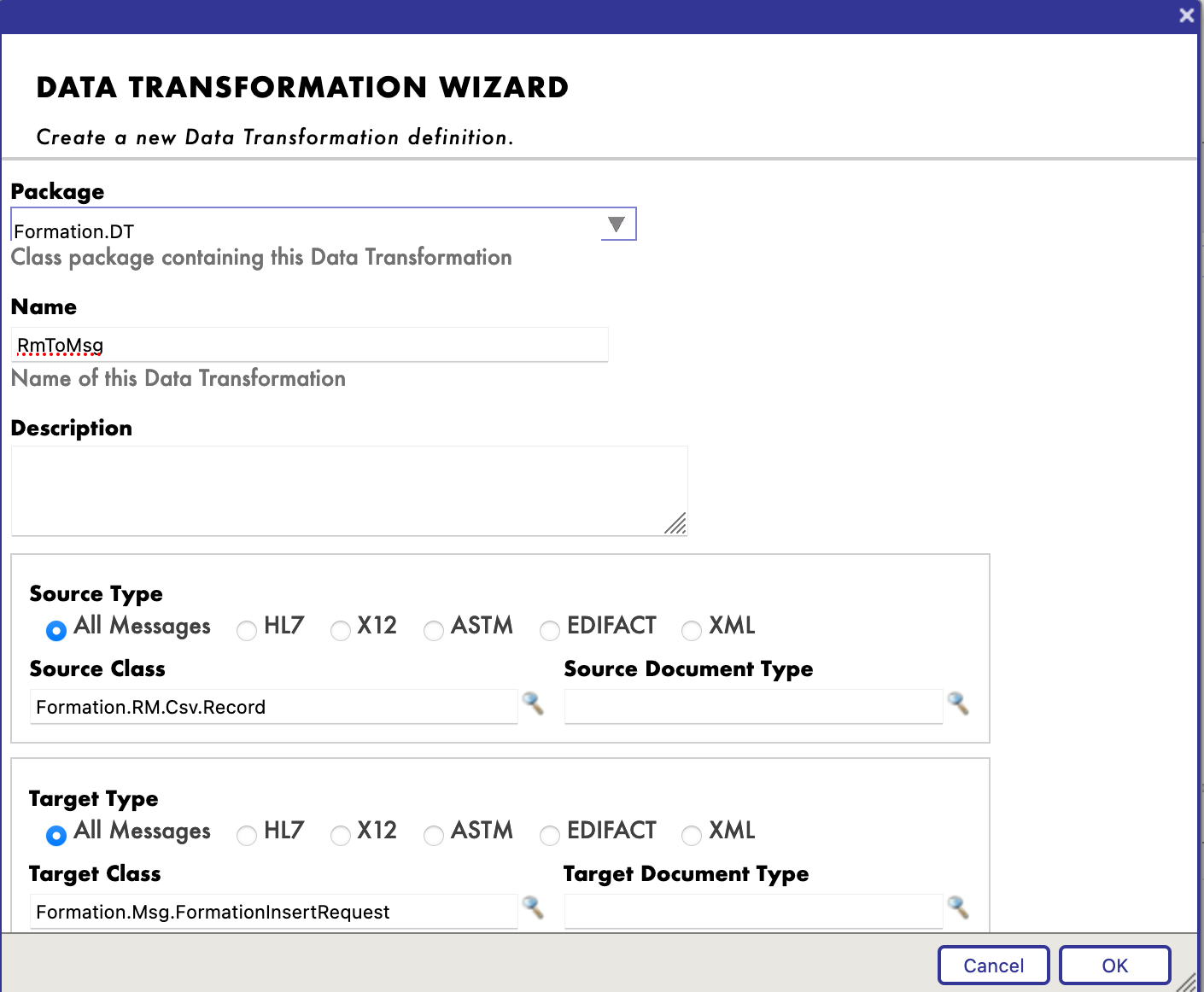
Ahora, podemos mapear los diferentes campos juntos:
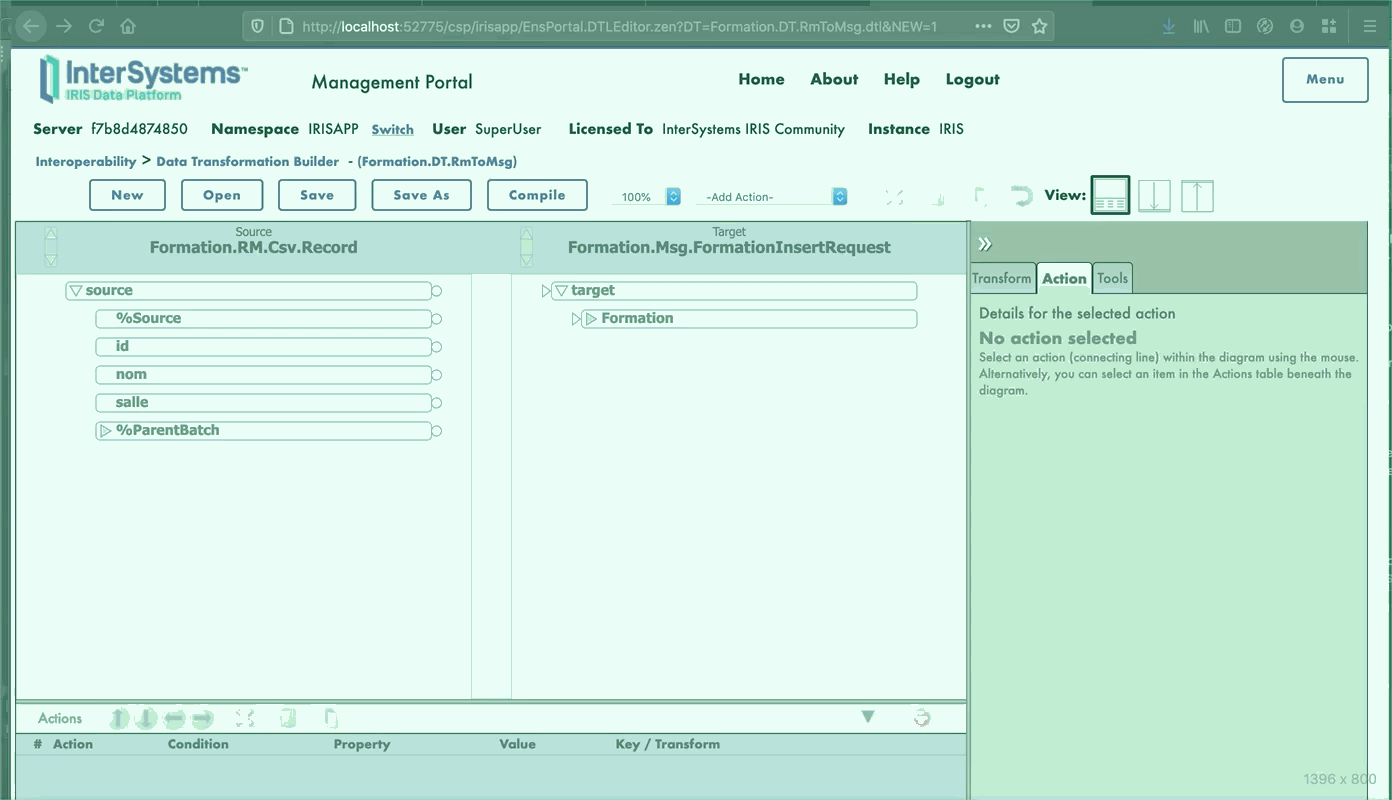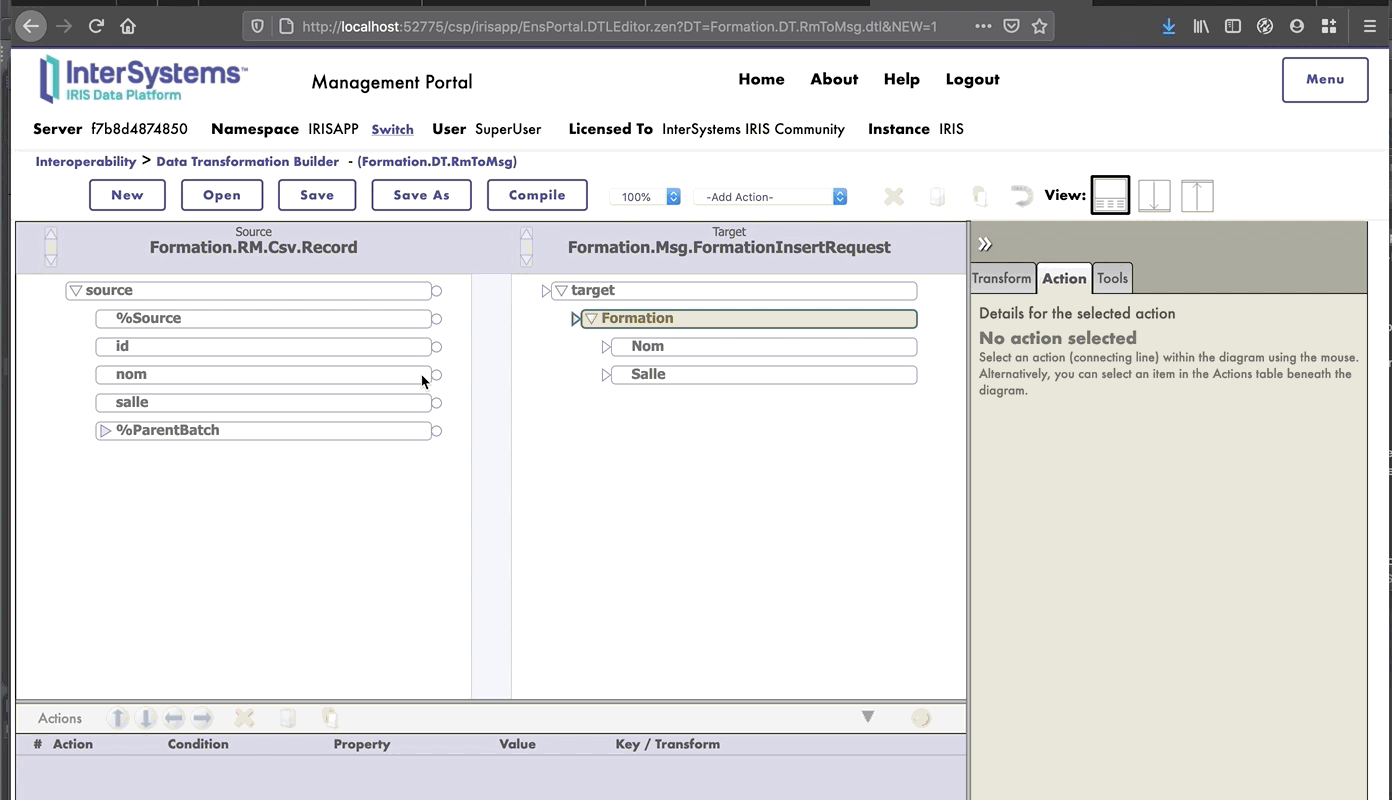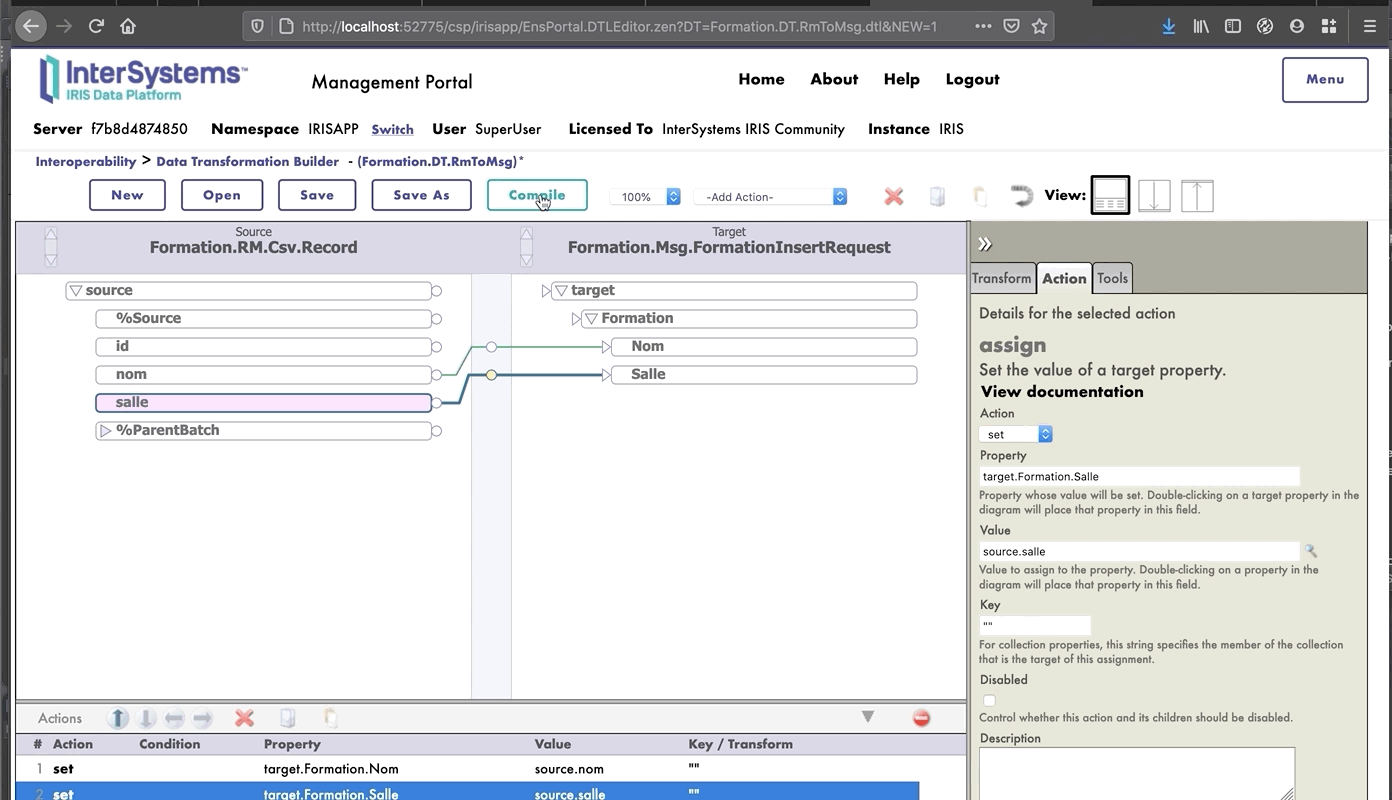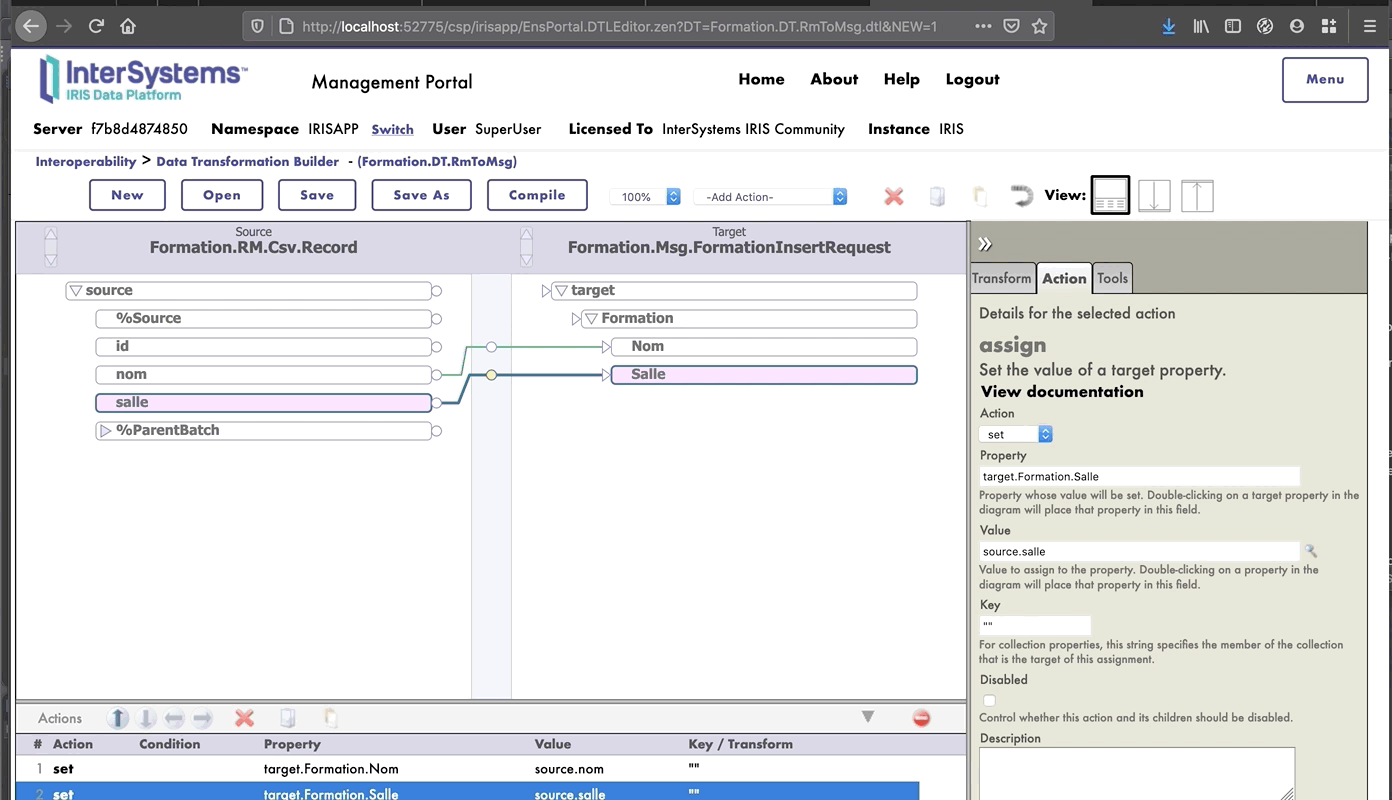
### 8.2.3. Añadir la transformación de datos al *business process*
Lo primero que debemos modificar es la clase de la solicitud del *business process*, ya que necesitamos tener una entrada en el Mapa de Registros que creamos.
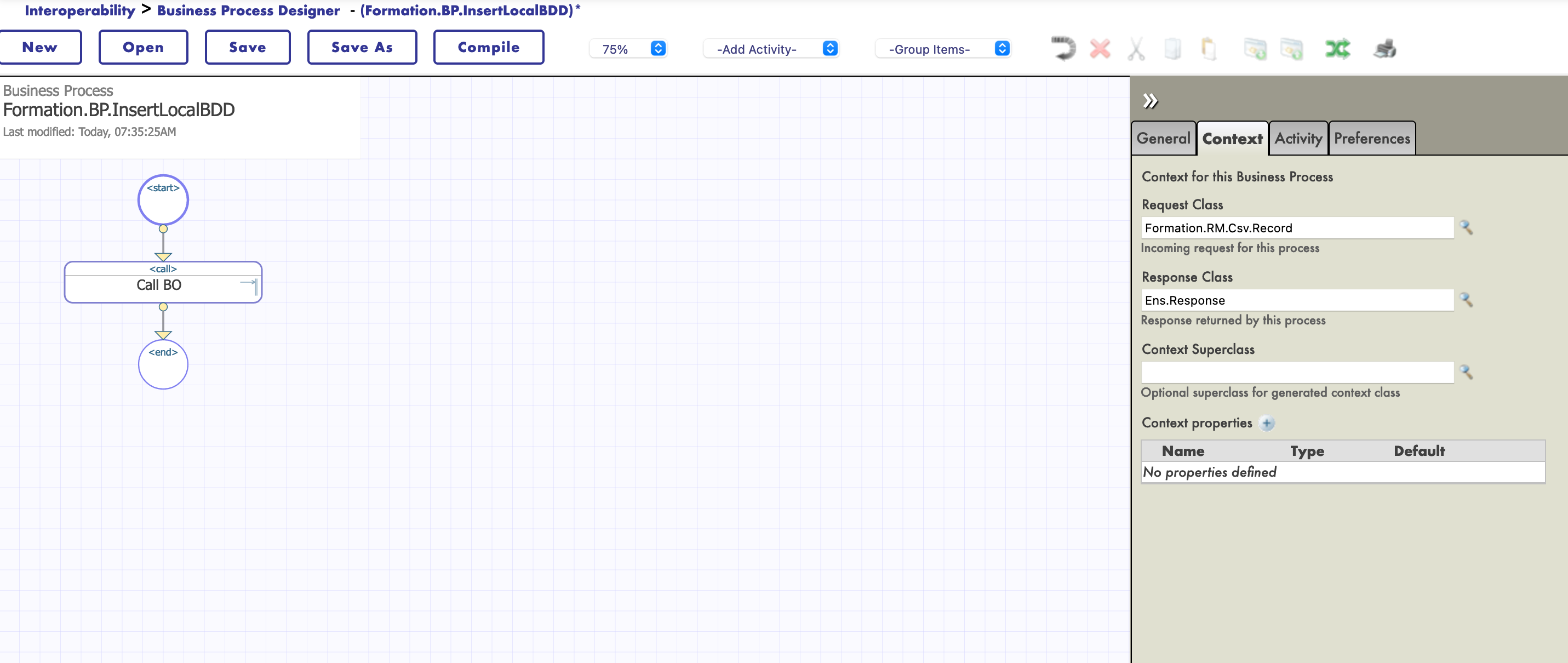
Entonces, podemos añadir nuestra transformación (el nombre del proceso no cambia nada, a partir de aquí elegimos llamarlo `Main`):
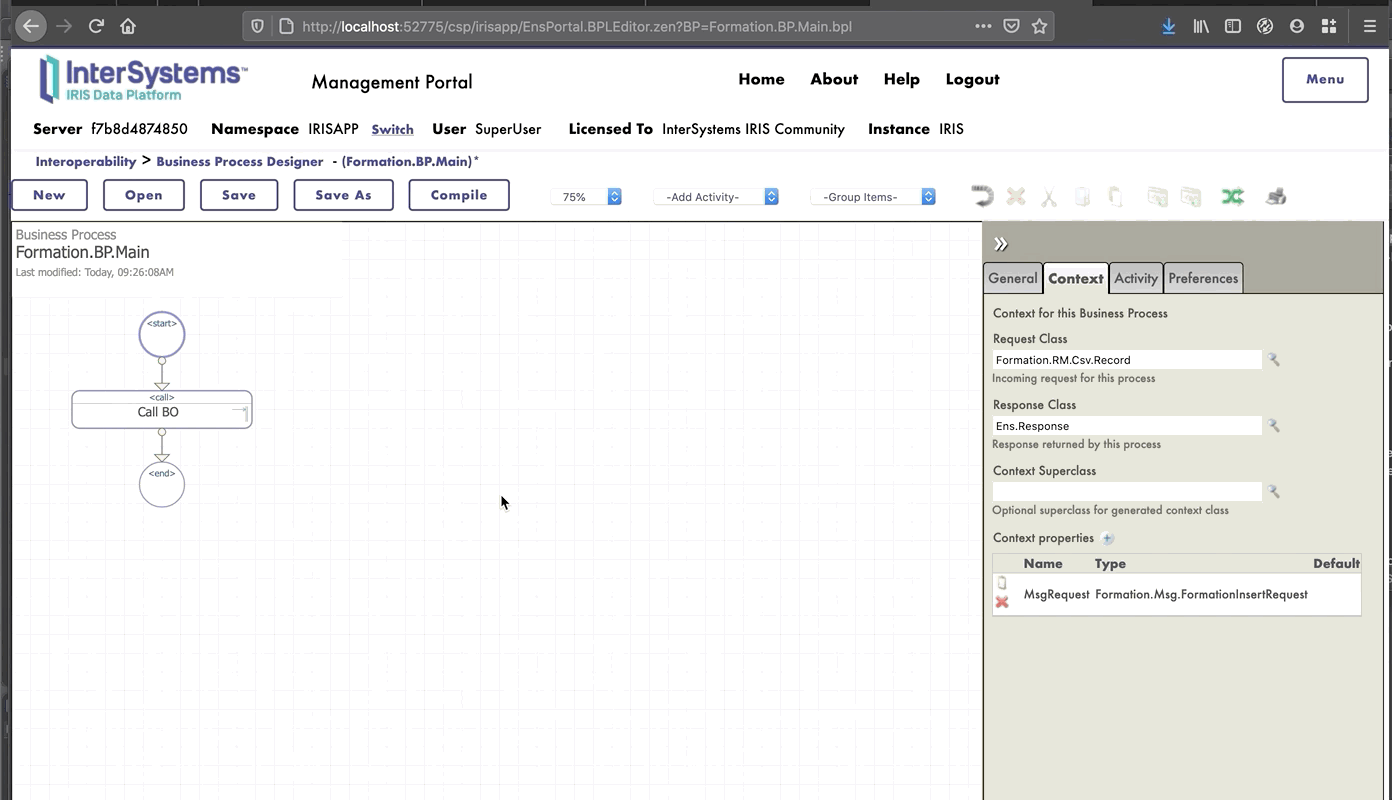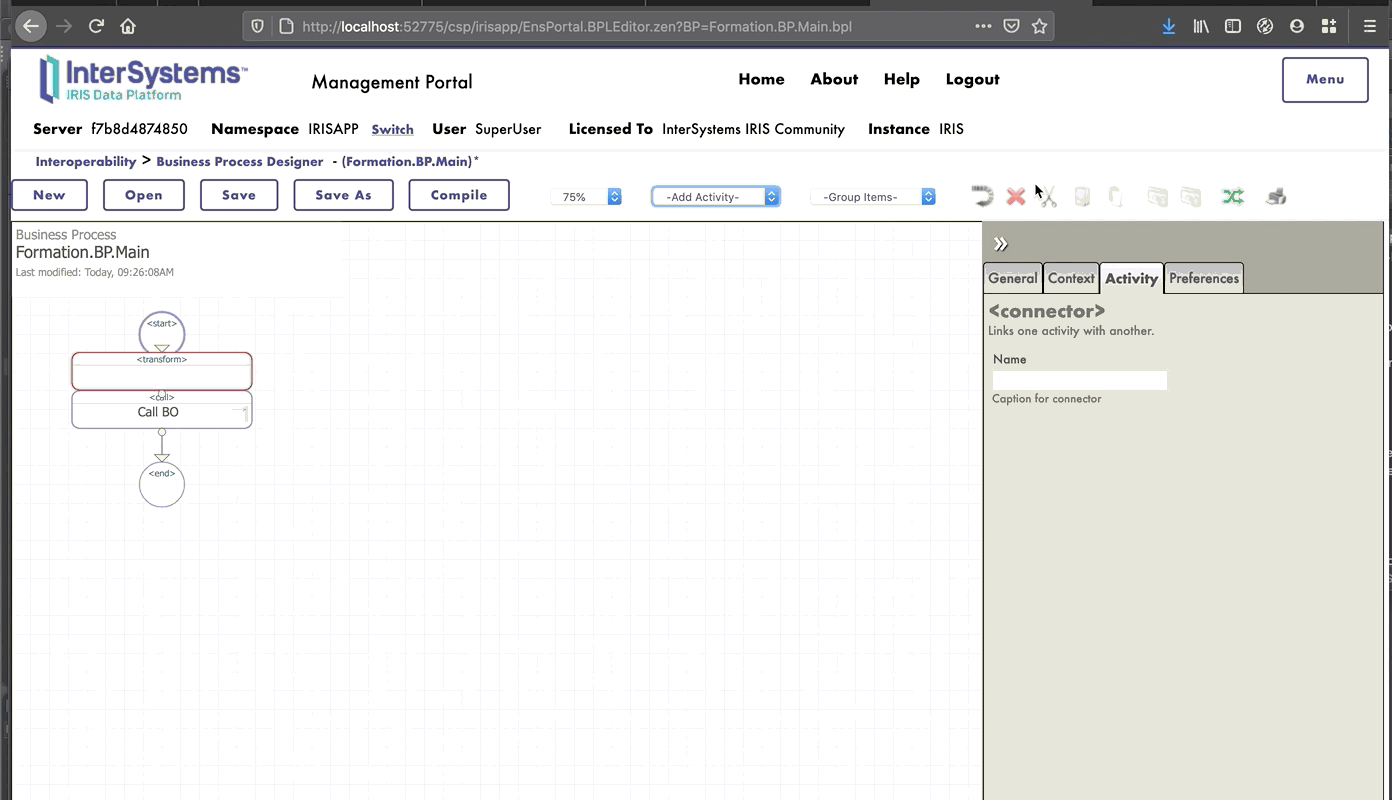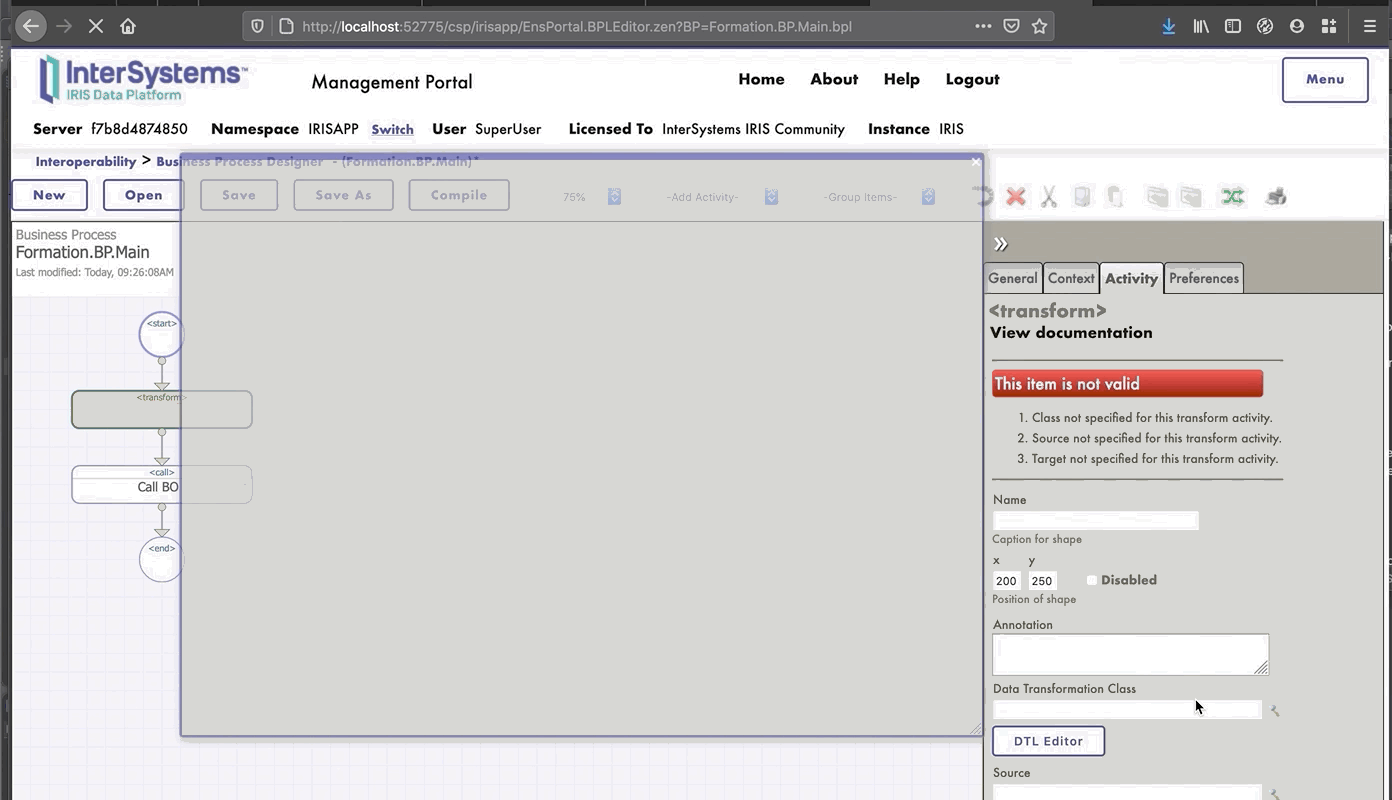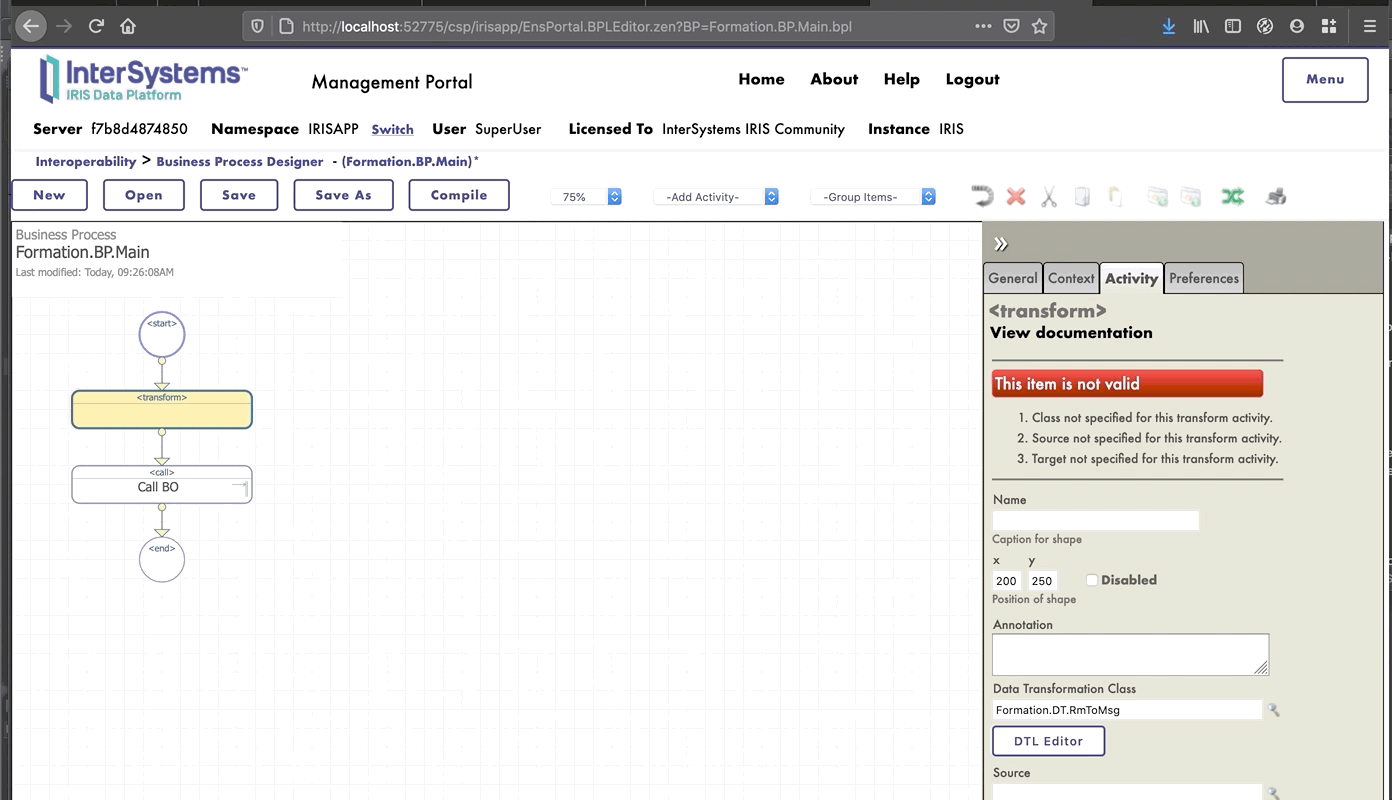
La actividad de transformación tomará la solicitud del *business process* (un registro del archivo CSV, gracias a nuestro servicio para mapear los registros) y la transformará en un mensaje `FormationInsertRequest`. Si deseamos almacenar ese mensaje para enviarlo al *business operation*, necesitamos añadir una propiedad al contexto del *business process*.
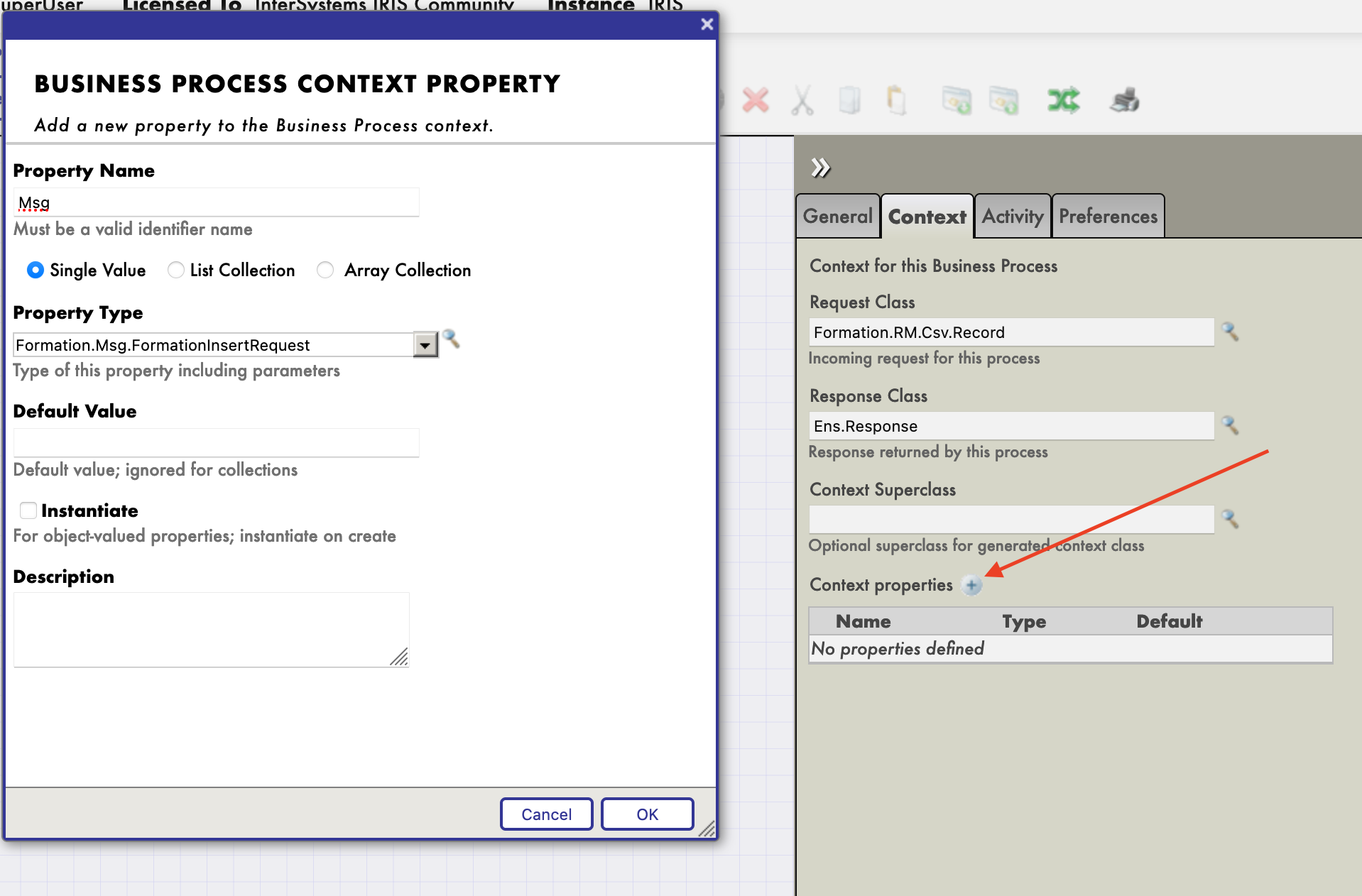
Ahora podemos configurar nuestra función de transformación para que tome su entrada como entrada del *business process* y guarde su salida en la propiedad recién creada. El origen y el objetivo de la transformación `RmToMsg` son `request` y `context.Msg`, respectivamente:

Tenemos que hacer lo mismo para `Call BO`. Su entrada, o `callrequest`, es el valor almacenado en `context.msg`:
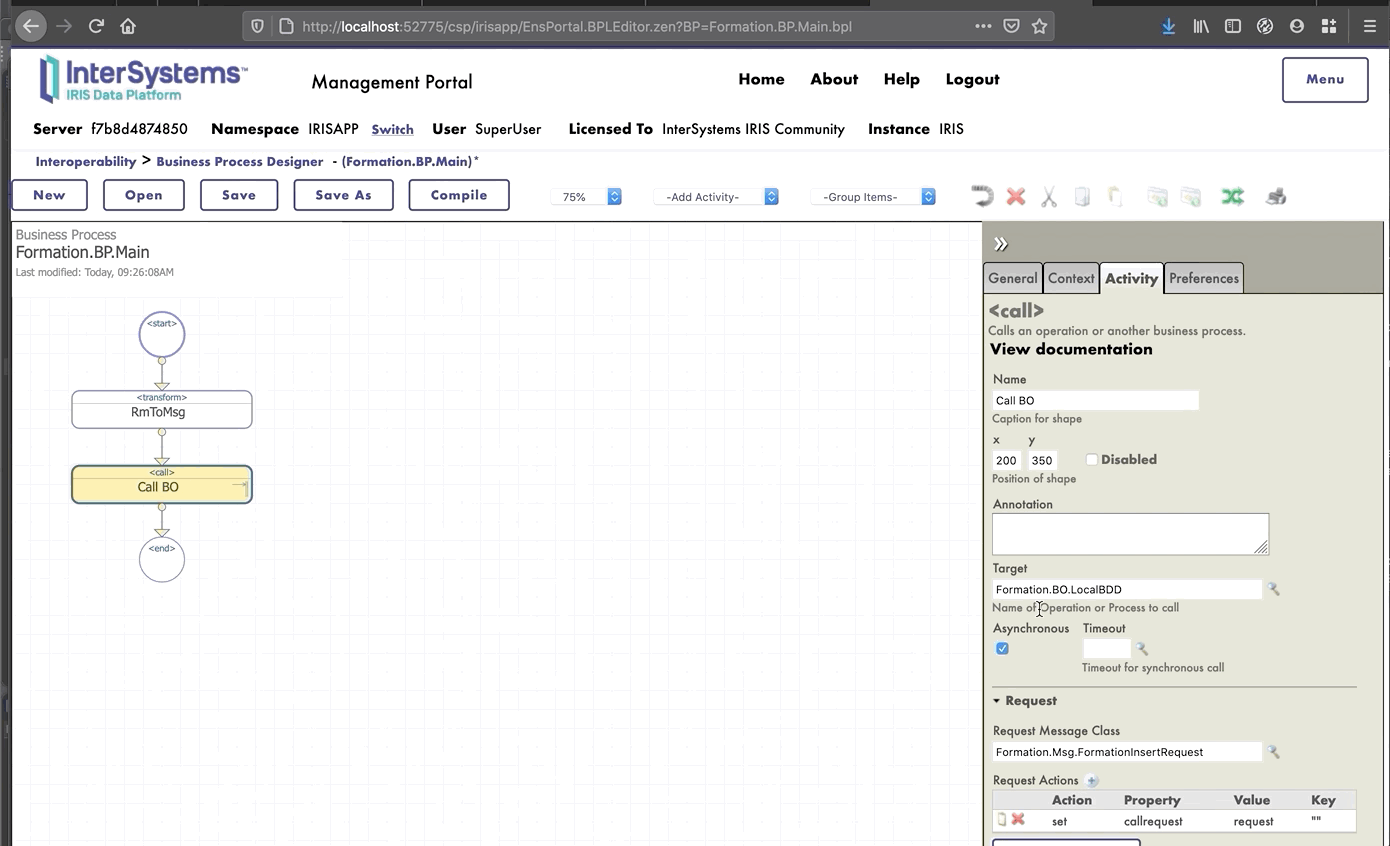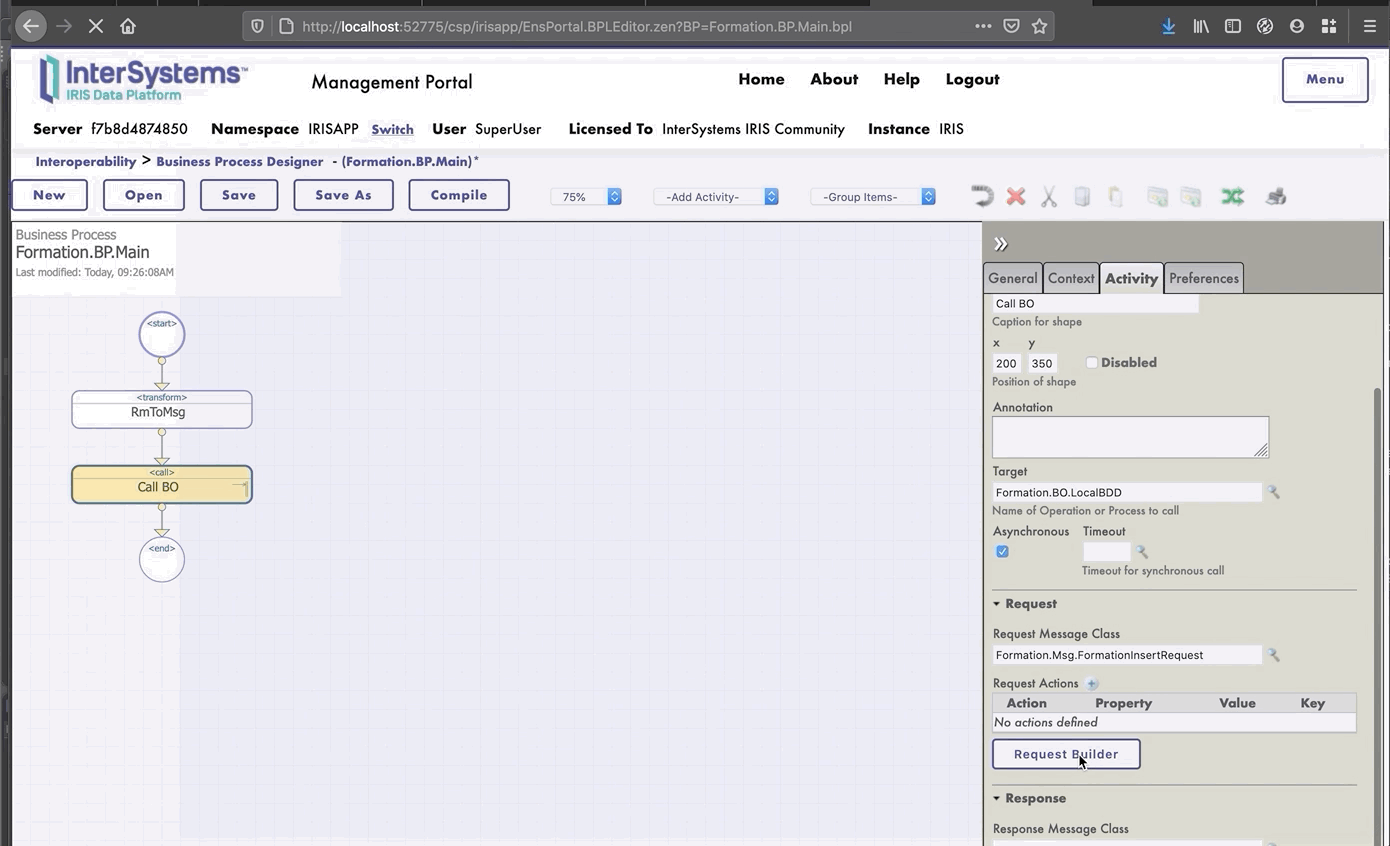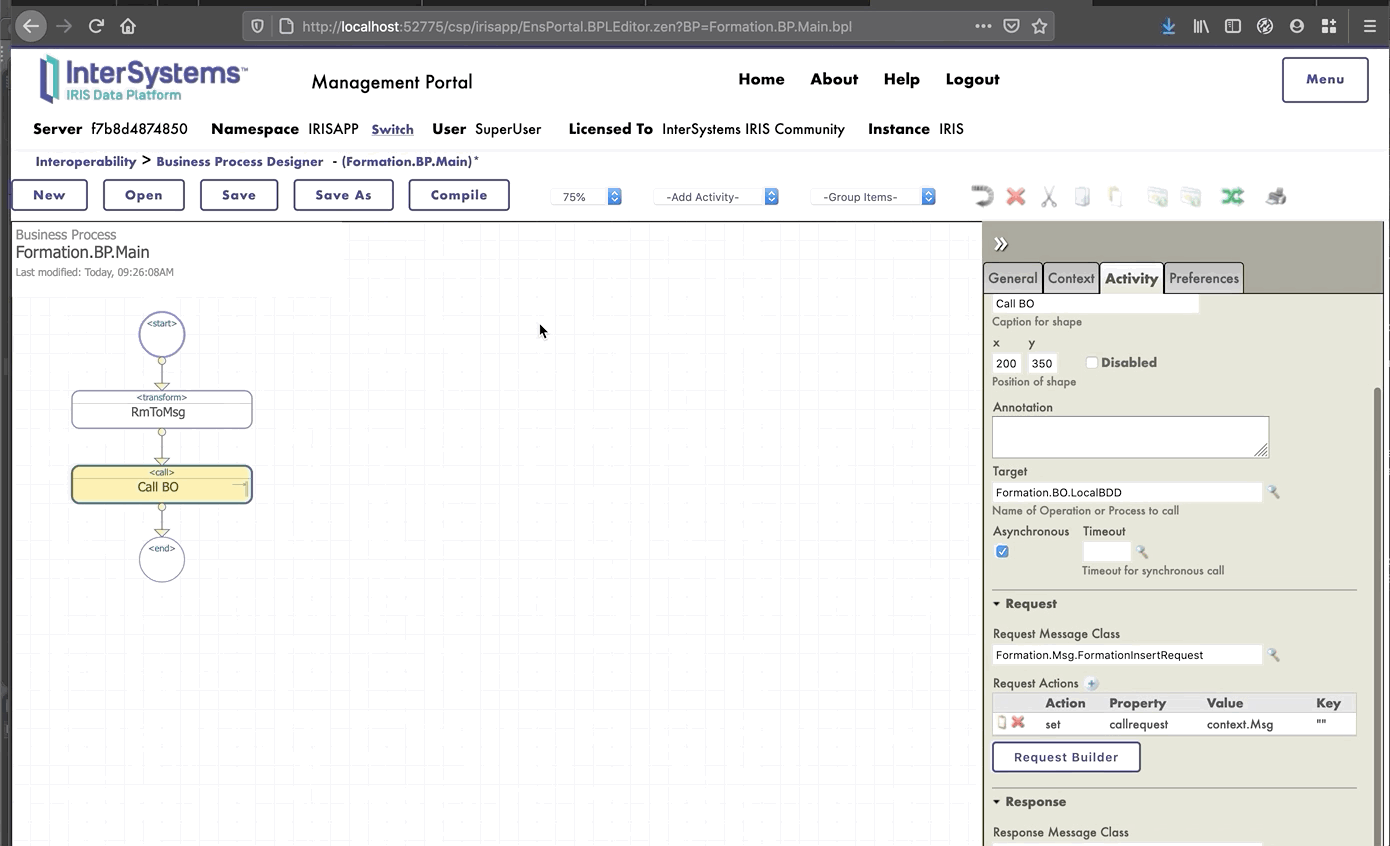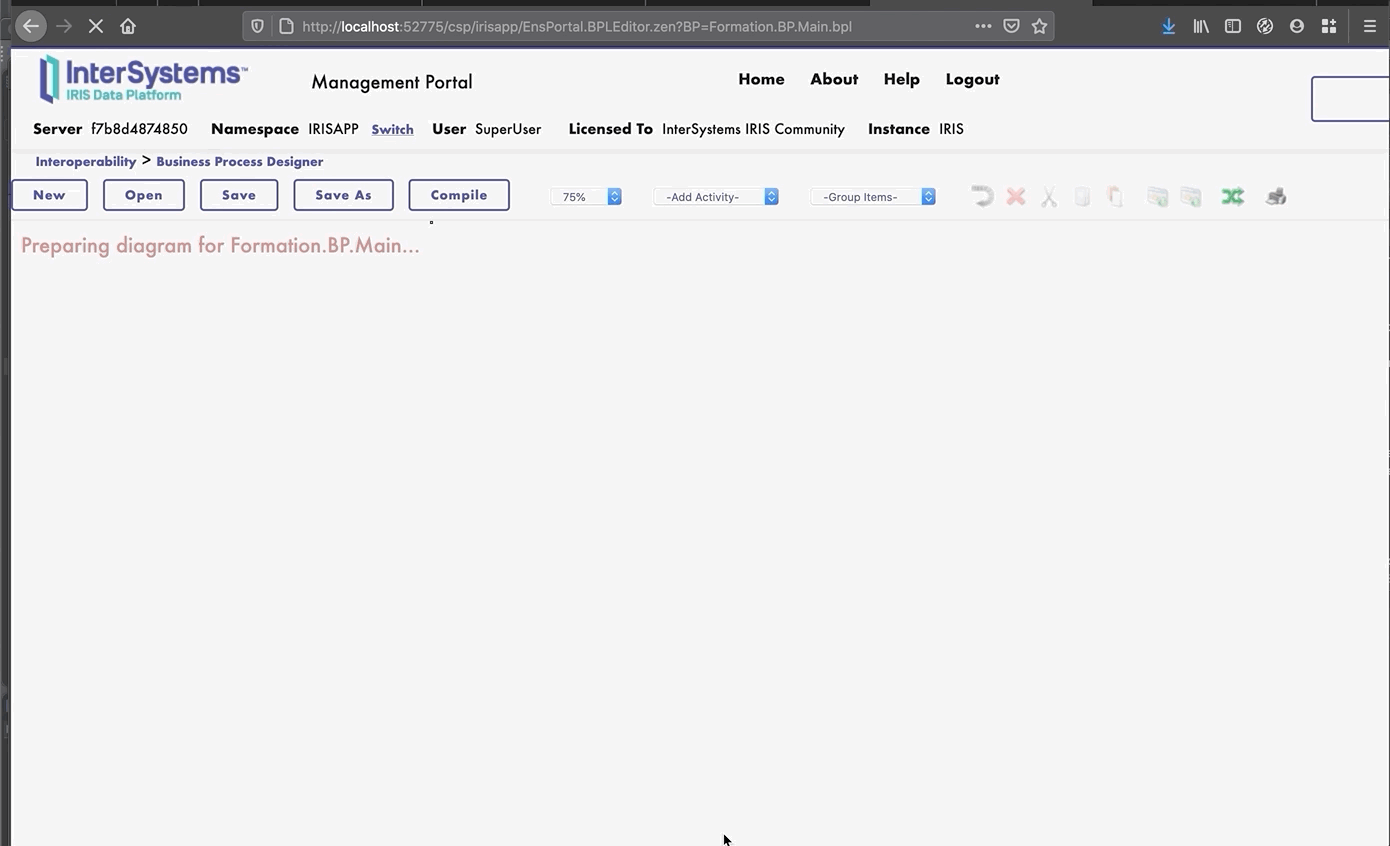
Al final, el flujo en el *business process* puede representarse de esta manera:
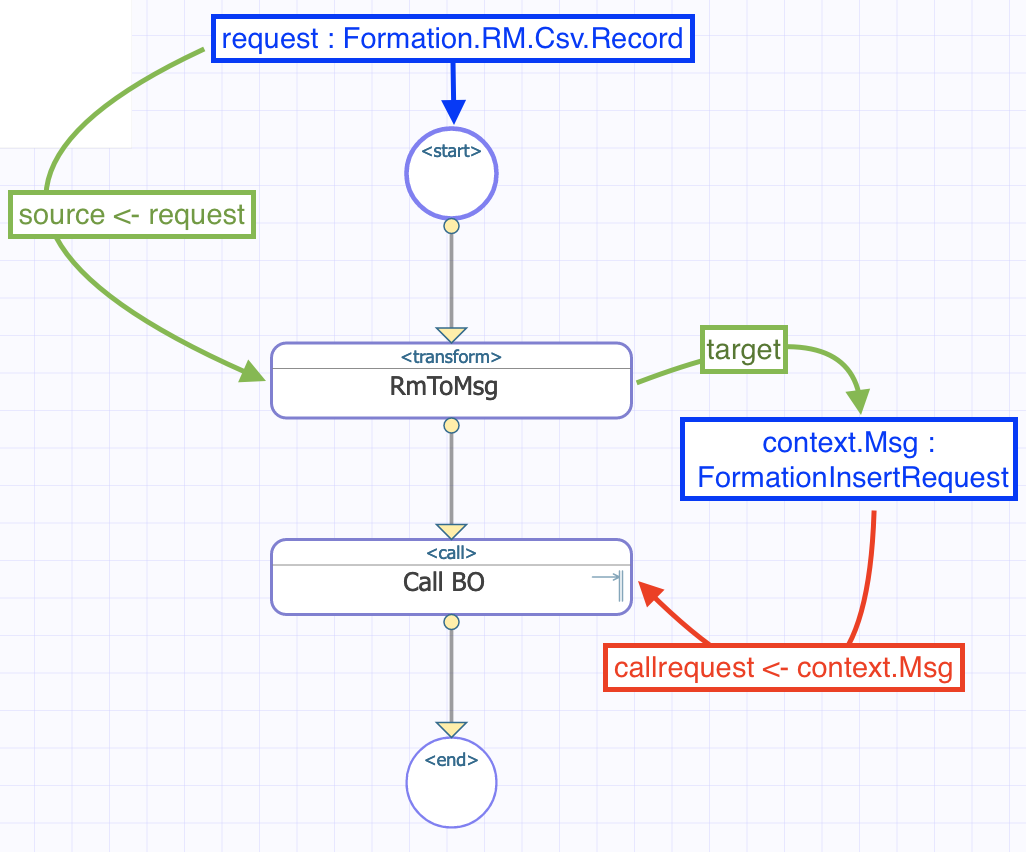
### 8.2.4. Configuración de la producción
Con el signo [+], podemos añadir nuestro nuevo proceso a la producción (si aún no lo hemos hecho). También necesitamos un servicio genérico para utilizar el Mapa de Registros, para ello utilizamos `EnsLib.RecordMap.Service.FileService` (lo añadimos con el botón [+] que está junto a los servicios). A continuación, parametrizamos este servicio:
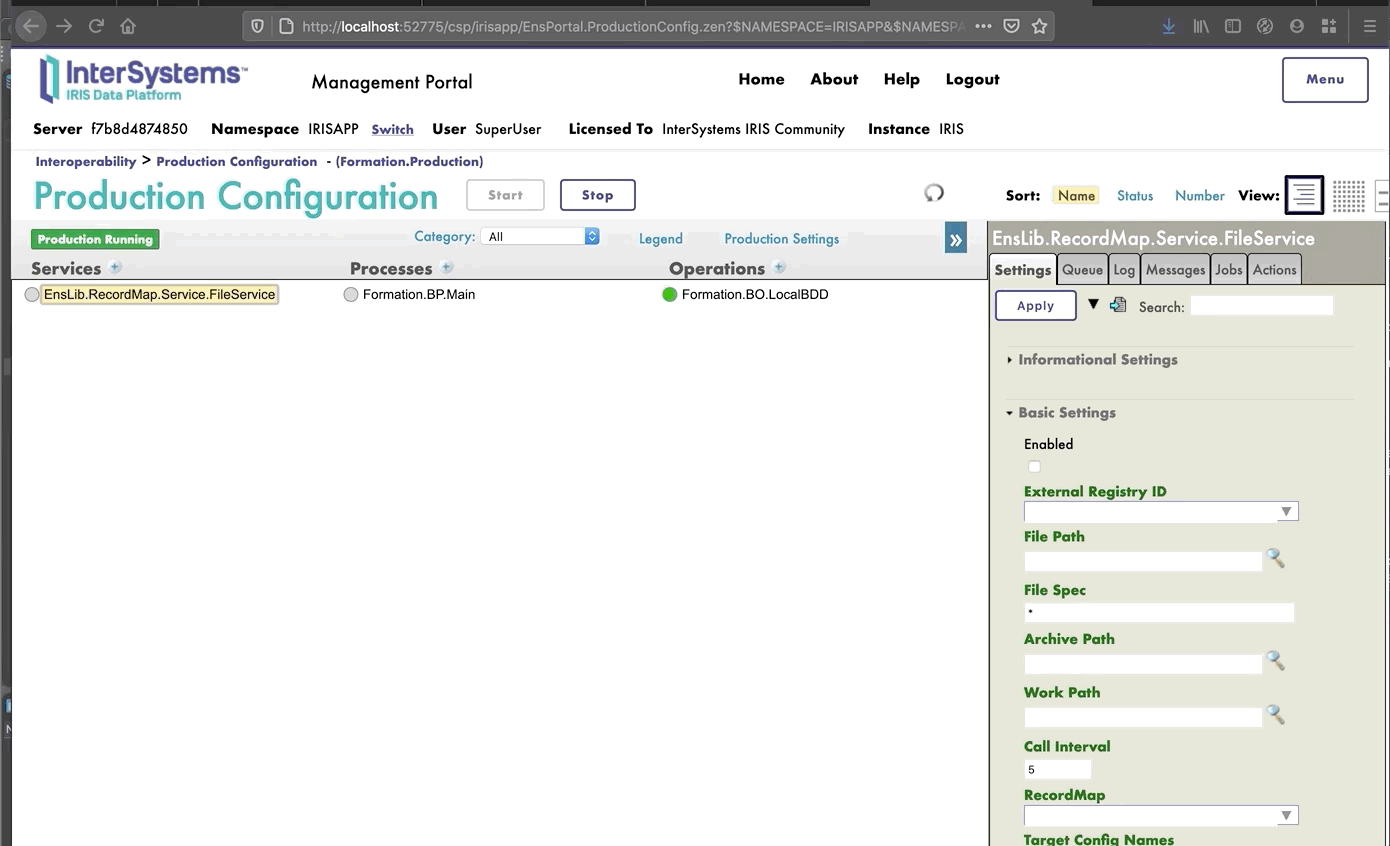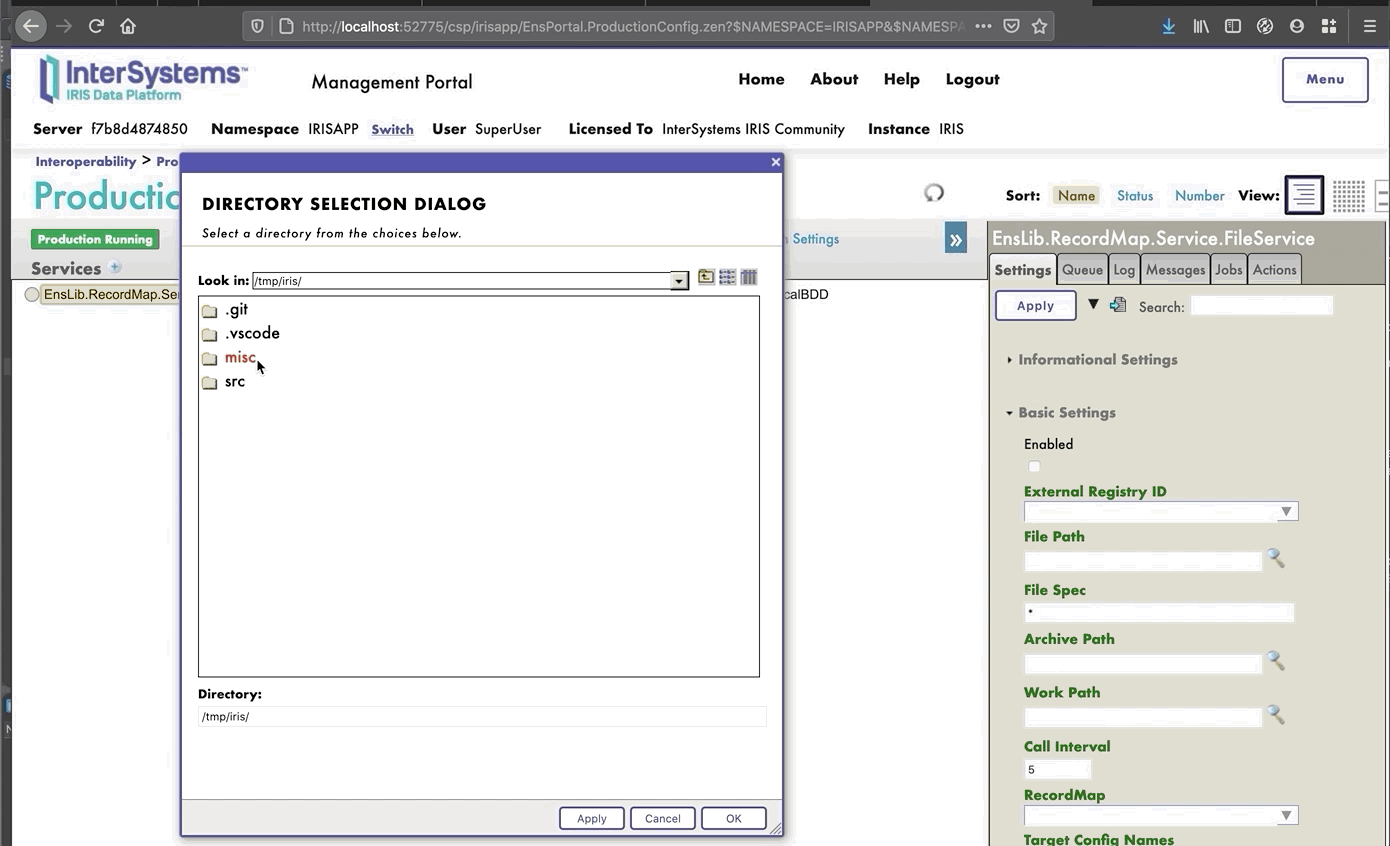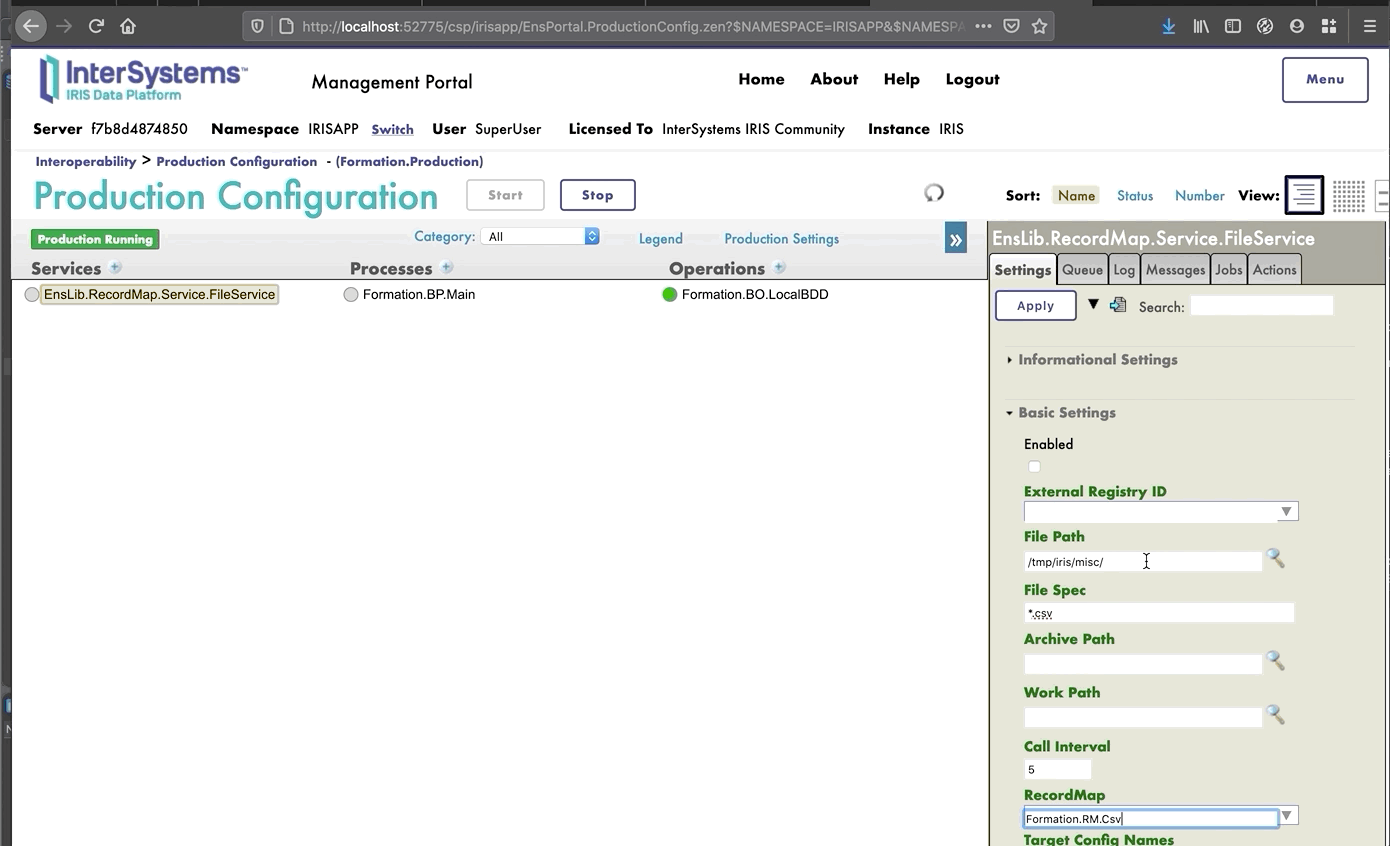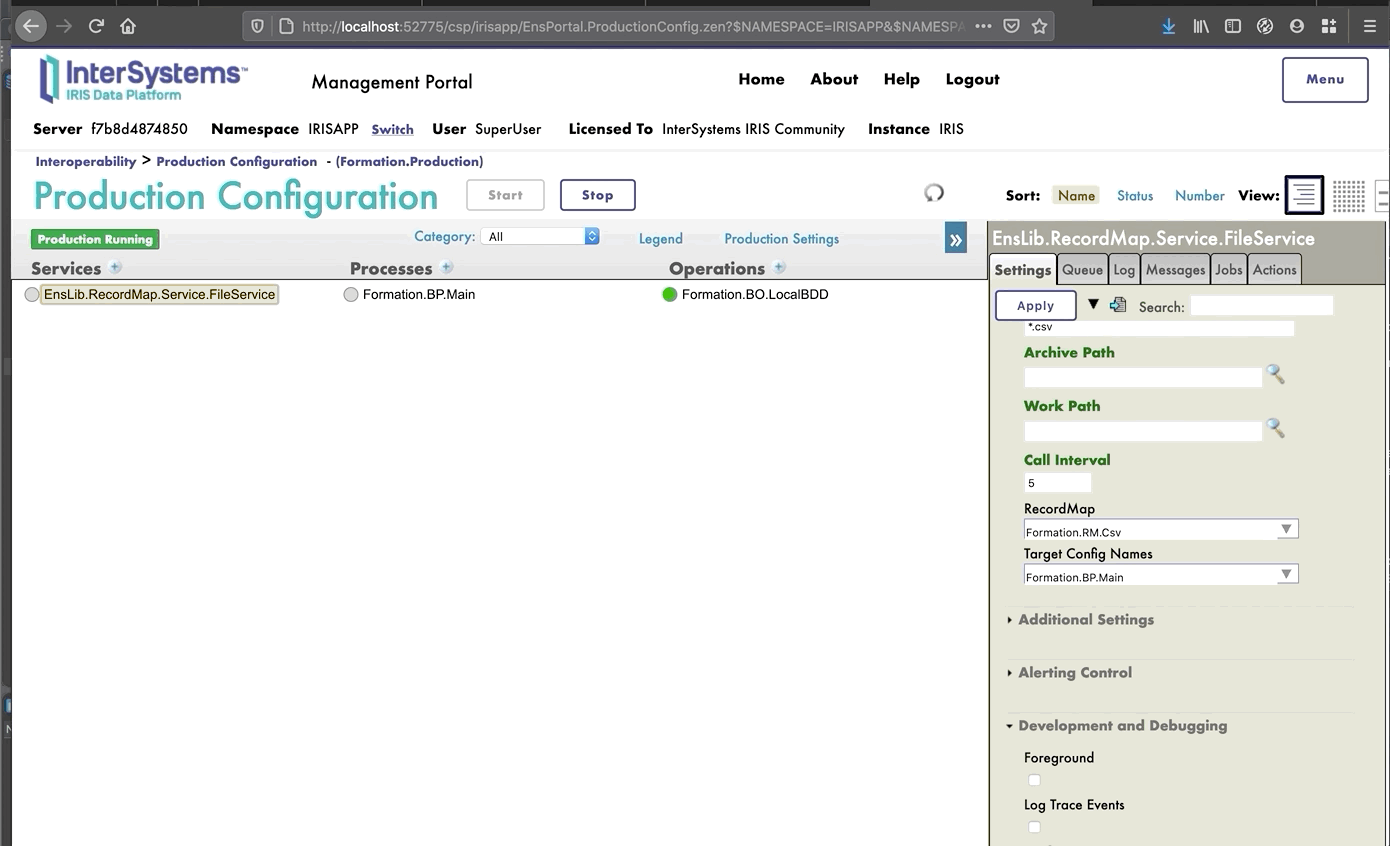
Ahora deberíamos poder probar nuestro *business process*.
### 8.2.5. Pruebas
Probamos toda la producción de esta manera:
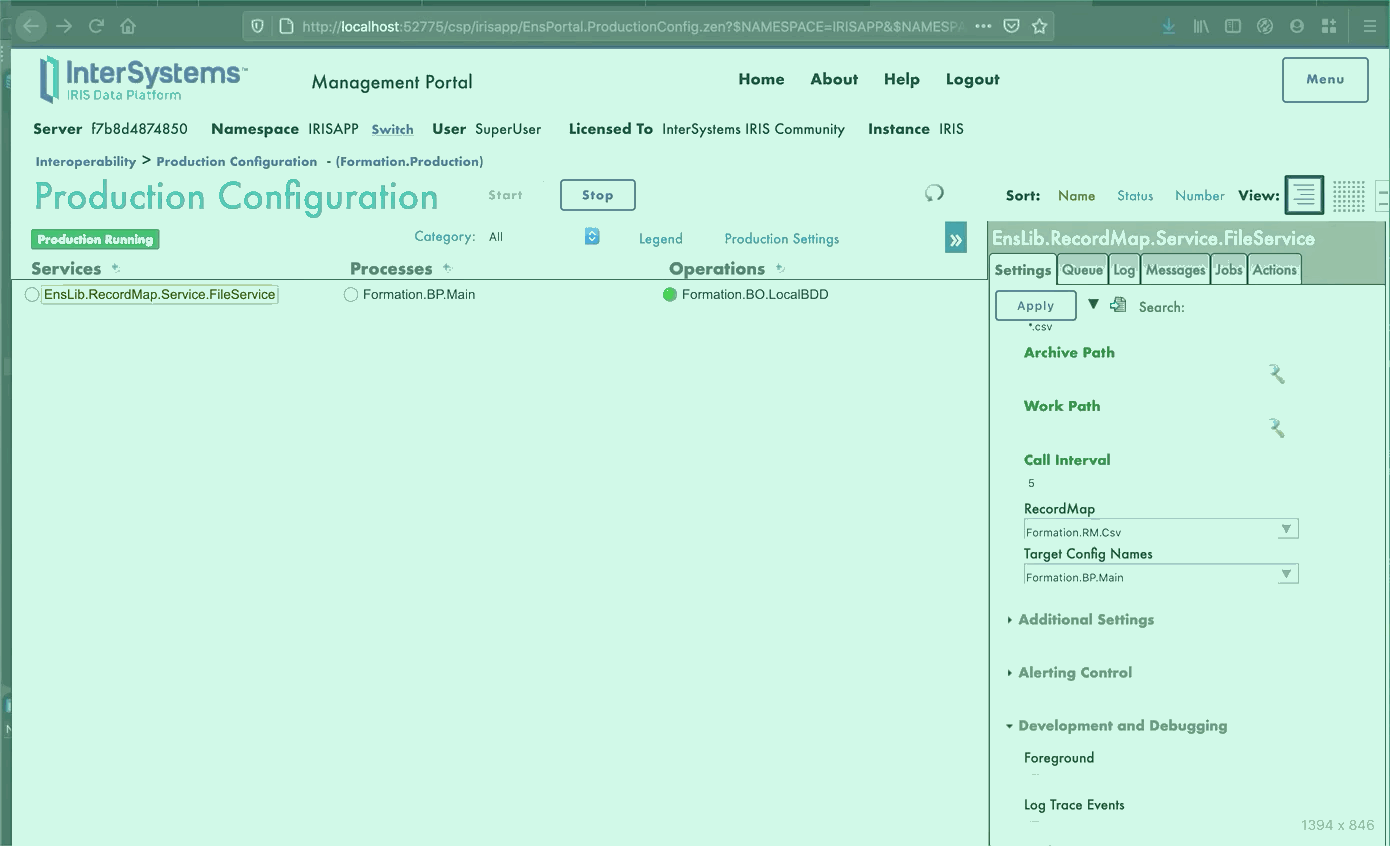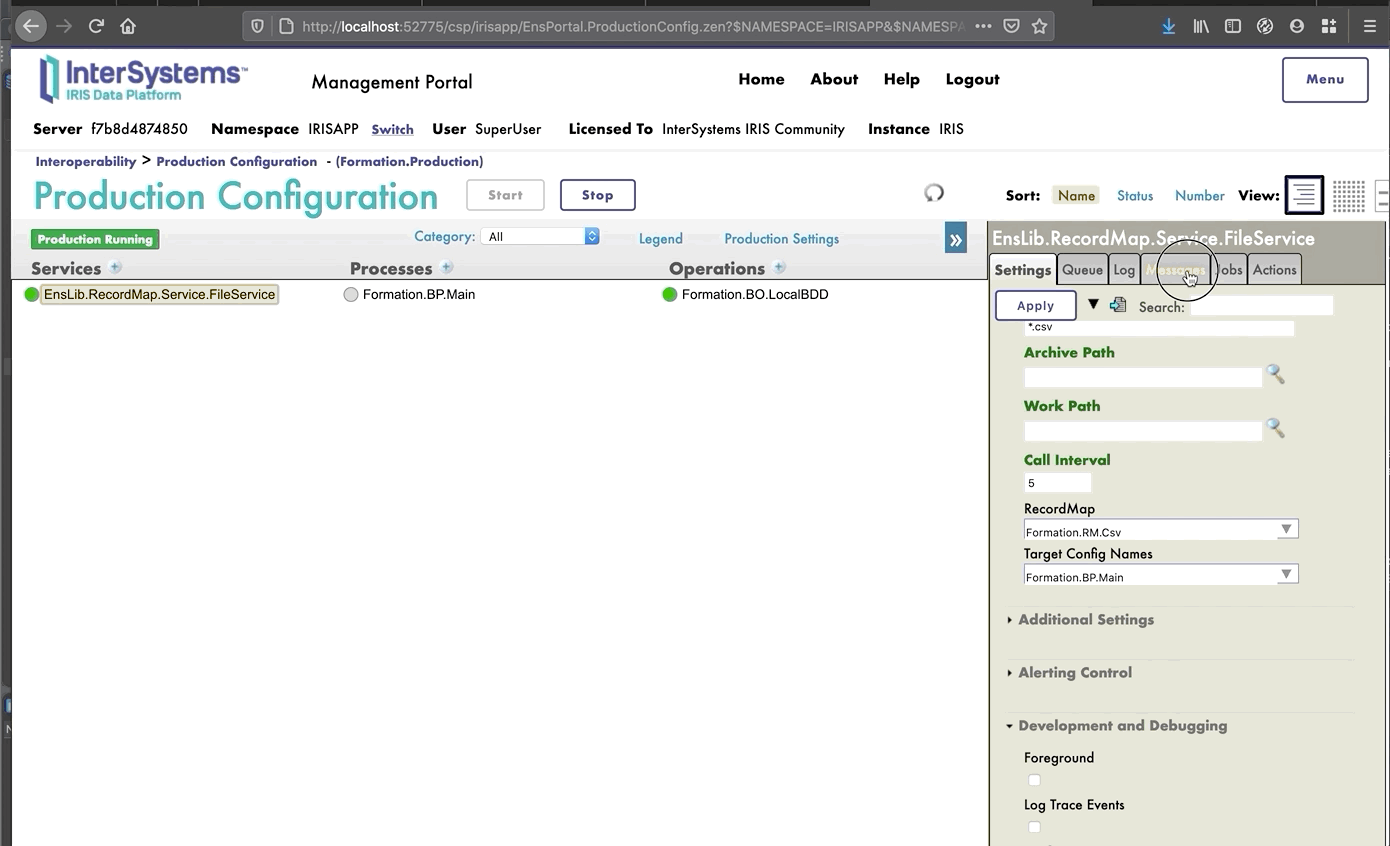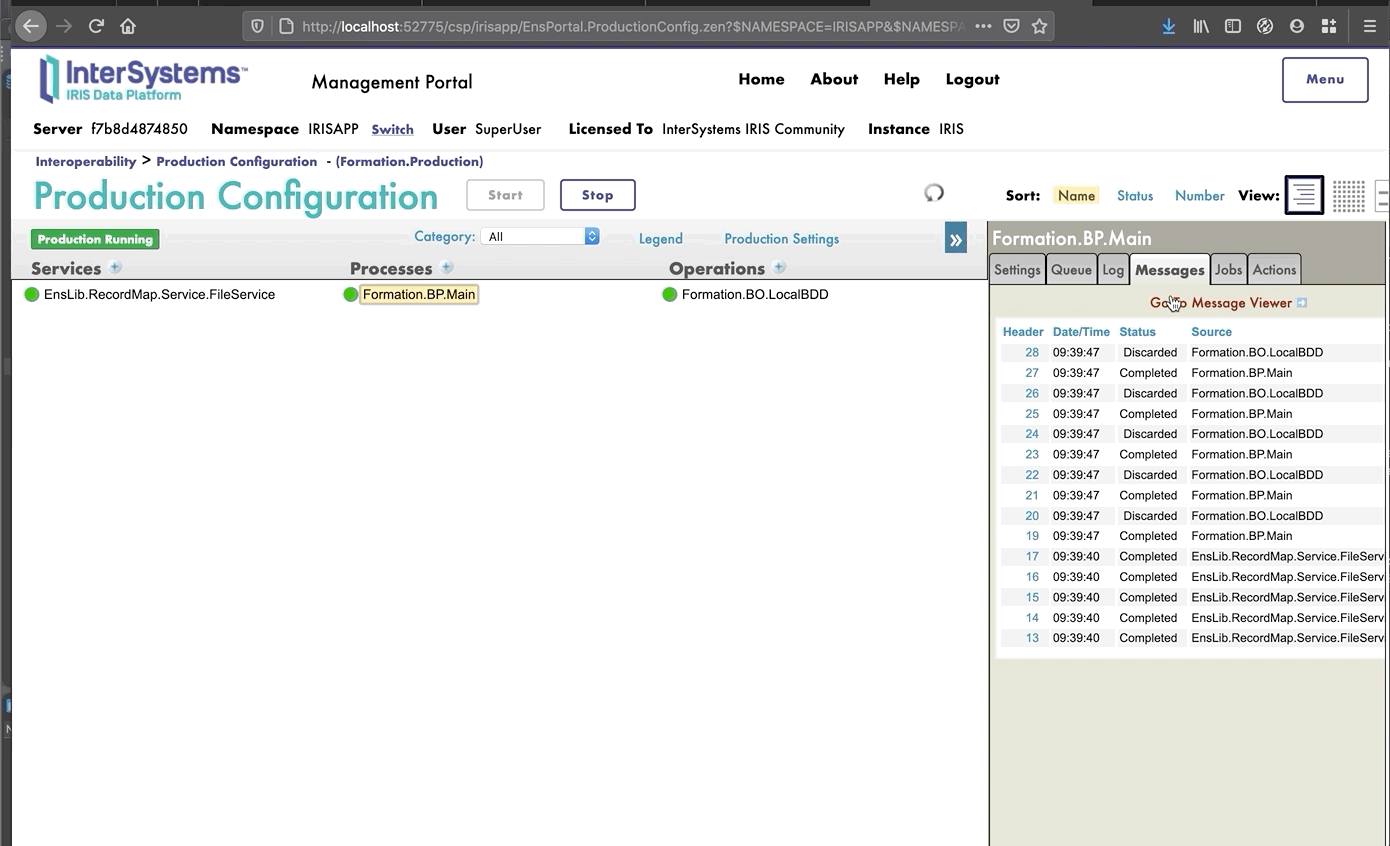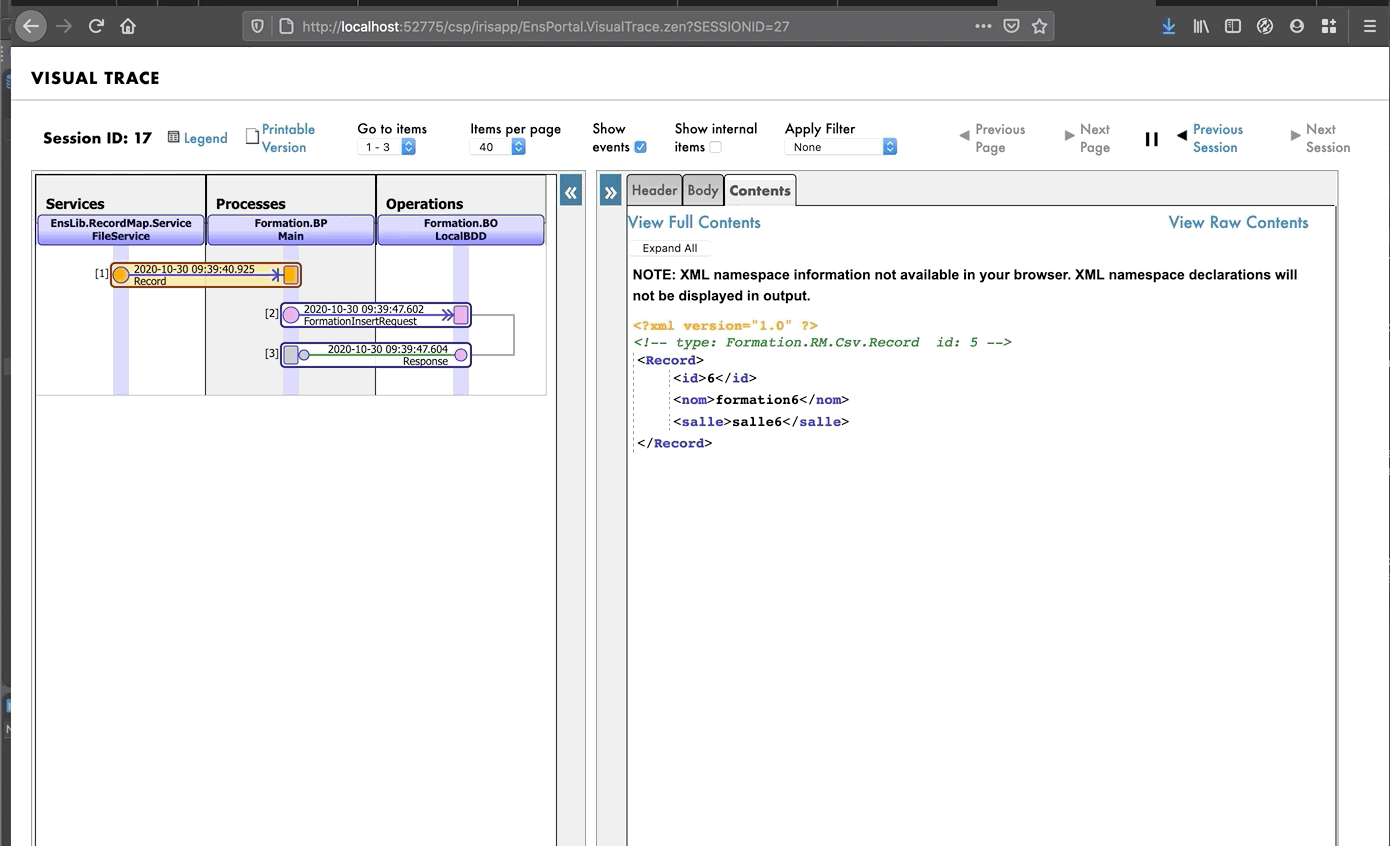
En el menú `System Explorer > SQL`, puedes ejecutar el comando
````sql
SELECT
ID, Name, Salle
FROM Formation_Table.Formation
````
para ver los objetos que acabamos de guardar.
# 9. Obtener acceso a una base de datos externa usando JDBC
En esta sección, crearemos una operación para guardar nuestros objetos en una base de datos externa. Utilizaremos la API de JDBC, así como el otro contenedor Docker que configuramos, con postgre en él.
## 9.1. Creación de nuestra nueva operación
Nuestra nueva operación, en el archivo `Formation/BO/RemoteBDD.cls` es así:
````objectscript
Include EnsSQLTypes
Class Formation.BO.RemoteBDD Extends Ens.BusinessOperation
{
Parameter ADAPTER = "EnsLib.SQL.OutboundAdapter";
Property Adapter As EnsLib.SQL.OutboundAdapter;
Parameter INVOCATION = "Queue";
Method InsertRemoteBDD(pRequest As Formation.Msg.FormationInsertRequest, Output pResponse As Ens.StringResponse) As %Status
{
set tStatus = $$$OK
try{
set pResponse = ##class(Ens.Response).%New()
set ^inc = $I(^inc)
set tInsertSql = "INSERT INTO public.formation (id, nom, salle) VALUES(?, ?, ?)"
$$$ThrowOnError(..Adapter.ExecuteUpdate(.nrows,tInsertSql,^inc,pRequest.Formation.Nom, pRequest.Formation.Salle ))
}
catch exp
{
Set tStatus = exp.AsStatus()
}
Quit tStatus
}
XData MessageMap
{
InsertRemoteBDD
}
}
````
Esta operación es similar a la primera que creamos. Cuando reciba un mensaje del tipo `Formation.Msg.FormationInsertRequest`, utilizará un adaptador para ejecutar solicitudes SQL. Esas solicitudes se enviarán a nuestra base de datos de postgre.
## 9.2. Configuración de la producción
Ahora, desde el Portal de Administración, crearemos una instancia de esa operación (añadiéndola con el signo [+] en la producción).
También necesitaremos añadir el JavaGateway para el controlador JDBC en los servicios. El nombre completo de este servicio es `EnsLib.JavaGateway.Service`.

Ahora necesitamos configurar nuestra operación. Como hemos configurado un contenedor postgre, y conectado su puerto `5432`, los valores que necesitamos en los siguientes parámetros son:
> DSN: `jdbc:postgresql://db:5432/DemoData`
>
> Controlador de JDBC: `org.postgresql.Driver`
>
> JDBC Classpath: `/tmp/iris/postgresql-42.2.14.jar`
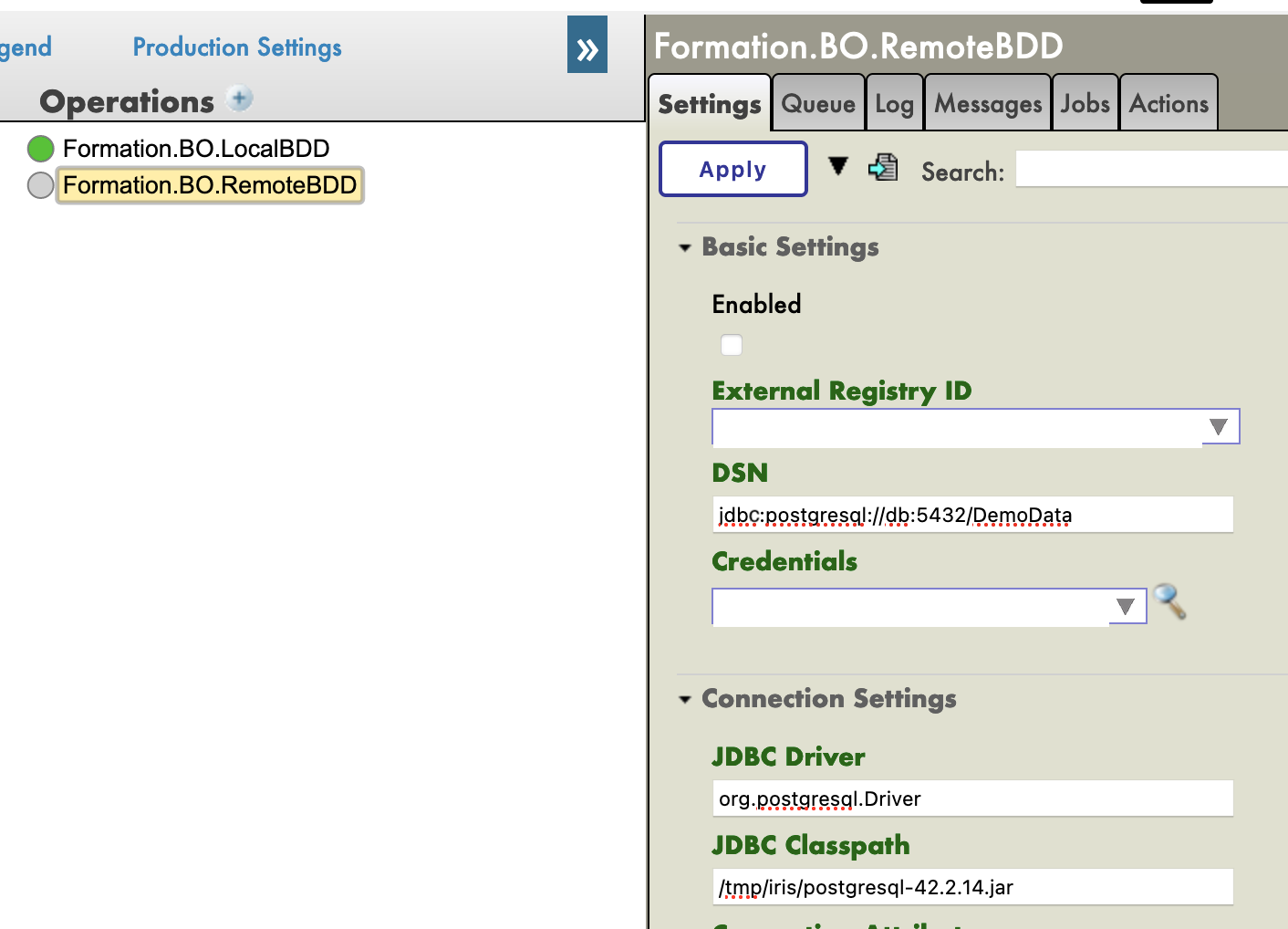
Finalmente, necesitamos configurar las credenciales para tener acceso a la base de datos remota. Para ello, necesitamos abrir el Visualizador de credenciales:
Tanto el nombre de usuario como la contraseña son `DemoData`, como lo configuramos en el archivo `docker-compose.yml`.
De vuelta a la producción, podemos añadir `"Postgre"` en el campo [Credential] en la configuración de nuestra operación (debería estar en el menú desplegable). Antes de que podamos probarlo, debemos añadir el JGService a la operación. En la pestaña [Settings], en [Additional Settings]:
## 9.3. Pruebas
Cuando se están haciendo pruebas el registro visual debe mostrar que tuvimos éxito:
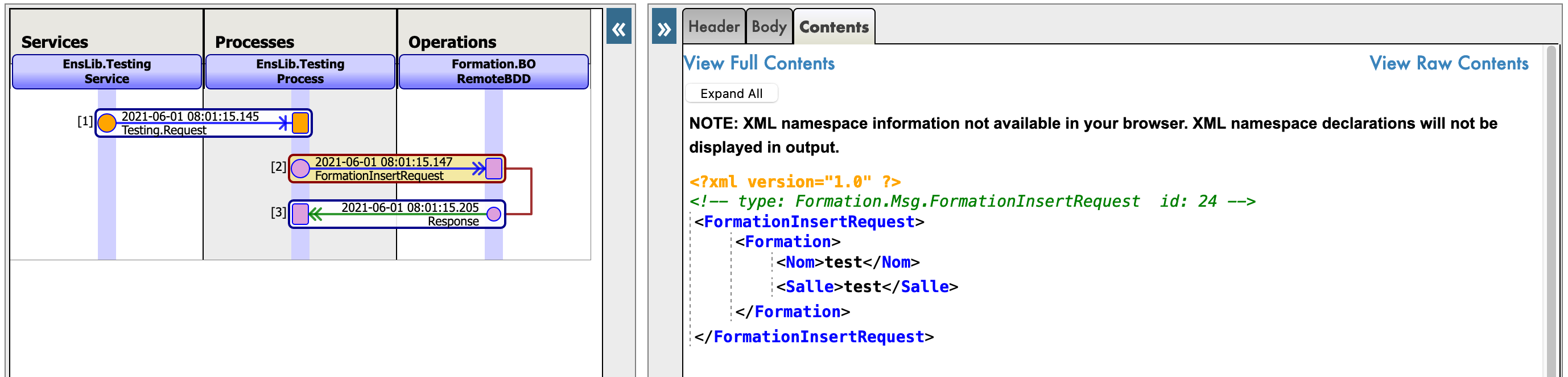
Conectamos correctamente una base de datos externa.
## 9.4. Ejercicio
Como ejercicio, podría ser interesante modificar BO.LocalBDD para que devuelva un booleano, que le dirá al *business process* que llame a BO.RemoteBDD dependiendo del valor de ese booleano.
**Sugerencia**: Esto se puede hacer cambiando el tipo de respuesta que devuelve LocalBDD, añadiendo una nueva propiedad al contexto y utilizando la actividad `if` en nuestro *business process*.
## 9.5. Solución
Primero, necesitamos tener una respuesta de nuestra operación LocalBDD. Vamos a crear un nuevo mensaje, en `Formation/Msg/FormationInsertResponse.cls`:
````objectscript
Class Formation.Msg.FormationInsertResponse Extends Ens.Response
{
Property Double As %Boolean;
}
````
Después, cambiamos la respuesta de LocalBDD por esa respuesta y establecemos el valor de su booleano de forma aleatoria (o no):
````objectscript
Method InsertLocalBDD(pRequest As Formation.Msg.FormationInsertRequest, Output pResponse As Formation.Msg.FormationInsertResponse) As %Status
{
set tStatus = $$$OK
try{
set pResponse = ##class(Formation.Msg.FormationInsertResponse).%New()
if $RANDOM(10) < 5 {
set pResponse.Double = 1
}
else {
set pResponse.Double = 0
}
...
````
Ahora crearemos un nuevo proceso (copiado del que hicimos), donde añadiremos una nueva propiedad de contexto, de tipo `%Boolean`:
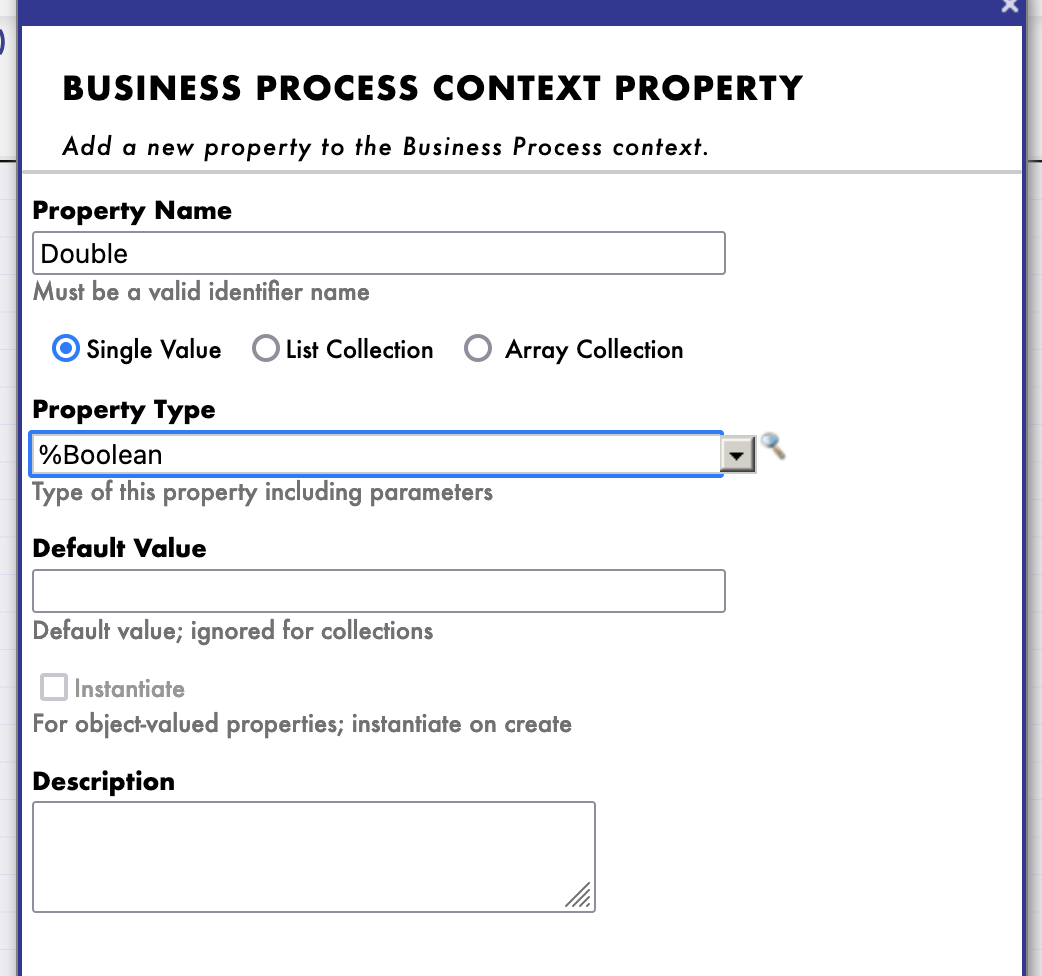
Esta propiedad se completará con el valor del callresponse.Double de nuestra llamada de operación (necesitaremos establecer [Response Message Class] en nuestra nueva clase de mensaje):
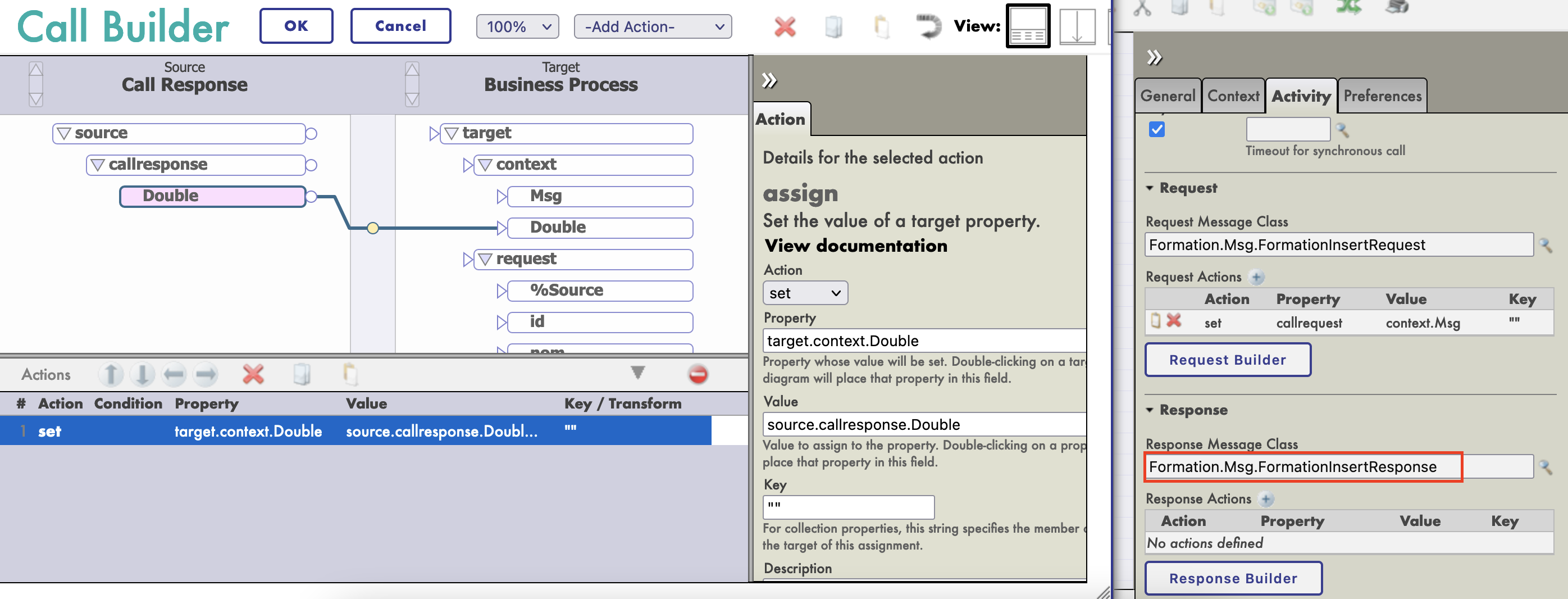
A continuación, añadimos una actividad `if`, con la propiedad `context.Double` como condición:

MUY IMPORTANTE: necesitamos desmarcar **Asynchronous** en la configuración de nuestra LocallBDD Call, o la actividad if se activará antes de que reciba la respuesta booleana.
Finalmente configuramos nuestra actividad de llamada como un objetivo RemoteBDD BO:

Para completar la actividad if, necesitamos arrastrar otro conector desde la salida del `if` al triángulo `join` que se encuentra debajo. Como no haremos nada si el valor booleano es falso, dejaremos este conector vacío.
Después de compilar y crear instancias, deberíamos poder probar nuestro nuevo proceso. Para ello, necesitamos cambiar `Target Config Name` de nuestro servicio de archivos.
En el seguimiento, deberíamos tener aproximadamente la mitad de los objetos leídos en el csv guardados también en la base de datos remota.
# 10. Servicio REST
En esta parte, crearemos y utilizaremos un Servicio REST.
## 10.1. Creación del servicio
Para crear un servicio REST, necesitamos una clase que extienda %CSP.REST, en `Formation/REST/Dispatch.cls` tenemos:
````objectscript
Class Formation.REST.Dispatch Extends %CSP.REST
{
/// Ignore any writes done directly by the REST method.
Parameter IgnoreWrites = 0;
/// By default convert the input stream to Unicode
Parameter CONVERTINPUTSTREAM = 1;
/// The default response charset is utf-8
Parameter CHARSET = "utf-8";
Parameter HandleCorsRequest = 1;
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
}
/// Get this spec
ClassMethod import() As %Status
{
set tSc = $$$OK
Try {
set tBsName = "Formation.BS.RestInput"
set tMsg = ##class(Formation.Msg.FormationInsertRequest).%New()
set body = $zcvt(%request.Content.Read(),"I","UTF8")
set dyna = {}.%FromJSON(body)
set tFormation = ##class(Formation.Obj.Formation).%New()
set tFormation.Nom = dyna.nom
set tFormation.Salle = dyna.salle
set tMsg.Formation = tFormation
$$$ThrowOnError(##class(Ens.Director).CreateBusinessService(tBsName,.tService))
$$$ThrowOnError(tService.ProcessInput(tMsg,.output))
} Catch ex {
set tSc = ex.AsStatus()
}
Quit tSc
}
}
````
Esta clase contiene una ruta para importar un objeto, vinculado al verbo POST:
````xml
````
El método de importación creará un mensaje que se enviará a un *business service*.
## 10.2. Añadir nuestro *Business Service* (BS)
Vamos a crear una clase genérica que dirigirá todas sus solicitudes hacia `TargetConfigNames`. Este objetivo se configurará cuando creemos una instancia de este servicio. En el archivo `Formation/BS/RestInput.cls` tenemos:
```objectscript
Class Formation.BS.RestInput Extends Ens.BusinessService
{
Property TargetConfigNames As %String(MAXLEN = 1000) [ InitialExpression = "BuisnessProcess" ];
Parameter SETTINGS = "TargetConfigNames:Basic:selector?multiSelect=1&context={Ens.ContextSearch/ProductionItems?targets=1&productionName=@productionId}";
Method OnProcessInput(pDocIn As %RegisteredObject, Output pDocOut As %RegisteredObject) As %Status
{
set status = $$$OK
try {
for iTarget=1:1:$L(..TargetConfigNames, ",") {
set tOneTarget=$ZStrip($P(..TargetConfigNames,",",iTarget),"W") Continue:""=tOneTarget
$$$ThrowOnError(..SendRequestSync(tOneTarget,pDocIn,.pDocOut))
}
} catch ex {
set status = ex.AsStatus()
}
Quit status
}
}
```
Volviendo a la configuración de la producción, añadimos el servicio de la manera habitual. En [Target Config Names], ponemos nuestro BO LocalBDD:
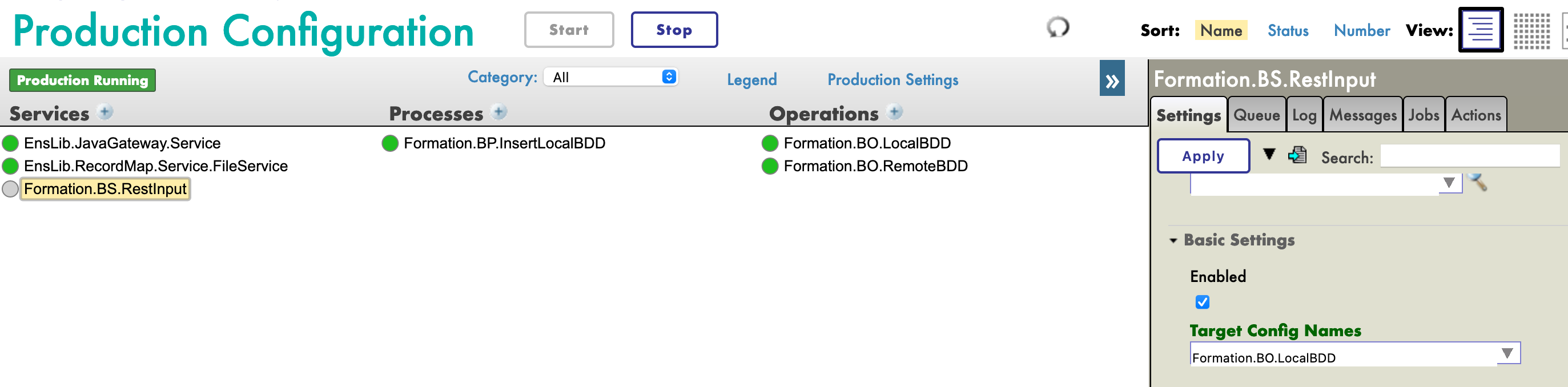
Para utilizar este servicio, necesitamos publicarlo. Para ello, usamos el menú [Edit Web Application]:
## 10.3. Pruebas
Por último, podemos probar nuestro servicio con cualquier tipo de cliente REST:
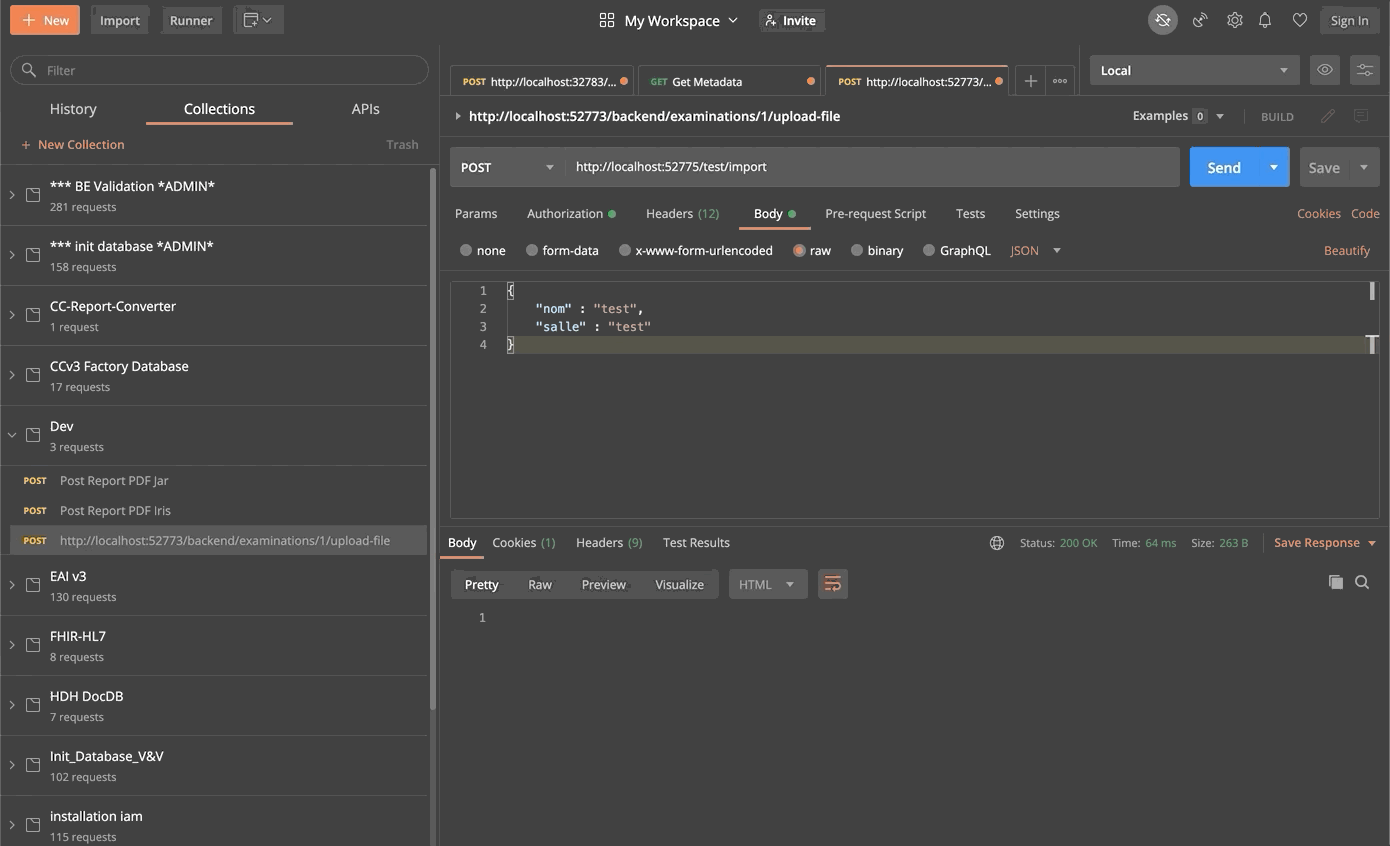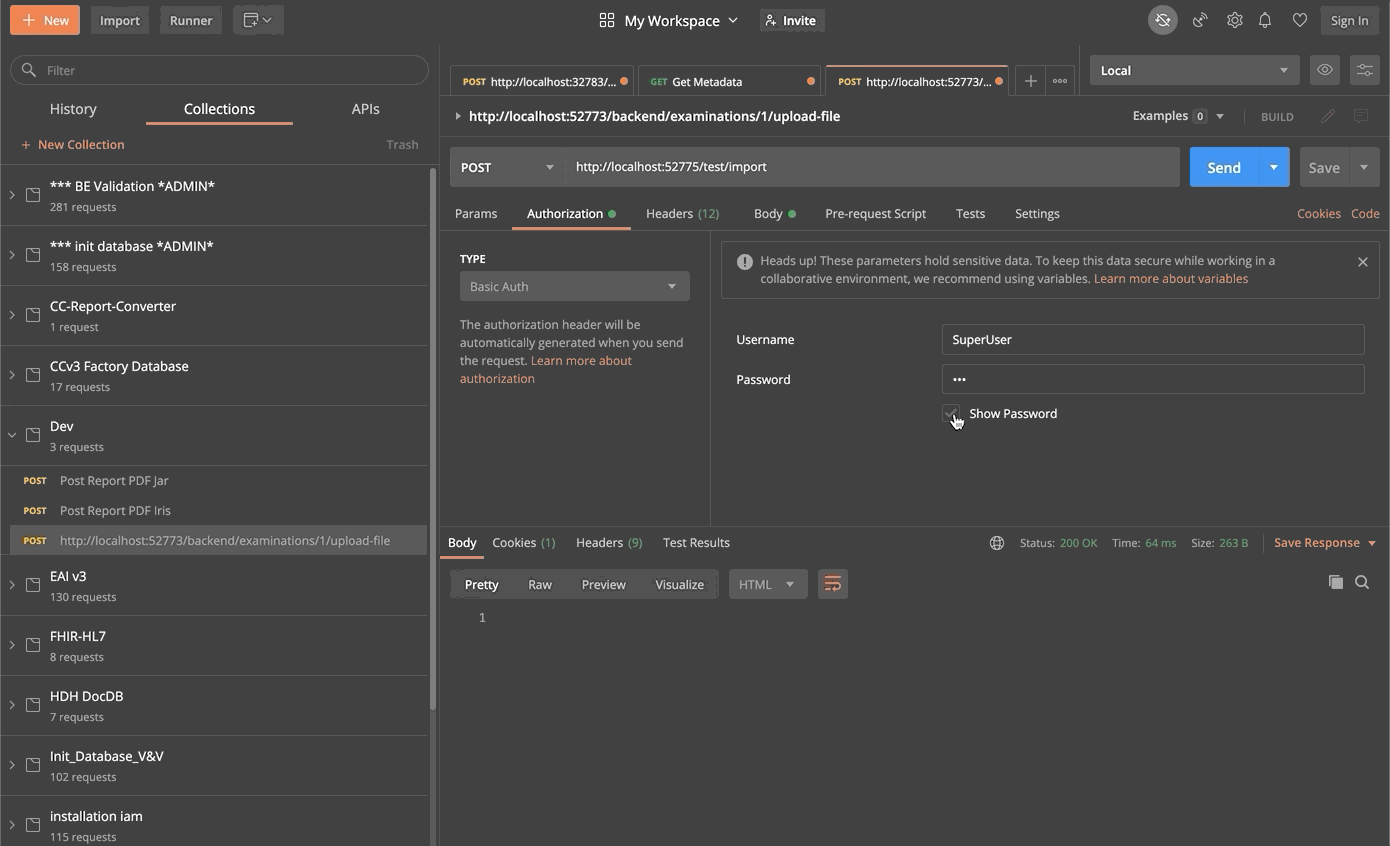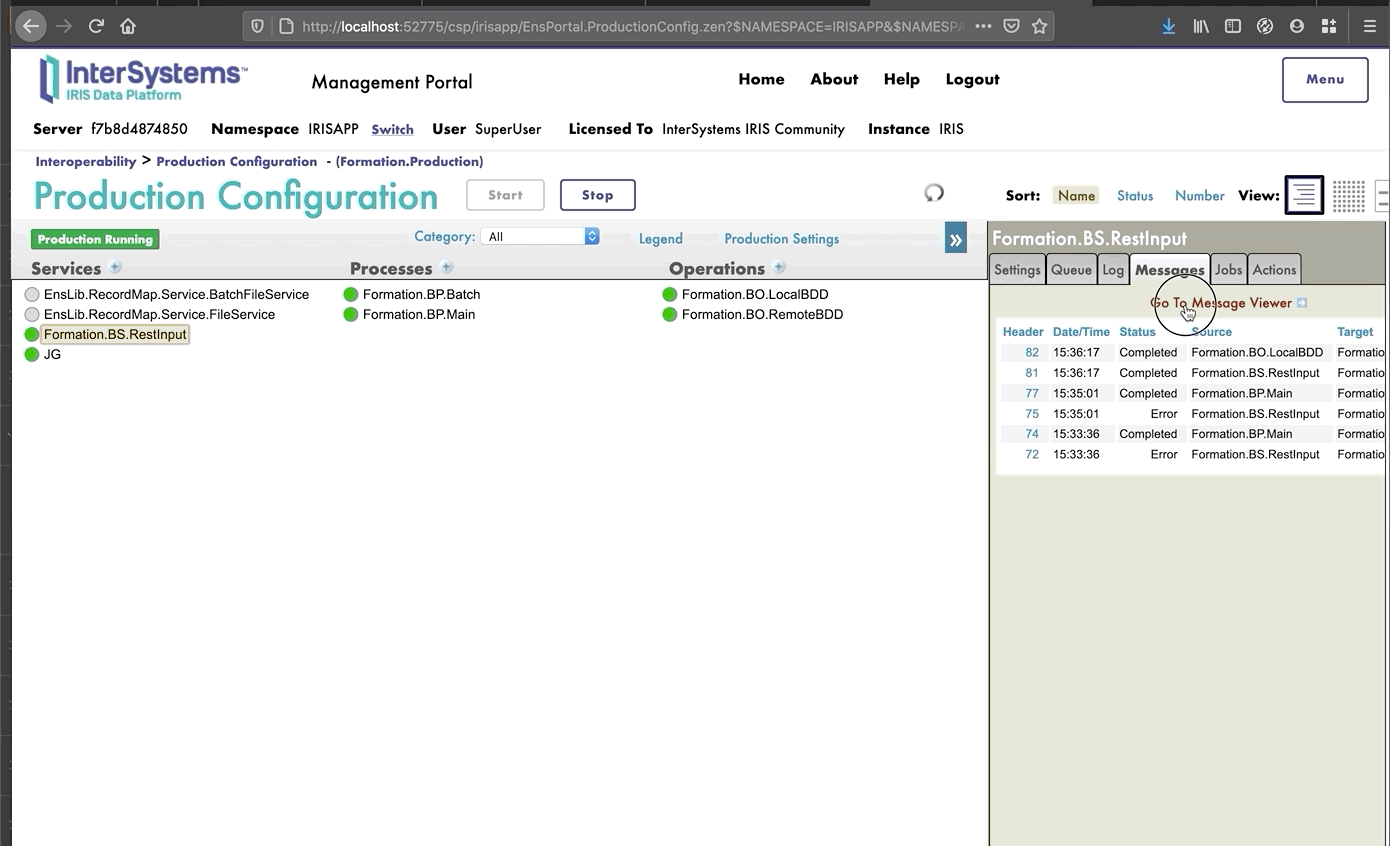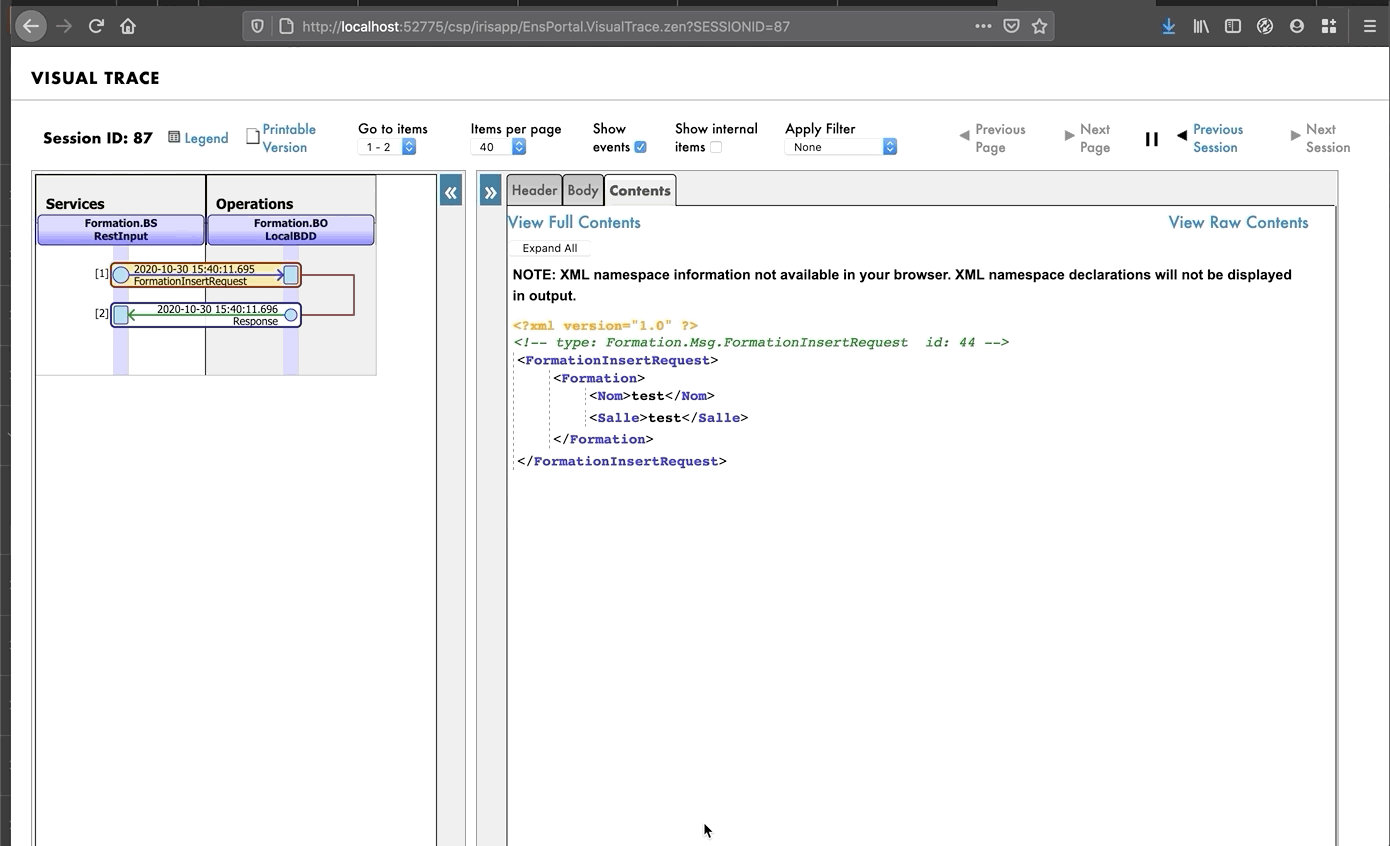
# Conclusión
A través de esta formación, hemos creado una producción que es capaz de leer líneas desde un archivo csv y guardar los datos leídos tanto en la base de datos de IRIS como en una base de datos externa, utilizando JDBC. También añadimos un servicio REST para utilizar el verbo POST para guardar nuevos objetos.
Hemos descubierto los principales elementos del *framework* de interoperabilidad de InterSystems.
Lo hemos hecho utilizando Docker, VSCode y el Portal de Administración de InterSystems IRIS.
Artículo
Jose-Tomas Salvador · 7 jul, 2021
**Palabras clave** PyODBC, unixODBC, IRIS, IntegratedML, Jupyter Notebook, Python 3
## **Propósito**
Hace unos meses traté el tema de la "[conexión con JDBC desde Python a la base de datos de IRIS](https://es.community.intersystems.com/post/conexi%C3%B3n-con-jdbc-desde-python-la-base-de-datos-de-iris-una-nota-r%C3%A1pida)", y desde entonces utilicé ese artículo con más frecuencia que mi propia nota oculta en mi PC. Por eso, traigo aquí otra nota de 5 minutos sobre cómo hacer una "conexión con JDBC desde Python a la base de datos de IRIS". ODBC y PyODBC parecen bastante fáciles de configurar en un cliente de Windows, sin embargo, siempre me atasco un poco en la configuración de un cliente unixODBC y PyODBC en un servidor de estilo Linux/Unix. ¿Existe un enfoque tan sencillo y consistente como se supone que debe ser para hacer que el trabajo de instalación de PyODBC/unixODBC funcione en un cliente linux estándar sin ninguna instalación de IRIS, contra un servidor IRIS remoto?
## **Alcance**
Hace poco tuve que dedicar un tiempo a hacer funcionar desde cero una demo de PyODBC dentro de Jupyter Notebook en un entorno Docker en Linux. De ahí me surgió la idea de realizar esta nota detallada, para futuras consultas.
#### **En el alcance:**
En esta nota vamos a tratar los siguientes componentes:
PyODBC sobre unixODBC
El servidor de Jupyter Notebook con Tensorflow 2.2 y Python 3
Servidor IRIS2020.3 CE con IntegratedML, incluyendo datos de prueba de ejemplo.
dentro de este entorno
El motor Docker con Docker-compose sobre AWS Ubuntu 16.04
Docker Desktop para MacOS, y la Docker Toolbos for Windows 10 también están probadas
#### **Fuera del alcance**:
De nuevo, los aspectos no funcionales no se evalúan en este entorno de demo. Son importantes y pueden tratarse por separado, como:
Seguridad y auditoría de extremo a extremo.
Rendimiento y escalabilidad
Licencias y soporte, etc.
## **Entorno**
Se puede usar cualquier imagen en Docker para Linux en las configuraciones y los pasos de prueba que se indican a continuación, pero una forma sencilla de configurar un entorno de este tipo en 5 minutos es:
1. **Clonar** en Git esta [plantilla de demostración](https://github.com/tom-dyar/integratedml-demo-template)
2. Ejecutar "**docker-compose up -d**" en el directorio clonado que contiene el archivo docker-compose.yml. Simplemente creará un entorno de demostración, como se muestra en la siguiente imagen, de 2 contenedores. Uno para el servidor de Jupyter Notebook como cliente PyODBC, y otro para un servidor IRIS2020.3 CE.
En el entorno anterior, el tf2jupyter solo contiene una configuración de cliente "Python sobre JDBC", todavía no contiene ninguna configuración de cliente ODBC o PyODBC. Así que ejecutaremos los siguientes pasos para configurarlo, directamente desde Jupyter Notebook para que sea autoexplicativo.
## **Pasos**
Ejecuté las siguientes configuraciones y pruebas en un servidor AWS Ubuntu 16.04. Mi colega @Thomas.Dyar los ejecutó en MacOS. También lo probé brevemente en Docker Toolbox for Windows. Pero haznos saber si encuentras algún problema. Los siguientes pasos se pueden automatizar de forma sencilla en tu Dockerfile. Lo grabé manualmente aquí en caso de que se me olvide cómo se hacía después de unos meses.
### **1. Documentación oficial:**
Soporte de ODBC para IRIS
Cómo definir la fuente de datos ODBC en Unix
Soporte PyODBC para IRIS
### **2. Conectarse al servidor Jupyter**
Utilicé el SSH tunneling de Putty en forma local en el puerto 22 de AWS Ubuntu remoto, después mapeé al puerto 8896 como en la imagen anterior. (Por ejemplo, en el entorno local de Docker también se puede utilizar http directamente en la IP:8896 del equipo Docker).
### **3. Ejecutar la instalación de ODBC desde Jupyter Notebook**
Ejecuta la siguiente línea de comando directamente desde una celda en Jupyter:
!apt-get update
!apt-get install gcc
!apt-get install -y tdsodbc unixodbc-dev
!apt install unixodbc-bin -y
!apt-get clean -y
Instalará el compilador gcc (incluyendo g++), FreeTDS, unixODBC y unixodbc-dev , que son necesarios para volver a compilar el *driver* PyODBC en el siguiente paso. Este paso no es necesario en un servidor nativo de Windows o PC para la instalación de PyODBC.
### **4. Ejecutar la instalación de PyODBC desde Jupyter**
!pip install pyodbc
Collecting pyodbc
Downloading pyodbc-4.0.30.tar.gz (266 kB)
|████████████████████████████████| 266 kB 11.3 MB/s eta 0:00:01
Building wheels for collected packages: pyodbc
Building wheel for pyodbc (setup.py) ... done
Created wheel for pyodbc: filename=pyodbc-4.0.30-cp36-cp36m-linux_x86_64.whl size=273453 sha256=b794c35f41e440441f2e79a95fead36d3aebfa74c0832a92647bb90c934688b3
Stored in directory: /root/.cache/pip/wheels/e3/3f/16/e11367542166d4f8a252c031ac3a4163d3b901b251ec71e905
Successfully built pyodbc
Installing collected packages: pyodbc
Successfully installed pyodbc-4.0.30
Lo anterior es la instalación mínima de PIP para esta demostración de Docker. En la [documentación oficial](https://irisdocs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=BNETODBC_support#BNETODBC_support_pyodbc), para la "Instalación de MacOS X", se proporcionan instrucciones para una instalación de PIP más detallada.
### **5. Volver a configurar los archivos y enlaces ODBC INI en Linux:**
Ejecuta las siguientes líneas de comando para volver a crear los enlaces **odbcinst.ini** y **odbc.ini**
!rm /etc/odbcinst.ini !rm /etc/odbc.ini
!ln -s /tf/odbcinst.ini /etc/odbcinst.ini !ln -s /tf/odbc.ini /etc/odbc.ini
Nota: La razón de realizar lo anterior es que **los pasos 3 y 4 normalmente crearían 2 archivos ODBC en blanco (por lo tanto, no válidos) en el directorio \etc\.** A diferencia de la instalación de Windows, estos archivos ini en blanco causan problemas, por lo tanto, debemos eliminarlos y luego simplemente volver a crear un enlace a los archivos ini reales proporcionados en un volumen Docker mapeado: /tf/odbcinst.ini, y /tf/odbc.ini Revisemos estos 2 archivos ini - en este caso, son la forma más simple para las configuraciones ODBC de Linux:
!cat /tf/odbcinst.ini
[InterSystems ODBC35]
UsageCount=1
Driver=/tf/libirisodbcu35.so
Setup=/tf/libirisodbcu35.so
SQLLevel=1
FileUsage=0
DriverODBCVer=02.10
ConnectFunctions=YYN
APILevel=1
DEBUG=1
CPTimeout=<not Pooled>
!cat /tf/odbc.ini
[IRIS PyODBC Demo]
Driver=InterSystems ODBC35
Protocol=TCP
Host=irisimlsvr
Port=51773
Namespace=USER
UID=SUPERUSER
Password=SYS
Description=Sample namespace
Query Timeout=0
Static Cursors=0
Los archivos anteriores están pre-configurados y se proporcionan en la unidad mapeada. Esto se refiere al driver **libirisodbcu35.so,** que también se puede conseguir en la instancia del contenedor del servidor IRIS (en su directorio {iris-installation}/bin). Por lo tanto, para que la instalación ODBC anterior funcione, **deben existir estos 3 archivos** en la unidad mapeada (o en cualquier unidad de Linux) **con los permisos de los archivos adecuados**:
libirisodbcu35.so
odbcinst.ini
odbc.ini
### **6. Verificar la instalación de PyODBC **
!odbcinst -j
unixODBC 2.3.4
DRIVERS............: /etc/odbcinst.ini
SYSTEM DATA SOURCES: /etc/odbc.ini
FILE DATA SOURCES..: /etc/ODBCDataSources
USER DATA SOURCES..: /root/.odbc.ini
SQLULEN Size.......: 8
SQLLEN Size........: 8
SQLSETPOSIROW Size.: 8
import pyodbc print(pyodbc.drivers())
['InterSystems ODBC35']
Por ahora, las salidas anteriores indicarán que el *driver* ODBC tiene los enlaces válidos. Deberíamos poder ejecutar alguna prueba de ODBC de Python en Jupyter Notebook.
### **7. Ejecutar la conexión ODBC de Python en las muestras de IRIS:**
import pyodbc import time
### 1. Get an ODBC connection
#input("Hit any key to start")
dsn = 'IRIS PyODBC Demo'
server = 'irisimlsvr' #IRIS server container or the docker machine's IP
port = '51773' # or 8091 if docker machine IP is used
database = 'USER'
username = 'SUPERUSER'
password = 'SYS'
#cnxn = pyodbc.connect('DSN='+dsn+';') # use the user DSN defined in odbc.ini, or use the connection string below
cnxn = pyodbc.connect('DRIVER={InterSystems ODBC35};SERVER='+server+';PORT='+port+';DATABASE='+database+';UID='+username+';PWD='+ password)
###ensure it reads strings correctly.
cnxn.setdecoding(pyodbc.SQL_CHAR, encoding='utf8')
cnxn.setdecoding(pyodbc.SQL_WCHAR, encoding='utf8')
cnxn.setencoding(encoding='utf8')
### 2. Get a cursor; start the timer
cursor = cnxn.cursor()
start= time.clock()
### 3. specify the training data, and give a model name
dataTable = 'DataMining.IrisDataset'
dataTablePredict = 'Result12'
dataColumn = 'Species'
dataColumnPredict = "PredictedSpecies"
modelName = "Flower12" #chose a name - must be unique in server end
### 4. Train and predict
#cursor.execute("CREATE MODEL %s PREDICTING (%s) FROM %s" % (modelName, dataColumn, dataTable))
#cursor.execute("TRAIN MODEL %s FROM %s" % (modelName, dataTable))
#cursor.execute("Create Table %s (%s VARCHAR(100), %s VARCHAR(100))" % (dataTablePredict, dataColumnPredict, dataColumn))
#cursor.execute("INSERT INTO %s SELECT TOP 20 PREDICT(%s) AS %s, %s FROM %s" % (dataTablePredict, modelName, dataColumnPredict, dataColumn, dataTable))
#cnxn.commit()
### 5. show the predict result
cursor.execute("SELECT * from %s ORDER BY ID" % dataTable) #or use dataTablePredict result by IntegratedML if you run step 4 above
row = cursor.fetchone()
while row:
print(row)
row = cursor.fetchone()
### 6. CLose and clean
cnxn.close()
end= time.clock()
print ("Total elapsed time: ")
print (end-start)
(1, 1.4, 0.2, 5.1, 3.5, 'Iris-setosa')
(2, 1.4, 0.2, 4.9, 3.0, 'Iris-setosa')
(3, 1.3, 0.2, 4.7, 3.2, 'Iris-setosa')
(4, 1.5, 0.2, 4.6, 3.1, 'Iris-setosa')
(5, 1.4, 0.2, 5.0, 3.6, 'Iris-setosa')
... ...
... ...
... ...
(146, 5.2, 2.3, 6.7, 3.0, 'Iris-virginica')
(147, 5.0, 1.9, 6.3, 2.5, 'Iris-virginica')
(148, 5.2, 2.0, 6.5, 3.0, 'Iris-virginica')
(149, 5.4, 2.3, 6.2, 3.4, 'Iris-virginica')
(150, 5.1, 1.8, 5.9, 3.0, 'Iris-virginica')
Total elapsed time:
0.023873000000000033
Un par de consejos:
1. **cnxn = pyodbc.connect()** - en el entorno Linux, la cadena de conexión expresada en esta llamada debe ser literalmente correcta y sin espacios.
2. Establece la codificación de la conexión correctamente con, por ejemplo, utf8. En este caso, el valor predeterminado no funcionaría para las cadenas.
3. **libirisodbcu35.so** - lo ideal es que este driver esté estrechamente alineado con la versión del servidor IRIS remoto.
## **Siguiente**
Ahora tenemos un entorno Docker con un Jupyter notebook que incluye Python3 y Tensorflow2.2 (sin GPU) a través de una conexión PyODBC (así como JDBC) en un servidor IRIS remoto. Deben funcionar para todas las sintaxis SQL personalizadas, como las que son propiedad de IntegratedML en IRIS, así que ¿por qué no explorar un poco más en IntegratedML y ser creativo con su forma SQL de conducir ciclos de vida ML?
Además, me gustaría que pudiéramos volver a tratar o recapitular el enfoque más sencillo sobre IRIS nativo o incluso Magic SQL en el entorno Python, que se conectará con el servidor IRIS. Y, el extraordinario [Python Gateway](https://github.com/intersystems-community/PythonGateway) está disponible ahora, así que incluso podemos intentar invocar las aplicaciones y servicios externos de Python ML, directamente desde el servidor IRIS. Me gustaría que pudiéramos probar más sobre eso también.
##**Anexo**
El archivo del bloc de notas anterior se revisará en este repositorio de Github, y también en Open Exchange.
Artículo
Ricardo Paiva · 28 ene, 2022
En este artículo, crearemos una configuración de IRIS con alta disponibilidad utilizando implementaciones en Kubernetes con almacenamiento persistente distribuido en vez del "tradicional" par de mirror de IRIS. Esta implementación sería capaz de tolerar fallos relacionados con la infraestructura, por ejemplo, fallos en los nodos, en el almacenamiento y en la Zona de Disponibilidad. El enfoque descrito reduce en gran medida la complejidad de la implementación, a costa de un Tiempo Objetivo de Recuperación (RTO, Recovery Time Objective) ligeramente mayor.
Figura 1: Mirroring tradicional vs Kubernetes con Almacenamiento Distribuido
Todos los códigos fuente utilizados en este artículo están disponibles en https://github.com/antonum/ha-iris-k8s TL;DR
Suponiendo que tienes un clúster de 3 nodos funcionando y que estás un poco familiarizado con Kubernetes, sigue este script:
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
Si no estás seguro de lo que significan las dos líneas anteriores o no tienes el sistema adecuado para ejecutarlas, ve al apartado "Requisitos de alta disponibilidad". Explicaremos las cosas con más detalle conforme avancemos.
La primera línea instala Longhorn, un almacenamiento distribuido de código abierto de Kubernetes. La segunda instala una implementación de InterSystems IRIS, usando un volumen basado en Longhorn para SYS duradero.
Espera hasta que todos los pods estén en funcionamiento. kubectl get pods -A
Ahora deberías tener acceso al Portal de Administración de IRIS en http://<IRIS Service Public IP>:52773/csp/sys/%25CSP.Portal.Home.zen (la contraseña predeterminada es "SYS") y a la línea de comandos de IRIS mediante:
kubectl exec -it iris-podName-xxxx -- iris session iris
Simulación del error
Ahora comenzaremos a jugar un poco. Pero, antes de hacerlo, intenta añadir algunos datos en la base de datos y asegúrate de que siguen allí cuando IRIS esté de nuevo online.
kubectl exec -it iris-6d8896d584-8lzn5 -- iris session iris
USER>set ^k8stest($i(^k8stest))=$zdt($h)_" running on "_$system.INetInfo.LocalHostName()
USER>zw ^k8stest
^k8stest=1
^k8stest(1)="01/14/2021 14:13:19 running on iris-6d8896d584-8lzn5"
Nuestra "ingeniería del caos" empieza aquí:
# Stop IRIS - Container will be restarted automatically
kubectl exec -it iris-6d8896d584-8lzn5 -- iris stop iris quietly
# Delete the pod - Pod will be recreated
kubectl delete pod iris-6d8896d584-8lzn5
# "Force drain" the node, serving the iris pod - Pod would be recreated on another node
kubectl drain aks-agentpool-29845772-vmss000001 --delete-local-data --ignore-daemonsets --force
# Delete the node - Pod would be recreated on another node
# well... you can't really do it with kubectl. Find that instance or VM and KILL it.
# if you have access to the machine - turn off the power or disconnect the network cable. Seriously!
Requisitos de alta disponibilidad
Estamos creando un sistema que pueda tolerar un error en las siguientes estructuras:
Instancia de IRIS dentro del contenedor/máquina virtual IRIS - Nivel del error.
Error en el Pod/Contenedor.
Falta de disponibilidad temporal en el nodo del clúster individual. Un buen ejemplo sería la Zona de Disponibilidad temporalmente off-line.
Error permanente en el nodo o en el disco del clúster individual.
Básicamente, los escenarios que hemos probado en la sección "Simulación del error".
Si se produce alguno de estos errores, el sistema debe ponerse online sin intervención humana y sin pérdida de datos. Técnicamente hay límites sobre qué persistencia de datos garantiza. El propio IRIS puede proporcionarlos basándose en el Ciclo del journal y en el uso de transacciones dentro de una aplicación: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=GCDI_journal#GCDI_journal_writecycle. De cualquier forma, hablamos de menos de dos segundos para el RPO (Recovery Point Objective, "Punto objetivo de recuperación ").
Otros componentes del sistema (el servicio API de Kubernetes, la base de datos del ETCD, el servicio de LoadBalancer, DNS y otros) están fuera de nuestros objetivos y suelen ser gestionados por el Servicio Administrado de Kubernetes, como Azure AKS o AWS EKS, por lo que suponemos que ya tienen una alta disponibilidad.
Otra forma de verlo es que nosotros somos responsables de solucionar los fallos individuales de cálculo y de los componentes de almacenamiento, y asumimos que el resto está a cargo del proveedor de la infraestructura o de la nube.
Arquitectura
Para la alta disponibilidad en InterSystems IRIS, la recomendación habitual es utilizar mirroring. Con mirroring, se tienen dos instancias de IRIS siempre activas, replicando datos de forma sincronizada. Cada nodo mantiene una copia completa de la base de datos y si el nodo primario se cae, los usuarios pueden reconectarse al nodo de backup. Esencialmente, con el enfoque mirroring, IRIS es responsable de la redundancia tanto de cálculo como de almacenamiento.
Con los mirrors en diferentes zonas de disponibilidad, mirroring ofrece la redundancia necesaria tanto para los errores de cálculo como de almacenamiento, y permite un excelente RTO (Tiempo Objetivo de Recuperación o el tiempo que tarda un sistema en volver a estar online después de un fallo) de solo unos cuantos segundos. Aquí podéis acceder a la plantilla de implementación para Mirrored IRIS en la nube de AWS: https://community.intersystems.com/post/intersystems-iris-deployment%C2%A0guide-aws%C2%A0using-cloudformation-template
El lado menos bonito de mirroring es la complejidad de su configuración, la realización de procesos de backup o restauración, y la falta de replicación para las configuraciones de seguridad y los archivos locales que no tienen relación con la base de datos.
Los orquestadores de contenedores como Kubernetes (espera, es 2021... ¡¿queda algún otro?!) proporcionan redundancia de cálculo a través de la implementación de objetos, reiniciando automáticamente el Pod/Contenedor de IRIS en caso de fallo. Por eso solo se ve un nodo de IRIS ejecutándose en el diagrama de arquitectura de Kubernetes. En vez de mantener un segundo nodo de IRIS siempre funcionando, subcontratamos la disponibilidad de cálculo a Kubernetes. Kubernetes se asegurará de que el pod de IRIS sea recreado en caso de que el pod original falle por cualquier razón.
Figura 2. Escenario de la tolerancia a fallos
Por ahora todo va bien… Si el nodo de IRIS falla, Kubernetes simplemente crea uno nuevo. Dependiendo del clúster, se necesitan entre 10 y 90 segundos para que IRIS se vuelva a conectar después del fallo de cálculo. Esto es un paso atrás comparado con el par de segundos del mirroring, pero es algo que se puede tolerar en el improbable caso de que haya una interrupción; y la recompensa es la gran reducción de la complejidad. No hay mirroring para configurar. No hay que preocuparse por la configuración de seguridad ni por la replicación de los archivos.
Francamente, si inicias sesión dentro del contenedor, ejecutando IRIS en Kubernetes, ni siquiera notarás que se está ejecutando dentro del entorno de alta disponibilidad. Todo se ve y parece como una sencilla instancia de implementación en IRIS.
Espera... ¿qué pasa con el almacenamiento? Al final, estamos lidiando con una base de datos… Sea cual sea el escenario de respuesta ante fallos que podamos imaginar, nuestro sistema debería encargarse también de la persistencia de los datos. Mirroring depende del cálculo, a nivel local en el nodo de IRIS. Si el nodo se vuelve no operativo o simplemente deja de estar disponible temporalmente, también lo hace el almacenamiento de ese nodo. Por eso en la configuración de mirroring, IRIS se encarga de replicar bases de datos a nivel de IRIS.
Necesitamos un almacenamiento que no solo pueda preservar el estado de la base de datos al reiniciar el contenedor, sino que también pueda proporcionar redundancia en caso de que un nodo o un segmento entero de la red (Zona de Disponibilidad) se caiga. Hasta hace unos años, no había una respuesta fácil para esto. Como puedes adivinar por la imagen anterior, ya tenemos esa respuesta. Se llama almacenamiento distribuido en contenedores.
El almacenamiento distribuido extrae los volúmenes del host y los presenta como un almacenamiento conjunto disponible para cada nodo del clúster K8s. En este artículo utilizamos Longhorn https://longhorn.io - es gratuito, de código abierto y bastante fácil de instalar. Pero también puedes echar un vistazo a otros programas, como OpenEBS, Portworx y StorageOS, que ofrecen la misma funcionalidad. Rook Ceph es otro proyecto de incubación del CNCF a tener en cuenta. La gama alta de las opciones serían las soluciones de almacenamiento empresarial, como NetApp, PureStorage y otras.
Guía paso a paso
En la sección TL;DR acabamos de instalar todo de una sola vez. El Anexo B te dirigirá paso a paso en los procesos de instalación y validación.
Almacenamiento de Kubernetes
Vamos a ir hacia atrás un momento y vamos a hablar de los contenedores y el almacenamiento en general y de cómo IRIS se integra en todo esto.
De forma predeterminada, todos los datos dentro del contenedor son efímeros. Cuando el contenedor se borra, los datos desaparecen. Para tener almacenamiento persistente en Docker y que no se elimine la información al borrar el contenedor, es necesario utilizar "volúmenes de datos". Básicamente, permite mostrar al contenedor el directorio que se encuentra en el sistema operativo del host.
docker run --detach
--publish 52773:52773
--volume /data/dur:/dur
--env ISC_DATA_DIRECTORY=/dur/iconfig
--name iris21 --init intersystems/iris:2020.3.0.221.0
En el ejemplo anterior, iniciamos el contenedor IRIS y hacemos que el directorio local del host "/data/dur" sea accesible al contenedor en el punto de montaje "/dur". Por lo tanto, si el contenedor está almacenando algo dentro de este directorio, se conservará y estará disponible para su uso cuando inicie de nuevo el contenedor.
Desde el punto de vista de IRIS, podemos dar indicaciones a IRIS para que almacene en el directorio específico todos los datos que necesita conservar cuando reinicie el contenedor, especificando ISC_DATA_DIRECTORY. Durable SYS es el nombre de la función de IRIS que podrías necesitar buscar en la documentación: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_durable_running
En Kubernetes la sintaxis es diferente, pero los conceptos son los mismos.
Esta es la implementación básica de Kubernetes para IRIS.
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
En la implementación de la especificación anterior, la parte "volúmenes" lista los volúmenes de almacenamiento. Pueden estar disponibles fuera del contenedor, por medio de persistentVolumeClaim como "iris-pvc". volumeMounts muestra este volumen dentro del contenedor. "iris-external-sys" es el identificador que vincula el montaje del volumen con el volumen específico. En realidad, podemos tener varios volúmenes y este nombre se utiliza solo para distinguir uno de otro. Si quieres, puedes llamarlo "Steve".
La ya conocida variable de entorno ISC_DATA_DIRECTORY dirige a IRIS para que utilice un punto de montaje específico para almacenar todos los datos que necesiten conservarse tras el reinicio del contenedor.
Ahora, echemos un vistazo a la reclamación de volúmenes persistente iris-pvc.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iris-pvc
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
Es bastante sencillo. Se solicitan 10 gigabytes, montables como lectura/escritura en un solo nodo, utilizando la clase de almacenamiento de "longhorn".
La clase storageClassName: longhorn es realmente crítica aquí.
Veamos qué clases de almacenamiento están disponibles en mi clúster AKS:
kubectl get StorageClass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile kubernetes.io/azure-file Delete Immediate true 10d
azurefile-premium kubernetes.io/azure-file Delete Immediate true 10d
default (default) kubernetes.io/azure-disk Delete Immediate true 10d
longhorn driver.longhorn.io Delete Immediate true 10d
managed-premium kubernetes.io/azure-disk Delete Immediate true 10d
Hay algunas clases de almacenamiento en Azure, instaladas de forma predeterminada, y una en Longhorn que instalamos como parte del primer comando:
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
Si omites #storageClassName: longhorn en la definición de la reclamación de volúmenes persistente, utilizará la clase de almacenamiento, actualmente marcada como "predeterminada", la cual es un disco normal de Azure.
Para ilustrar por qué necesitamos el almacenamiento distribuido, vamos a repetir los experimentos de "ingeniería del caos" que describimos al principio del artículo sin el almacenamiento de Longhorn. Los dos primeros escenarios (parar IRIS y eliminar el Pod) se completarían correctamente y los sistemas volverían al estado operativo. Intentar vaciar o eliminar el nodo llevaría al sistema a un estado de error.
#forcefully drain the node
kubectl drain aks-agentpool-71521505-vmss000001 --delete-local-data --ignore-daemonsets
kubectl describe pods
...
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 57s (x9 over 2m41s) default-scheduler 0/3 nodes are available: 1 node(s) were unschedulable, 2 node(s) had volume node affinity conflict.
Esencialmente, Kubernetes intentaría reiniciar el pod de IRIS en el clúster, pero el nodo donde se inició originalmente no está disponible y los otros dos nodos tienen un "conflicto de afinidad con el nodo del volumen". Con este tipo de almacenamiento, el volumen está disponible solo en el nodo que se creó originalmente, ya que básicamente está vinculado al disco disponible en el host del nodo.
Con Longhorn como clase de almacenamiento, tanto los experimentos "forzar el vaciado" como "eliminar el nodo" tuvieron éxito, y el pod de IRIS vuelve a funcionar en poco tiempo. Para lograrlo, Longhorn toma el control sobre el almacenamiento disponible en los 3 nodos del clúster y replica los datos a través de los tres nodos. Longhorn repara rápidamente el almacenamiento del clúster si uno de los nodos deja de estar disponible de forma permanente. En nuestro escenario “eliminar el nodo”, el pod de IRIS se reinicia inmediatamente en otro nodo usando dos réplicas restantes del volumen. A continuación, AKS proporciona un nuevo nodo para sustituir el que perdió y tan pronto como esté listo Longhorn entra en acción y reconstruye los datos necesarios en el nuevo nodo. Todo es automático, no necesita tu participación.
Figura 3. Longhorn reconstruyendo el volumen de la replicación en el nodo reemplazado
Más información sobre la implementación de K8s
Echemos un vistazo a algunos otros aspectos de nuestra implementación:
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
- name: ISC_CPF_MERGE_FILE
value: /external/merge/merge.cpf
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
- name: cpf-merge
mountPath: /external/merge
livenessProbe:
initialDelaySeconds: 25
periodSeconds: 10
exec:
command:
- /bin/sh
- -c
- "iris qlist iris | grep running"
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
- name: cpf-merge
configMap:
name: iris-cpf-merge
Estrategia: Recreate, replicas: 1 le dice a Kubernetes que en cualquier momento debe mantener una y exactamente una instancia del pod de IRIS en ejecución. Esto es de lo que se encarga nuestro escenario "eliminar el pod".
livenessProbe. Esta sección se asegura de que IRIS siempre esté dentro del contenedor y gestione el escenario "IRIS se ha caído". initialDelaySeconds permite un cierto periodo de gracia para que IRIS comience. Es posible que quieras aumentarlo si IRIS está tardando mucho tiempo en iniciar tu implementación.
CPF MERGE es una función de IRIS que te permite modificar el contenido del archivo de configuración iris.cpf al iniciar el contenedor. Consulta https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=RACS_cpf#RACS_cpf_edit_merge para más información. En este ejemplo estoy usando Kubernetes Config Map para administrar el contenido del archivo merge: https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml Aquí ajustamos los buffers globales y los valores de gmheap, utilizados por la instancia de IRIS, pero todo lo que puedes encontrar en el archivo iris.cpf es posible. Incluso puedes cambiar la contraseña predeterminada de IRIS usando el campo "PasswordHash" en el archivo CPF Merge. Más información en: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_images_password_auth
Además de la reclamación de volúmenes persistente https://github.com/antonum/ha-iris-k8s/blob/main/iris-pvc.yaml, implementación https://github.com/antonum/ha-iris-k8s/blob/main/iris-deployment.yaml y ConfigMap con contenido de CPF Merge https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml, nuestra puesta en marcha necesita un servicio que exponga la implementación de IRIS en el internet público: https://github.com/antonum/ha-iris-k8s/blob/main/iris-svc.yaml
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.18.169 40.88.123.45 52773:31589/TCP 3d1h
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 10d
La IP externa del iris-svc se puede utilizar para acceder al Portal de administración de IRIS a través de: http://40.88.123.45:52773/csp/sys/%25CSP.Portal.Home.zen. La contraseña predeterminada es "SYS".
Copia de seguridad/restauración y escalado del almacenamiento
Longhorn ofrece una interfaz de usuario basada en la web para configurar y administrar los volúmenes.
Identifica el pod, ejecutando el componente longhorn-ui y establece el reenvío de puertos con kubectl:
kubectl -n longhorn-system get pods
# note the longhorn-ui pod id.
kubectl port-forward longhorn-ui-df95bdf85-gpnjv 9000:8000 -n longhorn-system
La interfaz de usuario de Longhorn estará disponible en: http://localhost:9000
Figura 4. Interfaz de usuario de Longhorn
Además de la alta disponibilidad, la mayoría de las soluciones de almacenamiento para contenedores y Kubernetes ofrecen opciones útiles para copias de seguridad, snapshots y recuperación. Los detalles son específicos de la implementación, pero lo habitual es que la copia de seguridad esté asociada con VolumeSnapshot. Así es para Longhorn. Dependiendo de tu versión de Kubernetes y de tu proveedor, es posible que también necesites instalar el volumen de snapshotter https://github.com/kubernetes-csi/external-snapshotter
"iris-volume-snapshot.yaml" es un ejemplo de ese snapshot de volumen. Antes de utilizarlo, es necesario configurar las copias de seguridad en el bucket S3 o en el volumen del sistema de archivos de red (NFS) en Longhorn. https://longhorn.io/docs/1.0.1/snapshots-and-backups/backup-and-restore/set-backup-target/
# Take crash-consistent backup of the iris volume
kubectl apply -f iris-volume-snapshot.yaml
En el caso de IRIS, se recomienda ejecutar Freeze externo antes de tomar la copia de seguridad/snapshot y después Thaw. Consulta los detalles aquí: https://docs.intersystems.com/irisforhealthlatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=Backup.General#ExternalFreeze
Para aumentar el tamaño del volumen de IRIS - Ajusta la solicitud de almacenamiento en la reclamación de volúmenes persistente (archivo "iris-pvc.yaml"), utilizada por IRIS.
...
resources:
requests:
storage: 10Gi #change this value to required
A continuación, vuelve a aplicar la especificación de la reclamación de volúmenes persistente (PVC). Longhorn no puede aplicar este cambio mientras el volumen esté conectado al pod que está en ejecución. Cambia temporalmente el recuento de réplicas hasta cero en la implementación, para poder aumentar el tamaño del volumen.
Alta disponibilidad: Resumen
Al principio del artículo, establecimos algunos criterios para la alta disponibilidad. Esto es lo que logramos con esta arquitectura:
Dominio de fallos
Mitigados automáticamente por
Instancia de IRIS dentro del contenedor/máquina virtual. IRIS: Nivel del fallo
La implementación Liveness probe reinicia el contenedor en caso de que IRIS no funcione
Fallo en el Pod/Contenedor.
La implementación recrea el Pod
Falta de disponibilidad temporal en el nodo del clúster individual. Un buen ejemplo sería la Zona de disponibilidad que está off-line.
La implementación recrea el pod en otro nodo. Longhorn hace que los datos estén disponibles en otro nodo.
Fallo permanente en el nodo o en el disco del clúster individual.
Igual que lo expuesto anteriormente + el autoescalador del clúster K8s sustituye un nodo dañado por uno nuevo. Longhorn reconstruye los datos en el nuevo nodo.
Zombis y otras cosas a tener en cuenta
Si estás familiarizado con la ejecución de IRIS en los contenedores Docker, es posible que hayas utilizado la marca "--init".
docker run --rm -p 52773:52773 --init store/intersystems/iris-community:2020.4.0.524.0
El objetivo de esta marca es evitar la formación de los "procesos zombis". En Kubernetes, puedes utilizar o bien "shareProcessNamespace: true" (se aplican consideraciones de seguridad) o utilizar "tini" en tus propios contenedores. Ejemplo de Dockerfile con tini:
FROM iris-community:2020.4.0.524.0
...
# Add Tini
USER root
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
USER irisowner
ENTRYPOINT ["/tini", "--", "/iris-main"]
A partir de 2021, todas las imágenes de contenedores proporcionadas por InterSystems incluirán tini de forma predeterminada.
Puedes reducir aún más el tiempo de tolerancia a fallos para los escenarios de "forzar el vaciado del nodo/eliminar el nodo" ajustando algunos parámetros:
Política para eliminar Pods de Longhorn https://longhorn.io/docs/1.1.0/references/settings/#pod-deletion-policy-when-node-is-down y desalojo basado en imperfecciones de Kubernetes: https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/#taint-based-evictions
Descargo de responsabilidad
Como empleado de InterSystems, tengo que poner esto aquí: Longhorn se utiliza en este artículo como un ejemplo de almacenamiento en bloque distribuido para Kubernetes. InterSystems no valida ni emite ninguna afirmación de soporte oficial para soluciones o productos de almacenamiento individual. Necesitas probar y validar si alguna solución de almacenamiento específica se ajusta a tus necesidades.
El almacenamiento distribuido también puede tener características de rendimiento sustancialmente diferentes, en comparación con el almacenamiento local de los nodos. Especialmente para las operaciones de escritura, en las que los datos deben escribirse en varias ubicaciones antes de que se considere que están en el estado persistente. Asegúrate de probar tus cargas de trabajo y entender el comportamiento específico y las opciones que ofrece tu controlador CSI.
Básicamente, InterSystems no valida ni respalda soluciones de almacenamiento específicas como Longhorn, de la misma manera que no validamos marcas individuales de discos duros o fabricantes de hardware para servidores. Personalmente, Longhorn me pareció fácil de utilizar y su equipo de desarrollo, extremadamente atentos y amables en la página de proyectos de GitHub. https://github.com/longhorn/longhorn
Conclusiones
El ecosistema de Kubernetes ha evolucionado significativamente en los últimos años y con el uso de soluciones de almacenamiento en bloque distribuido, ahora se puede construir una configuración de alta disponibilidad que puede sostener la instancia de IRIS, el nodo del clúster e incluso los errores en la zona de disponibilidad.
Puedes subcontratar el cálculo y la alta disponibilidad del almacenamiento para los componentes de Kubernetes, lo que resulta en un sistema significativamente más sencillo de configurar y mantener, comparado con el mirroring tradicional de IRIS. Al mismo tiempo, esta configuración podría no proporcionar el mismo RTO y rendimiento de almacenamiento que la configuración mirrored.
En este artículo, creamos una configuración IRIS de alta disponibilidad utilizando Azure AKS como sistema de almacenamiento distribuido administrado por Kubernetes y Longhorn. Puedes explorar varias alternativas como AWS EKS, Google Kubernetes Engine, StorageOS, Portworx y OpenEBS como almacenamiento distribuido en contenedores o incluso soluciones de almacenamiento a nivel empresarial como NetApp, PureStorage, Dell EMC y otros.
Anexo A. Cómo crear un clúster de Kubernetes en la nube
El servicio de Kubernetes administrado de uno de los proveedores de nube pública es una forma sencilla de crear el clúster K8s necesario para esta configuración. La configuración predeterminada en AKS de Azure está lista para ser utilizada en la implementación descrita en este artículo.
Crea un nuevo clúster AKS con 3 nodos. Deja todo lo demás de forma predeterminada.
Figura 5. Crear un clúster AKS
Instala kubectl en tu equipo de forma local: https://kubernetes.io/docs/tasks/tools/install-kubectl/
Registra tu clúster de AKS con kubectl local
Figura 6. Registrar el clúster de AKS con kubectl
Después, puedes volver al principio del artículo e instalar Longhorn y la implementación de IRIS.
La instalación en AWS EKS es un poco más complicada. Debes asegurarte de que todas las instancias de tu grupo de nodos tengan instalado open-iscsi.
sudo yum install iscsi-initiator-utils -y
Instalar Longhorn en GKE requiere de un paso adicional, descrito aquí: https://longhorn.io/docs/1.0.1/advanced-resources/os-distro-specific/csi-on-gke/
Anexo B. Instalación paso a paso
Paso 1: Clúster de Kubernetes y kubectl
Necesitas 3 nodos del clúster K8s. En el Anexo A se describe cómo obtener uno en Azure.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-29845772-vmss000000 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000001 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000002 Ready agent 10d v1.18.10
Paso 2: Instalar Longhorn
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
Asegúrate de que todos los pods del namespace ‘longhorn-system’ estén funcionando. Podría tardar unos minutos.
$ kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
csi-attacher-74db7cf6d9-jgdxq 1/1 Running 0 10d
csi-attacher-74db7cf6d9-l99fs 1/1 Running 1 11d
...
longhorn-manager-flljf 1/1 Running 2 11d
longhorn-manager-x76n2 1/1 Running 1 11d
longhorn-ui-df95bdf85-gpnjv 1/1 Running 0 11d
Consulta la guía de instalación de Longhorn para más detalles y resolución de problemas https://longhorn.io/docs/1.1.0/deploy/install/install-with-kubectl
Paso 3: Clonar el repositorio de GitHub
$ git clone https://github.com/antonum/ha-iris-k8s.git
$ cd ha-iris-k8s
$ ls
LICENSE iris-deployment.yaml iris-volume-snapshot.yaml
README.md iris-pvc.yaml longhorn-aws-secret.yaml
iris-cpf-merge.yaml iris-svc.yaml tldr.yaml
Paso 4: Implementar y validar componentes uno por uno
El archivo tldr.yaml contiene todos los componentes necesarios para la implementación en un solo paquete. Aquí los instalaremos uno por uno y validaremos la configuración de cada uno de ellos de forma individual.
# If you have previously applied tldr.yaml - delete it.
$ kubectl delete -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
# Create Persistent Volume Claim
$ kubectl apply -f iris-pvc.yaml
persistentvolumeclaim/iris-pvc created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
iris-pvc Bound pvc-fbfaf5cf-7a75-4073-862e-09f8fd190e49 10Gi RWO longhorn 10s
# Create Config Map
$ kubectl apply -f iris-cpf-merge.yaml
$ kubectl describe cm iris-cpf-merge
Name: iris-cpf-merge
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
merge.cpf:
----
[config]
globals=0,0,800,0,0,0
gmheap=256000
Events: <none>
# create iris deployment
$ kubectl apply -f iris-deployment.yaml
deployment.apps/iris created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
iris-65dcfd9f97-v2rwn 0/1 ContainerCreating 0 11s
# note the pod name. You’ll use it to connect to the pod in the next command
$ kubectl exec -it iris-65dcfd9f97-v2rwn -- bash
irisowner@iris-65dcfd9f97-v2rwn:~$ iris session iris
Node: iris-65dcfd9f97-v2rwn, Instance: IRIS
USER>w $zv
IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2020.4 (Build 524U) Thu Oct 22 2020 13:04:25 EDT
# h<enter> to exit IRIS shell
# exit<enter> to exit pod
# access the logs of the IRIS container
$ kubectl logs iris-65dcfd9f97-v2rwn
...
[INFO] ...started InterSystems IRIS instance IRIS
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Private webserver started on 52773
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Processing Shadows section (this system as shadow)
01/18/21-23:09:11:321 (1173) 0 [Utility.Event] Processing Monitor section
01/18/21-23:09:11:381 (1323) 0 [Utility.Event] Starting TASKMGR
01/18/21-23:09:11:392 (1324) 0 [Utility.Event] [SYSTEM MONITOR] System Monitor started in %SYS
01/18/21-23:09:11:399 (1173) 0 [Utility.Event] Shard license: 0
01/18/21-23:09:11:778 (1162) 0 [Database.SparseDBExpansion] Expanding capacity of sparse database /external/iris/mgr/iristemp/ by 10 MB.
# create iris service
$ kubectl apply -f iris-svc.yaml
service/iris-svc created
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.214.236 20.62.241.89 52773:30128/TCP 15s
Paso 5: Acceso al Portal de administración
Por último: Conéctate al Portal de administración de IRIS, utilizando la IP externa del servicio http://20.62.241.89:52773/csp/sys/%25CSP.Portal.Home.zen username _SYSTEM, Password SYS. Se te pedirá que la cambies cuando inicies sesión por primera vez.
Este artículo está etiquetado como "Mejores prácticas" ("Best practices").
Los artículos con la etiqueta "Mejores prácticas" incluyen recomendaciones sobre cómo desarrollar, probar, implementar y administrar mejor las soluciones de InterSystems